准确率(accuracy)
分类模型预测准确的比例。在多类别分类中,准确率定义如下:
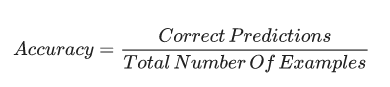
在二分类中,准确率定义为:
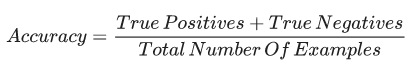
激活函数(Activation function)
一种函数(例如 ReLU 或 Sigmoid),将前一层所有神经元激活值的加权和输入到一个非线性函数中,然后向下一层传递该函数的输出值(典型的非线性)。
AdaGrad
一种复杂的梯度下降算法,重新调节每个参数的梯度,高效地给每个参数一个单独的学习率。详见论文:http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf。
AUC(曲线下面积)
一种考虑到所有可能的分类阈值的评估标准。ROC 曲线下面积代表分类器随机预测真正类(Ture Positives)要比假正类(False Positives)概率大的确信度。
B
反向传播(Backpropagation)
神经网络中完成梯度下降的重要算法。首先,在前向传播的过程中计算每个节点的输出值。然后,在反向传播的过程中计算与每个参数对应的误差的偏导数。
基线(Baseline)
被用为对比模型表现参考点的简单模型。基线帮助模型开发者量化模型在特定问题上的预期表现。
批量
模型训练中一个迭代(指一次梯度更新)使用的样本集。
批量大小(batch size)
一个批量中样本的数量。例如,SGD 的批量大小为 1,而 mini-batch 的批量大小通常在 10-1000 之间。批量大小通常在训练与推理的过程中确定,然而 TensorFlow 不允许动态批量大小。
偏置(bias)
与原点的截距或偏移量。偏置(也称偏置项)被称为机器学习模型中的 b 或者 w0。例如,偏置项是以下公式中的 b:y′=b+w_1x_1+w_2x_2+…w_nx_n。
注意不要和预测偏差混淆。
二元分类器(binary classification)
一类分类任务,输出两个互斥(不相交)类别中的一个。例如,一个评估邮件信息并输出「垃圾邮件」或「非垃圾邮件」的机器学习模型就是一个二元分类器。
binning/bucketing
根据值的范围将一个连续特征转换成多个称为 buckets 或者 bins 二元特征,称为 buckets 或者 bins。例如,将温度表示为单一的浮点特征,可以将温度范围切割为几个离散的 bins。假如给定的温度的敏感度为十分之一度,那么分布在 0.0 度和 15.0 度之间的温度可以放入一个 bin 中,15.1 度到 30.0 度放入第二个 bin,30.1 度到 45.0 度放入第三个 bin。
C
标定层(calibration layer)
一种调整后期预测的结构,通常用于解释预测偏差。调整后的预期和概率必须匹配一个观察标签集的分布。
候选采样(candidate sampling)
一种优化训练时间的,使用 Softmax 等算法计算所有正标签的概率,同时只计算一些随机取样的负标签的概率。例如,有一个样本标记为「小猎兔狗」和「狗」,候选取样将计算预测概率,和与「小猎兔狗」和「狗」类别输出(以及剩余的类别的随机子集,比如「猫」、「棒棒糖」、「栅栏」)相关的损失项。这个想法的思路是,负类别可以通过频率更低的负强化(negative reinforcement)进行学习,而正类别经常能得到适当的正强化,实际观察确实如此。候选取样的动力是计算有效性从所有负类别的非计算预测的得益。
检查点(checkpoint)
在特定的时刻标记模型的变量的状态的数据。检查点允许输出模型的权重,也允许通过多个阶段训练模型。检查点还允许跳过错误继续进行(例如,抢占作业)。注意其自身的图式并不包含于检查点内。
类别(class)
所有同类属性的目标值作为一个标签。例如,在一个检测垃圾邮件的二元分类模型中,这两个类别分别是垃圾邮件和非垃圾邮件。而一个多类别分类模型将区分狗的种类,其中的类别可以是贵宾狗、小猎兔狗、哈巴狗等等。
类别不平衡数据集(class-imbalanced data set)
这是一个二元分类问题,其中两个类别的标签的分布频率有很大的差异。比如,一个疾病数据集中若 0.01% 的样本有正标签,而 99.99% 的样本有负标签,那么这就是一个类别不平衡数据集。但对于一个足球比赛预测器数据集,若其中 51% 的样本标记一队胜利,而 49% 的样本标记其它队伍胜利,那么这就不是一个类别不平衡数据集。
分类模型(classification)
机器学习模型的一种,将数据分离为两个或多个离散类别。例如,一个自然语言处理分类模型可以将一句话归类为法语、西班牙语或意大利语。分类模型与回归模型(regression model)成对比。
分类阈值(classification threshold)
应用于模型的预测分数以分离正类别和负类别的一种标量值标准。当需要将 logistic 回归的结果映射到二元分类模型中时就需要使用分类阈值。例如,考虑一个确定给定邮件为垃圾邮件的概率的 logistic 回归模型,如果分类阈值是 0.9,那么 logistic 回归值在 0.9 以上的被归为垃圾邮件,而在 0.9 以下的被归为非垃圾邮件。
混淆矩阵(confusion matrix)
总结分类模型的预测结果的表现水平(即,标签和模型分类的匹配程度)的 NxN 表格。混淆矩阵的一个轴列出模型预测的标签,另一个轴列出实际的标签。N 表示类别的数量。在一个二元分类模型中,N=2。例如,以下为一个二元分类问题的简单的混淆矩阵:

上述混淆矩阵展示了在 19 个确实为肿瘤的样本中,有 18 个被模型正确的归类(18 个真正),有 1 个被错误的归类为非肿瘤(1 个假负类)。类似的,在 458 个确实为非肿瘤的样本中,有 452 个被模型正确的归类(452 个真负类),有 6 个被错误的归类(6 个假正类)。
多类别分类的混淆矩阵可以帮助发现错误出现的模式。例如,一个混淆矩阵揭示了一个识别手写数字体的模型倾向于将 4 识别为 9,或者将 7 识别为 1。混淆矩阵包含了足够多的信息可以计算很多的模型表现度量,比如精度(precision)和召回(recall)率。
连续特征(continuous feature)
拥有无限个取值点的浮点特征。和离散特征(discrete feature)相反。
收敛(convergence)
训练过程达到的某种状态,其中训练损失和验证损失在经过了确定的迭代次数后,在每一次迭代中,改变很小或完全不变。换句话说就是,当对当前数据继续训练而无法再提升模型的表现水平的时候,就称模型已经收敛。在深度学习中,损失值下降之前,有时候经过多次迭代仍保持常量或者接近常量,会造成模型已经收敛的错觉。
凸函数(concex function)
一种形状大致呈字母 U 形或碗形的函数。然而,在退化情形中,凸函数的形状就像一条线。例如,以下几个函数都是凸函数:
-
L2 损失函数
-
Log 损失函数
-
L1 正则化函数
-
L2 正则化函数
凸函数是很常用的损失函数。因为当一个函数有最小值的时候(通常就是这样),梯度下降的各种变化都能保证找到接近函数最小值的点。类似的,随机梯度下降的各种变化有很大的概率(虽然无法保证)找到接近函数最小值的点。
两个凸函数相加(比如,L2 损失函数+L1 正则化函数)后仍然是凸函数。
深度模型通常是非凸的。出乎意料的是,以凸优化的形式设计的算法通常都能在深度网络上工作的很好,虽然很少能找到最小值。
成本(cost)
loss 的同义词。
交叉熵(cross-entropy)
多类别分类问题中对 Log 损失函数的推广。交叉熵量化两个概率分布之间的区别。参见困惑度(perplexity)。
D
数据集(data set)
样本的集合。
决策边界(decision boundary)
在一个二元分类或多类别分类问题中模型学习的类别之间的分离器。例如,下图就展示了一个二元分类问题,决策边界即橙点类和蓝点类的边界。

深度模型(deep model)
一种包含多个隐藏层的神经网络。深度模型依赖于其可训练的非线性性质。和宽度模型对照(wide model)。
密集特征(dense feature)
大多数取值为非零的一种特征,通常用取浮点值的张量(tensor)表示。和稀疏特征(sparse feature)相反。
派生特征(derived feature)
合成特征(synthetic feature)的同义词。
离散特征(discrete feature)
只有有限个可能取值的一种特征。例如,一个取值只包括动物、蔬菜或矿物的特征就是离散(或类别)特征。和连续特征(continuous feature)对照。
dropout 正则化(dropout regularization)
训练神经网络时一种有用的正则化方法。dropout 正则化的过程是在单次梯度计算中删去一层网络中随机选取的固定数量的单元。删去的单元越多,正则化越强。
动态模型(dynamic model)
以连续更新的方式在线训练的模型。即数据连续不断的输入模型。
E
早期停止法(early stopping)
一种正则化方法,在训练损失完成下降之前停止模型训练过程。当验证数据集(validation data set)的损失开始上升的时候,即泛化表现变差的时候,就该使用早期停止法了。
嵌入(embeddings)
一类表示为连续值特征的明确的特征。嵌入通常指将高维向量转换到低维空间中。例如,将一个英语句子中的单词以以下任何一种方式表示:
在 TensorFlow 中,嵌入是通过反向传播损失训练的,正如神经网络的其它参量一样。
经验风险最小化(empirical risk minimization,ERM)
选择能最小化训练数据的损失的模型函数的过程。和结构风险最小化(structual risk minimization)对照。
集成(ensemble)
多个模型预测的综合考虑。可以通过以下一种或几种方法创建一个集成方法:
-
设置不同的初始化;
-
设置不同的超参量;
-
设置不同的总体结构。







