AI 科技评论按:Facebook今天在研究blog上发布了一篇文章,介绍了自己的超大规模图分区优化算法SHP。这是 Facebook 为了处理自己的规模过大的图分区问题开发的方法,而且在大规模优化问题中确实发挥了作用。这项研究的论文也已经被数据库领域著名国际会议 VLDB 2017(Very Large Data Bases)收录。AI 科技评论把这篇介绍文章编译如下。
对Facebook来说,每天它要服务的用户是十亿级别的。为了支持这种规模的访问量,Facebook 需要在许多个不同的层次上设计分布式的负载。Facebook 在全球建立了多个数据中心来提升用户访问的可靠性、容错性,以及改善延迟。不过单个托管服务器的容量和计算资源总是有限的,Facebook 的存储系统需要在多个托管服务器之间共享数据,批量计算任务也需要在上千个工作站形成的集群上运行,以便提升计算规模、加快计算速度。
这些系统的核心是一系列小安排,就是决定如何把请求、数据条目、计算任务等等任务元素分配给数据中心、托管服务器或者工作站等等计算小组中的某一个。能够分配任务的方法有无数种,但是不同的分配方法带来的响应时间和服务质量可谓天差地别。
要考虑的第一个方面就是负载平衡:如果某一个计算小组已经过载了,它就没办法达到原定的响应时间或者服务水平。对于给定的负载分布,总还有进一步优化的潜力,因为很多的事情在同一处做的效果都比分开做的效果更好。比如把两个经常需要同时访问的数据放在同一个存储托管服务器上就能够提升会用到这些数据的查询性能。
平衡图分区(balanced graph partitioning)就提供了一种有用的方法来处理任务背后的工作量分配问题。在这种方法中,图里的节点会被分给多个“bucket”中的一个,代表着计算项目会被平衡地分配给多个计算小组中的一个,整个过程中还持续对任务的某些特征进行优化,比如单个小组内的任务相似性。以前Facebook就在文章中介绍过他们如何用平衡图分区的方法达到了前所未有的系统表现,在他们的新论文「Social Hash Partitioner: A Scalable Distributed Hypergraph Partitioner」中,Facebook 介绍了一种分区二分图的新方法,它能够让扇出(fan-out)最小化。这种新方法在Facebook的许多分布式负载优化任务中都发挥了效果。Facebook 把基于这种方法形成的框架称作 Social Hash Partitioner (SHP),因为它可以作为之前 Facebook NSDI 2016论文中的 Social Hash 框架的超图分区组件。
以下对 SHP 的亮点作逐一介绍
减少扇出
Facebook 研究员们研究如何减少扇出问题的起源就是分布式数据集中经常出现的碎片化问题。假设有这样一个情况,一个很大的数据集,其中的数据记录分布在许多个数据服务器上。对数据集的一次查询可能会用到好几条数据记录,如果这些数据记录分散在好几个服务器上,那么就需要给这每一个服务器都发送查询才能够应答原来的查询。这样一来,把数据记录分配给不同的服务器的方式就决定了处理一个查询的时候需要发起的新查询的数目;这个数字就被称作这次查询的“扇出 fan-out”。扇出低的查询就可以执行得更快,因为过程中需要与一个较慢的服务器沟通的可能性更低,而且也通过减少沟通计算量的方式降低了整个系统的负载。所以,一种常见的优化目标就是为数据集选择一种数据分配方法,让不同的查询所需要的数据直接存放在同一个地方。
图1就给出了分别用生成的访问请求和真实的请求测试后的系统表现。
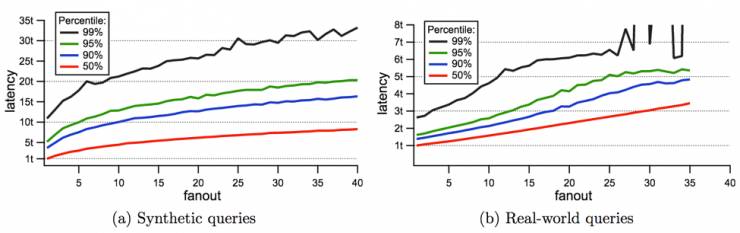
图1
在图中,纵坐标t代表了系统的平均延迟。可以看到高扇出的请求承受的延迟也更高。具体来说,40左右就是很高的扇出值了,如果降低到10,这个查询的延迟就可以达到平均值。
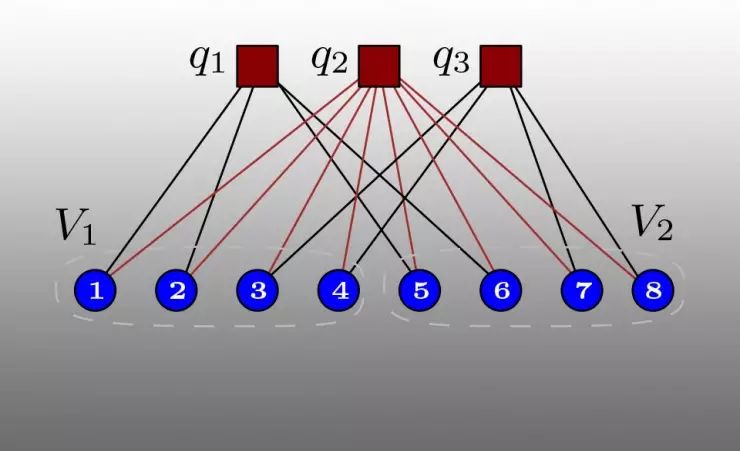
碎片化存储问题可以建模为一个二分图分区问题。图2中,数据条目和需要访问它们的查询被表示为二分图中的顶点,然后要把数据分为k个组;分的过程中每个组要分到近似的数据量,而且每个查询需要连接到的不同的组数目的平均值要越小越好。
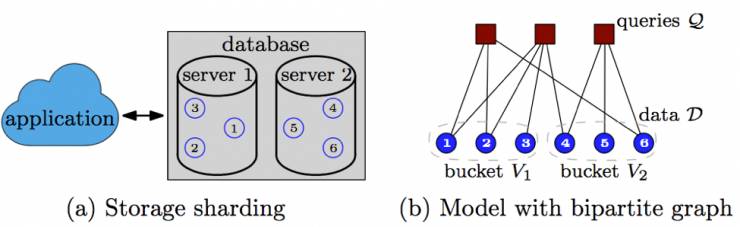
图2
找到低扇出的分区
找到一个图的优化分区往往是一个很难计算的问题。一种典型的启发式方法是从一些初始的平衡分区开始,在一个迭代过程中对某些顶点的分配做局部小调整,逐渐提高分组的效果。在每轮迭代中,每一个顶点都会估计把自己换到其它分组里面去的偏好,这个称作“收益 gain”。如果新的收益比目前分配方式的收益高,就可以尝试在保持总体负载平衡的情况下把这个顶点移到另一个组里面去。
不过,这个方法用在扇出优化里面的效果很不好,图3中就是一种出现问题的情形,图中标出的V1和V2分别在两个组之中。
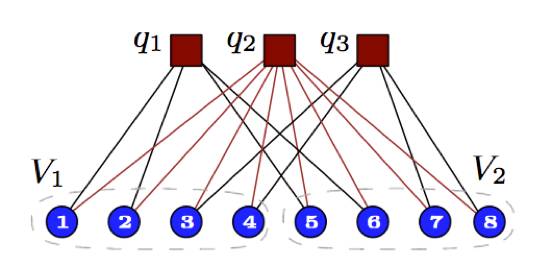
图3
每个查询 (q1, q2, q3) 都刚好访问了两个分组,所以平均扇出就是2。但这并不是最优分组,因为如果把顶点3、4和5、6交换位置的话就会把q1和q2查询的扇出降低为1,平均扇出就会降低为1.33。然而,从每一个顶点自己的角度看来,把自己更换到另一个分组里面去并不会有更高的收益,所以需要用到这个节点的扇出就不会得到任何优化。
Facebook 的新研究改善了这种状况,他们把优化目标变得“平滑”:不再假设一个查询需要求出所有所需数据的扇出,而假设它会以一个概率p访问每个数据条目。这样就把每个顶点从分组 i 更换到分组 j 的收益 v 表示为:
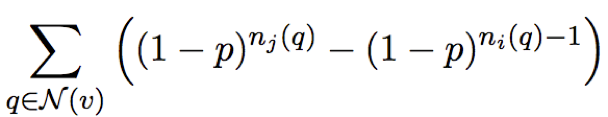
图4
其中的 N(v) 是访问 v 的一组查询,ni(q) 是查询 q 在分组 i 中访问的数据条目数量。采用了这样的收益估计之后,顶点就更容易表现出对含有同类查询的分组的偏好,即便在执行了这样的更换之后也没有降低实际扇出。
这样,论文中的算法就可以表示为如下的形式:
初始化一组平衡的分组(比如随机)
重复如下步骤直到收敛
对于每一个顶点 v
根据以上的方程,找到移动收益最高的分组 j
记录下顶点 v 有想从当前分组 i 移动到新分组 j 的意愿
对于每一对分组 i 和 j
找到有从 i 到 j 的意愿的顶点和有从 j 到 i 的意愿的节点,更换它们
优化效果和大规模问题的表现
扇出最小化问题等效于一个平衡超图分区问题。目前就有一些超图分区框架,但是Facebook的图规模太大了,现有框架都处理不了。
Facebook 在 Apache Giraph 构建了他们的解决方案,而且为图的大小和理想的分组数目做了精心的设计:顶点运动的评价可以用分布式的方式完成,而且发生在当前顶点与其它顶点沟通过任务分配之后。同样地,顶点更换的操作也可以用分布式的方法完成,成对的小组 (i,j) 可以分布在不同的托管服务器上,或者用概率选择对更换的决定做近似。在实际应用中,Facebook 的研究人员们发现以分布式方法实现的算法能够处理的图要比其它现有方法能处理的最大的图还要大100倍,同时还无需牺牲优化质量。
图5展现了算法的运行时数据(SHP的两个变体 SHP-2和 SHP-K)并与其它现有的分区框架进行了对比。测试内容包含在三个不同大小的图(边的数目不同,从一千万到五十亿)和不同的分组数目中的表现。在小规模的优化任务中,SHP往往是完成得最快的那个;而对于大规模优化任务,SHP是唯一一个能够在合理的时间内求出一个优化方案的参赛者。

图5
图6展现了SHP和其它框架的优化质量的对比。由于网络真正的最优平均扇出目前并不能确定,所以图中展示的是各个结果高出现有最优算法的百分比。在大规模优化任务中,SHP的效果是最好的;不过在小规模优化任务中,SHP最多可以比现有算法中最好的结果差12%。
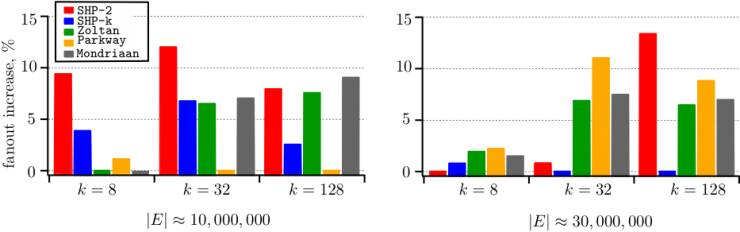
图6
结论和拓展阅读
扇出减少模型可以在Facebook的许多基础优化问题中起到作用,比如数据碎片化、查询路由和索引压缩。从 SHP 开发成功之后,Facebook 就经常用它来解决具有十亿节点和万亿条边的图扇出优化问题,内部实验表明在分布式系统上使用 SHP 的数据分配方案可以把 CPU 消耗下降一半之多。这篇论文也被收录在了 VLDB 2017。SHP 也已经作为一个 Giraph 应用开源,可以用在优化任务和教育中。
论文地址:http://www.vldb.org/pvldb/vol10/p1418-pupyrev.pdf
NSDI 2016的分区优化器论文地址:https://www.usenix.org/system/files/conference/nsdi16/nsdi16-paper-shalita.pdf
via Facebook Research Blog,AI 科技评论编译
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————









