“ 订单台账,用于保存订单的应收和实收数据。通过对账比较应收和实收金额,确保订单可以正常流转”
系统简介
订单台账,用于保存订单的应收和实收数据。通过对账比较应收和实收金额,确保订单可以正常流转。
系统主要分为三个模块:
正向模块:用于对账,确保订单生产,包括订单台账服务、订单台帐任务
务;
逆向模块:用于逆向流程处理,主要用于虚拟资产的退款发起和实收金额的冲销,包括订单台帐退款服务和订单台帐退款任务;
ERP 模块:用于展示订单台帐相关信息和退款数据,方便客服和运维人员查看。
名词解释
订单管道:处理订单任务,包括调用一次拆分、给台账推数据、给ofw推数据、发送下单消息等一系列操作;
订单拆分:将原始单拆分为可以履约的生产单;
OFW:控制订单履约流程;
先款订单:下单后,用户无需在线付款即能正常履约的订单,一般都是用户收货后通过POS机刷卡或者现金支付;
订单应收:下单后,用户需要支付给京东的金额: SKU的实际金额+运费+服务费-优惠;
订单实收:下单时或者下单后,用户已支付给京东的金额,包括虚拟资产(优惠券、京豆、余额、礼品卡)和在线支付等。
正向模块
先款(流程图)

用户下单以后,订单管道就会把订单xml推送到台账系统,台账系统会解析出订单的应收信息和虚拟资产,计算出应收金额。
用户跳到收银台,就会来查询台账的订单应收金额接口,台账计算并返回订单的应收金额。
用户支付之后,支付交易系统会把订单的实收信息推送到台账系统.台账接收到订单的实收信息计算订单实收金额,直接对比订单应收金额,产生对账任务.对账任务异步执行,发送对账消息,同时调用订单中间件接口修改订单状态为暂停。
此时可以理解为订单对账完成.对账完成后的订单,订单中间件会通知OFW系统,OFW系统调用拆分系统返回拆分结果。
如果订单满足拆分条件,拆分系统会把子单的应收推送给订单管道,子单的实收推送给台账系统,同时发送订单拆分消息。
台账拿到子单的应收和实收再次对账,重复上诉流程,进入订单履约流程。
先货(流程图)
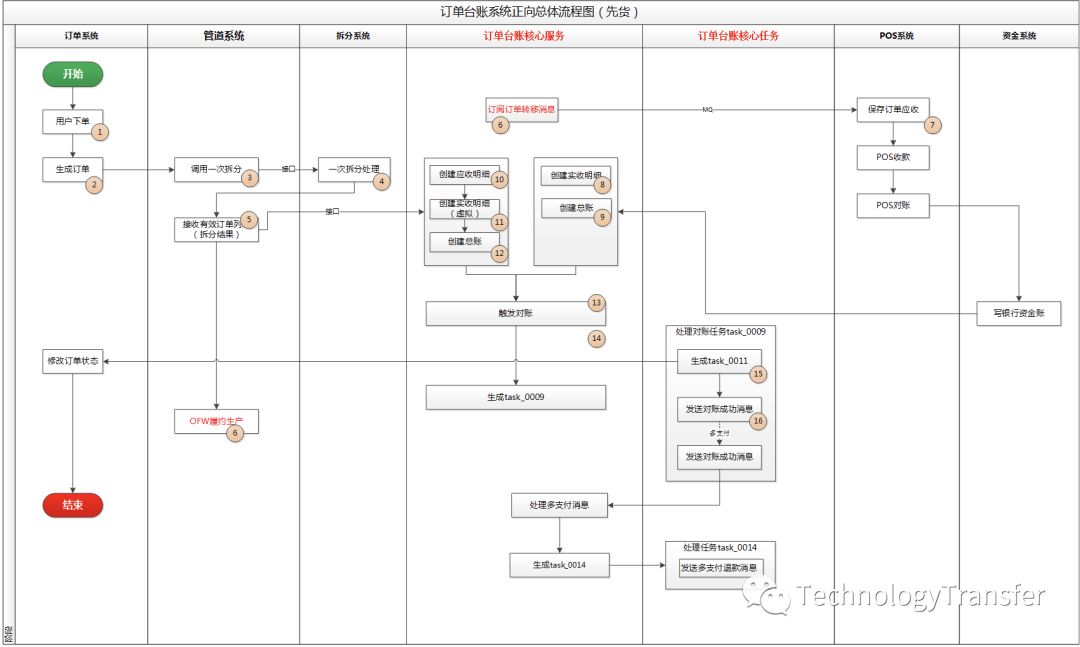
先货跟先款的最大区别是生产流程不依赖台账对账,直接推送OFW进入生产。
台账系统订阅订单转移消息,把订单应收信息发送给POS系统。
用户收到货以后通过POS刷卡或者现金支付,T+1日POS系统把订单的实收信息推送到台账,台账对完账以后,同样产生对账任务。
对账任务异步执行,发送对账消息,同时调用订单中间件修改订单状态为完成。
逆向模块
多支付
多支付是指订单的实收大于订单的应收.在发送对账消息时,如果是多支付,会再发送一个多支付的对账消息,通知多支付退款系统,把多余的钱退给用户。多支付需要人工审核,一般是 T+1 退款。
整单退
整单退是指用户在收到货之前取消订单或者受到货时直接拒收.订单实收分为两部分:虚拟资产和在线支付.用户取消订单或者拒收后,最终会发出订单取消消息.
台账系统通过订阅订单取消消息,发起虚拟资产退款,最终通过删单平台把虚拟资产退给用户.在线支付部分由业务系统发起,在退给用户之前,需要冲销台账实收.
冲销成功后,再调用支付系统退款给用户。
售后退
用户收到货以后发起的退款就是售后退款.售后退款审核通过之后,同样是先冲销台账实收,冲销成功后再调动支付系统退款给用户。
ERP 模块
1. 根据订单号查询台账详细信息,退款信息。
2. 批量重置任务。
性能优化
数据拆分
台账根据订单号路由来分库分表,所以扩容比较容易.取一个新的号段即可写入扩容后的库,不需清洗老数据。
由于台账处于生产流程的核心环节,对性能和吞吐量要求都很高,随着分库数量的增加,性能和吞吐量也都有很大的提升。
但台账系统本质上要解决是热点数据的性能问题,不需要所有的订单业务都要求很高的性能,比如逆向退款.这个热点数据可能是几天的,也可能是几周的。
目前正在建设一个归档历史库,把冷数据迁入归档历史库,尽量不用再扩容数据库。
最理想的是应用实例跟数据库打包成一个对账单元,整个台账系统由若干个对账单元组成.当性能不满足业务要求时,我只要增加对账单元就可以了。
有了对账单元,就可以考虑做多中心,把对账单元部署到多个机房.不过关于多中心的设计会更加复杂,比如一个机房挂掉了,能否把这个机房的流量安全并且快速迁移到其他机房,在保证数据无损的情况下。
对账单元这种设计的局限性就是要求路由字段为整型才可行.如果路由字段是字符串,暂时还没有想到可行方案。
异步执行
台账的应收和实收都是异步写入的,即先把应收或者实收数据落到任务表里,在任务执行时才把应收或者实收数据写入到业务数据库。
这样接应收或者接实收的任务是可以独立出来作为一个单独的任务数据库.写任务表是非常快的,而且任务库可以任意扩容。
可以想象成一个漏斗,入口很大,后面是慢慢流下去的,流下去的速度取决于任务的执行速度.对于台账来说,流下去的速度越快越好。
台账的任务执行也做了一些优化.最初的任务模块就是通过部署多个 worker,多个 worker 一起抓任务,抓到任务之后再锁定任务,哪个 worker 锁定成功就执行任务。
这样做的好处就是去中心化,任何一个 worker 节点挂了,不会影响整体任务的执行.缺点也非常明显,同一个任务会被多个 worker 抓到,多个 worker 一起抢任务锁,如果并发量很大会对数据库有一定的压力。
我们首先是接入了财务的分布式任务框架,通过数据分片,让每个 worker 抓取不同的任务,依然是先加锁再执行任务。
感觉扫库的效率还是不够高,当瞬间任务量特别大的时候,任务执行会有一定的延迟,又引入消息二级驱动.每创建一个任务,异步发送一个带任务的消息,通过消息来驱动任务执行。
消息接到任务后同样是先锁定,再执行.分布式任务作为兜底方案,为了避免 worker 跟消息抢任务, worker 默认抓取15S 之前的数据,可动态调整。
这种任务执行的效率和吞吐量都很高,但是毕竟引入了一个中间件,它就可能成为一个风险点.比如消息延迟了,这种情况我就需要人工调整 worker 抓取任务的时间范围。
所以我们又做了一次优化,创建一个任务后,把任务放到异步线程池中去执行,省略任务锁定环节.这样的任务执行几乎是没有延迟的,高效而且稳定。










