
作者:黑白键
全文共 3469 字,阅读需要 6 分钟
—— BEGIN ——
所谓的“内容推荐”,把主语谓语宾语补充完整之后就是“
系统把内容推荐给用户
”。
那推荐系统如何构建?说白了就是要解决“
什么样的内容推荐给什么样的用户
”的问题以及“
如何推
”的问题。
针对引文中的两个问题,可以总结为以下三个点
-
我们推什么样的内容——what
-
我们推给什么样的用户——who
-
内容如何推荐给用户——how
一、内容篇(What)
说到内容,先不着急解决“推什么”的问题。在这之前,我们首先要分析我们拥有什么内容,这些内容是如何产生的。
目前互联网内容信息的载体主要分为以下几种:文字、图片、音频、视频。
而生产这些内容的用户大体又可分为两种:
-
专业从事内容生产的PGC用户,一个PGC用户的背后往往由一个专业的团队组成,他们分工明确,撰写、拍摄、录制、后期、包括后期的市场宣传都有专门的人员从事,此类用户的生产的内容质量往往比较高。
-
普通的UGC生产用户,此类用户无固定生产内容的习惯,往往是三天打鱼两天晒网,其生产的内容质量也较低。
根据平台定位不同,其拥有的内容资源也不同,生产内容的用户构成也不尽相同。
根据上述列出的几种内容类型和生产用户类型,可以组合出“图片+PGC”、“文字、图片+PGC”、“视频+PGC”、“视频+UGC”….等多种组合类型。结合自身平台业务线,找出内容数量靠前的几种组合,也就是我们所拥有的内容优势所在。
当我们分析出我们拥有什么以后,接下来所要解决的问题就是如何筛选优质内容,以及如何进行内容信息识别和聚类。对于优质内容我们要在推荐策略里基于更多展现曝光。
关于优质内容的筛选,主要分为“机器筛选”和“人工筛选”两种方式。而实际操作中,往往是二者的结合,因为单纯机器筛选其客观性太强,部分优质内容机器无法识别
(对于上述四种内容信息的载体,其展现形式的表现力:文本图片=音频>视频)
,而纯人工筛选又会受审美差异等主观因素的影响难易做到公平公正。
“人工筛选”的方式无需多说,而对于机器筛选优质内容,在筛选之前要做好充分的数据收集及上报,只有数据维度足够充分,才能为筛选做保证。
拿音乐app软件举例“如何评判一首普通歌曲的质量好坏”如下图所示:
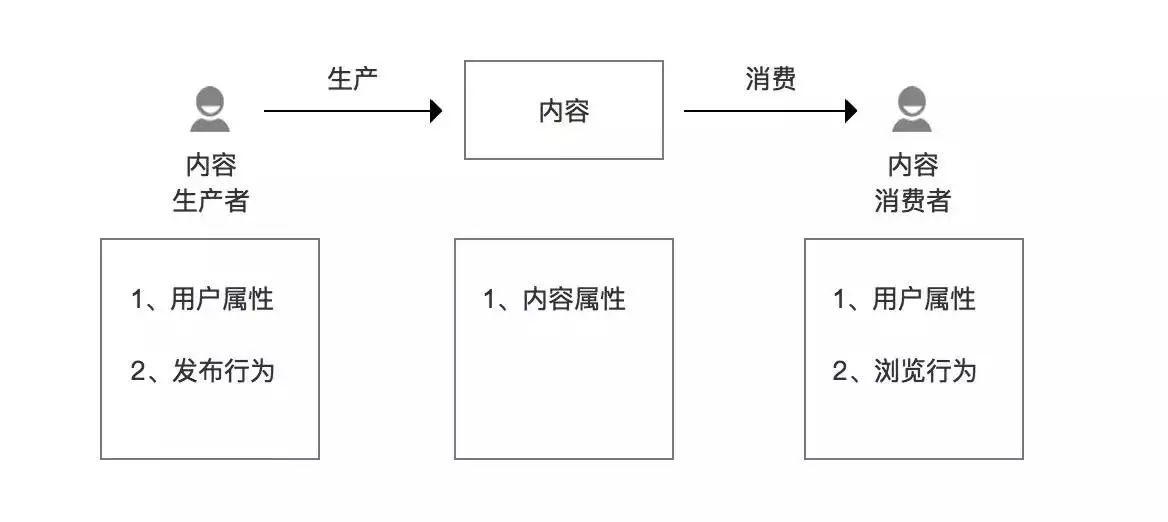
除了歌曲本身作为内容的形式之外,更是链接“内容生产者”和“内容消费者”之间的纽带,所以数据的收集除了歌曲本身的属性之外
(例如:音频长度、kpbs、格式、文件大小….等等)
之外,也要从生产者的用户属性
(PGC/UGC,年龄,地域,性别,个人爱好….等等)
、发布行为
(上传歌曲的时间、上传歌曲的频次….等等)
和消费者的用户属性
(性别、年龄、职业、地域、注册时间….等等)
、浏览行为
(点击、播放、重复播放次数)
等多维度评价一首歌曲的质量。
不同app对于内容的质量评估数据指标不同,需结合实际情况具体分析,此处不再一一详细列举各个数据指标。
对于歌曲而言,最终要的几个指标无非是:曝光点击比、播放完整度、评论、分享、收藏率…等等等等等等。
此处对内容质量的动态评级,还可以利用对生产者评级和消费者评级的方式来判断,各个等级之间有着严格的标准划分
(此处不详述分级的方法,具体情况具体制定)
,用户的评级随自身行为动态调整
(等级正反馈、负反馈机制)
。
不同等级的用户生产和消费行为,对内容评级的影响不同,越优质的用户其行为对内容质量的影响越大。
说完内容质量的评级,之后就是对内容的聚类。
还拿音乐举例,音乐本身并无任何分类,对于一首歌曲而言无非是多个音符的连续演奏。我们凭借自己的生活经验和认知对歌曲进行分门别类:
-
欧美音乐/港台音乐/内地音乐…
-
摇滚/流行/蓝调…
-
抒情/狂欢/悲伤….
-
钢琴曲/小提琴/吉他曲
……
此处对内容聚类的方法应遵循“相互独立、完全穷尽”的原则。即不同划分维度之间要相互独立,互无交叉,而每个维度里划分又要尽可能细化到最小的颗粒度。
除了内容聚类的方法,内容的聚类的流程,同样的,可以采取人工和机器结合的方式,其大体流程如下图所示:

内容生产者,在上传内容时,对内容进行分类、设定内容标签。其内容进入后台首先按照用户上传时的分类进行筛选,之后由审核人员对其标签进行走查,将无分类的内容进行分类,同时对错误分类进行修正
(此时所有审核人员的操作结果,系统都应该给生产者发送信息提示其内容被修改,优化上传流程)
。
所有人工审核后的内容库里的内容作为最终对外分发的结果,在前端对外分发。
至此,我们已经完成了对优质内容的筛选和对内容的聚类。
那谁来消费我们的内容呢,谁来为我们的内容买单?我们的用户群是谁,他们来自哪?是男是女?年纪多大?他们是高、是矮,是胖,是瘦?从事什么工作?有什么爱好?他们收入如何?
二、用户篇(Who)
承接上文,说到用户,绕不开的一个话题就是用户画像。
要建立推荐系统的用户画像,我首先会问自己两个问题:
-
“我们的用户是谁?”
-
“他们都喜欢什么?”
如果说用户画像是对一个人描述,那么第一个问题更像是描述一个人的外在,第二个问题更像是描述一个人的内在。外在对应用户属性,内在则对应用户行为,行为连接内容,从而分析用户喜好倾向,如下图所示:
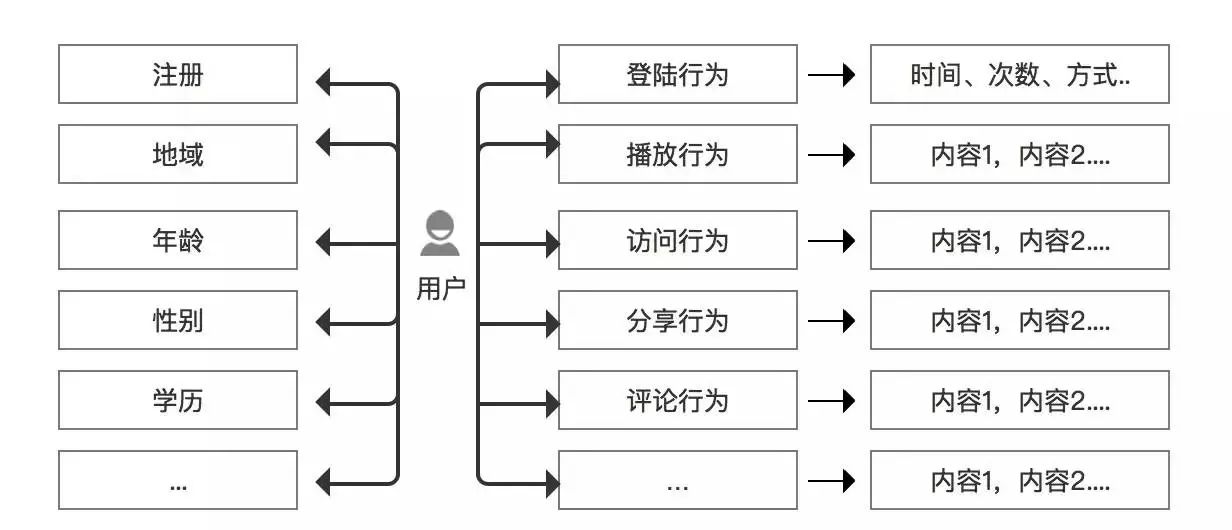
此处数据统计的维度和准确性的重要性不再赘述,左侧是用户属性,右侧是相关的用户操作行为,所有的操作行为最终都能落地到具体一个内容上
(我们在“内容篇”已经讲过如何对内容进行分类标识)
我们通过看内容分类标识,从而分析用户的喜好倾向。
这种方法就好比我们写日记,记流水账,只要我们把足够多的信息记录下来,我们就能足以分析数这个人详细用户画像。
例如:2017年5月12日,家住北京,24岁,清华大学毕业的姑娘小倩穿上她的adidas的衣服,开着她的奔驰车,去王府井的一家人均价位在100/位的火锅店吃火锅….),只要我们记录的信息足够多,足够精确,对用户画像的描述也就越清晰。
在推荐系统里,我们通过用户画像需要解决的是用户喜好倾向的问题,但用户的喜好倾向不是一成不变的,除了要做到数据的持续收集,在判定用户兴趣时,用户的短期兴趣倾向和长期兴趣倾向需要做策略的融合。持续对两种维度的权重调权,从而得到最优解。
举例:我是一个喜欢摇滚音乐的用户,不经意间听了几首纯音乐,我们并不能一刀切的认为用户的喜欢倾向由摇滚转为轻音乐,而是应该记录下这种行为,在策略里不断试探尝试用户兴趣,持续推荐不同内容,从而判定用户真正兴趣。
在推荐系统里,我们通过用户画像需要解决的是用户喜好倾向的问题,但用户的喜好倾向不是一成不变的,除了要做到数据的持续收集,在判定用户兴趣时,用户的短期兴趣倾向和长期兴趣倾向需要做策略的融合。持续对两种维度的权重调权,从而得到最优解。










