我们创建Annealing来驱动持续部署。一旦在Prodspec里声明intent,就是想要生产环境匹配这个intent。更新intent通常涉及手动工作和审批,但是在这之后,自动化应该能够代替人工干预。Annealing就起的这个作用。
持续实施的目标是
让生产环境安全快速地匹配intent
。Annealing逐渐变更应用——比如,通过管理金丝雀部署或者受控的滚动升级。这个工具支持应用多个安全策略:因为Annealing可以看到应用的所有变更,它可以决定哪些变化是安全的,并且什么时候应用这些变更。考虑限速这个场景:Annealing可以限制某个job的变更数量,即使有多个流程或者人在同步和该job交互。
作为规则,我们想在reconcil生产环境的时候避免人工审批,因为在我们的经验里,这类人工干预
很少带来有用的东西
。我们仍然允许人工审核特定重要的变更(比如,数据删除),以及所有标准的自动检查。我们将这些事件保持在最低限度,以避免人工批准者的脱敏。
Annealing负责所有基础架构的配置,从二进制文件版本更新到定额管理,数据库schema或者负载均衡器的配置。多年来,我们发现基础架构始终比预期的更为动态——比如,执行集群的“一次性设置”的次数,可能比启动测试实例的次数更多。
因此,我们鼓励用户将生产环境的所有方面编码到Prodspec中,并通过Annealing来强制执行它们。虽然这种方法最初成本很高,但很快就能得到回报。
我们还发现Prodspec的扩展建模特别有助于turnup。turnup的传统方案是文档和自定义工作流。这些工作流会不可避免地出错,因此使用它们需要很多人工处理。
广泛持续的执行在
很大程度上消除了这个问题
。由于服务的所有基础架构方面都是被持续评估的,因此问题会立即出现,而不仅仅是在下次执行turnup工作流时才被发现。
持续执行由这两层驱动:
如果可能,我们更喜欢在 Enforcer 级别表达执行逻辑和约束,这是无状态层,更容易理解和操作。但是,这种方法并不总是可行或可取的 —— 比如,对新的二进制版本进行为期一周的仔细部署可能需要慢慢更新intent。
Enforcement(执行)
Enforer负责acutation的最后一公里。如图8所示,Enforcer跟踪intent,并且调用插件来更新生产环境的状态。Enforcer对intent没有控制:它唯一做的决策是现在能否推送特定的asset还是需要推迟。
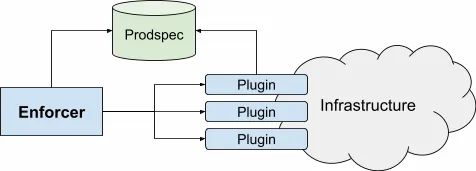
图8:Enforcer及其插件
所有和基础架构的交互都是通过插件完成的,因为Enforcer不会直接接触或者查看生产系统。这让任意用户都可以添加更多的集成点,这是很有用的,因为服务通常都有一些特殊需求,比如自定义配置或者API。插件方案也有助于部署:不用滚动升级一个单体应用二进制,而是升级很多个小的二进制文件,每个都有自己的生命周期。
当enforcer调用某个插件时,它仅仅提供incarnation ID以及需要操作的asset ID。插件在需要时从Prodspec处得到更多的信息。
Annealing有两种主要的插件类型:
1、asset插件管理Annealing和给定类型的asset的生产环境的交互。asset插件实现两个方法:
2、check插件来决定能否在现在推送某个asset还是需要延迟。对于要推送的asset的所有检查都必须通过。
在Shakespeare服务里,所有asset类型都需要asset插件:Borg job,负载均衡器资源以及Spanner数据schema。我们还需要检查check插件来避免周末的推送。
Annealing插件和Kubernetes控制器在有些方面很类似,它们都
抽象了操作生产环境特殊方面的逻辑
。但是,实现上这两有所不同:
Enforcer独立处理每个asset。最初,我们在决策之前都会尝试评估所有asset,但是遇到了可扩展性的问题。
如图9所示,Enforcer按照如下步骤为每个asset运行着一个永久的循环:
-
Pinning:决定使用哪个incarnation作为intent
-
Diff:如果intent和生产环境没有不同,循环结束
-
Check:当需要推送时,验证现在是否可以推送,如果不能,循环结束
-
Push:基于intent变更基础架构
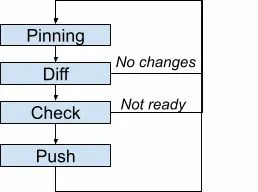
图9:Enforcer的asset循环
这个循环不会一个接一个地检查每个incarnation,并且不保证每个incarnation都被执行,每个迭代使用最新的incarnation。该方案可以避免卡在受损的incarnation里。相反,有机会可以修复intent,这是自动的。因此,如果某个特定的中间状态必须在生产环境中反映,则
必须等待强制实施了该状态
,之后才能再进一步更新intent。
每个asset都是独立的,并且循环对于每个asset来说是独立运行的。但是,我们不会随意推送asset——这是检查的基础。我们使用检查来延迟(而不是拒绝)对生产的更改。
Annealing可以洞察并且控制它执行的整个服务。这让Annealing拥有独特的中央视角,允许检查在整个生产过程中轻松实施不变量。这让检查在概念上通常很简单,但功能很强大。比如:
依赖解决器是我们介绍的第一个check。它确保以正确的顺序推送asset。想一想图6的Shakespeare服务:当减少某个集群的占用空间时,通常需要更新负载均衡器的配置,以减少该群集提供的最大容量,然后再减少前端的副本数量——这样,你不会遇到前端无法承担发送给它的负载的情况。
解决器check让你可以在一次变更中同时更新负载均衡器和前端的容量,而Annealing会以安全的顺序推送这些变更。依赖解决器check使用如下逻辑:
-
发送推送asset A的请求
-
Enforcer调用check插件,包括解决器
-
解决器检查asset A的diff。如果diff认为这个变更不会影响容量,那么check通过。
-
如果check发现容量的变化,解决器查询该asset的依赖。这些依赖显式地列在带有插件的Prodspec里,通常在Prodspec生成pipeline里自动生成。
-
解决器请求为每个依赖B做生产环境diff。
-
如果asset B的diff表示需要在asset A推送后变更容量才能保证服务运行正常,那么A的推送会被阻止,直到asset B的diff消失。否则,asset A可以被处理以及推送。
虽然决定推送是否可以进行的实际逻辑可能很复杂,但是这种模式很通用——比如,你可以定制解决器执行静态顺序(“在推送asset B前总是先推送asset A”)或者版本式顺序(“运行的asset A的版本必须和asset B的一样或者更大”)。
渐进式推出
Enforcer只关心最后一公里:一旦它决定了给定asset的特定intent,Enforcer检查执行该变更是否安全,然后就执行这个变更。
但是如果我们想要在大规模下渐进式部署呢?假定Shakespeare服务在10个集群,而不是一个集群上运行。你不会希望一次只能更新一个单独的集群。相反,你想设置新的目标状态(比如,运行二进制文件的v2版本),随后能以受控的方式更新每个asset。
名为Strategist的服务器通过持续运行如下三个步骤来执行渐进式推出,如图10所示:
-
Select:基于推出决策和check,决定在上线的这个点可以变更哪些asset。需要挑选一个特殊的集群吗?现在能否更新不止一个asset?
-
Update:为所选的asset改变生产环境的状态到新状态。
-
Validate:决定变更是否是好的。如果不是,推出应该在这里停止,可能还需要回滚。
-
Strategist持续运行这三个步骤,直到受推出影响的所有asset都已经被更新,或者遇到了什么问题。
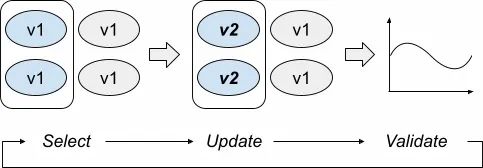
图10:Select-Update-Validate循环
Select
Select这一步的目标是找到现在就可以更新的asset。如果没有assest准备好推送,这一步可以不返回任何东西。通常,推出策略是在这里编码的——比如,一个策略指定应首先推送金丝雀部署,然后是一段时间的延迟,然后增量到生产环境的其余部分,每个步骤之间还有一些进一步的延迟。
select步骤是通过名为Target Selection的无状态服务来实现的。这个服务提供了一个RPC方法:
Target Selection通过Prodspec配置,并且实现如下策略:
-
一次性推送所有东西
-
以预先定义好的顺序,一次推送一个集群
-
推送一个asset,随后所有其他asset
我们发现,即使在单次推出的时间范围内,也需要能够应对不断变化的环境。比如,如果推出持续两周并影响数百个asset,则在推出过程中可能会添加和删除某些asset。
推出政策本身可能会发生变化——无论是有机的还是由于外部约束。比如,关键问题可能需要快速推出才能部署某个缓解措施。在这些情况下,Target Selection的无状态化就很有用。由于Target Selection只关心更新和未更新的内容,因此它可以处理动态环境。
Update
一旦选中了需要更新的asset,Enforcer将驱动实际生产环境的变更。有两种基本方法来驱动变更:
在其他系统里也可以发现这两种解决方案。每个方案都有一些不同的权衡,我们使用了两种。
如图11所示,基于actuation的推出是由SoT的变化立即改变所有asset的intent。随后生成新的Prodspec的incarnation。但是Enforcer持续使用之前的incarnation,因此生产环境没有被更新。之后,因为有asset被选出来更新,Enforcer被要求使用新的incarnation。
在Shakespeare服务里,这意味着单一版本被用来配置所有集群的前端二进制文件,之后每个集群仅在需要的时候被推送。
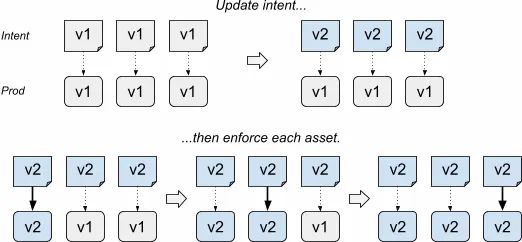
图11:基于actuation的推出
这个方案的优势就是很简单:我们只是控制沿着incarnation前进的速度。它是一个包罗万象的机制:对SoT的具体更改并不重要,因为在实践中,我们仔细地推出了整个incarnation的内容。
但是,这个方案
缺少灵活性
。考虑这样的场景:多个正在进行的推出改变了相同的asset——比如,为期一周的新标志与每日版本更新并行推出。这个用例无法通过纯粹的基于actuation的推出来管理。在实践中,需要对更改进行批处理。
如图12所示,基于intent的推出仅仅在特定asset选中后才会更新asset的intent。随后intent立即通过Enforcer被执行。
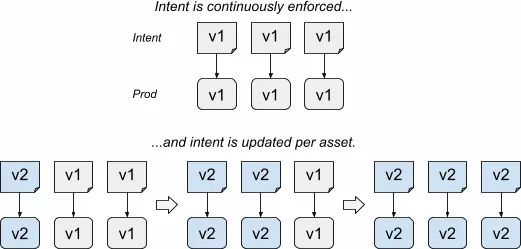
图12:基于intent的推出
基于intent的推出比基于acutation的推出复杂很多。它们要求能够程序化地改变intent的能力。在Prodsepc模型里,这个需求意味着依赖于可以以编程方式编辑的SoT。SoT还应允许足够的粒度来匹配asset的选择方式。
在Shakespeare服务里使用这个模型,需要SoT来独立指定每个集群的前端二进制版本。
基于intent的推出允许推出影响并行运行的相同asset——这在基于actuation的推出中是不可能的。唯一的约束是这些推出必须修改asset的不同方面——比如,一个推出可能会更改二进制版本,而另一个推出可能会更新标志。





