原谅我真的不知道怎么取这次的题目……
一个朋友跑来问我,
怎么使用linux将一个名称和序列单行存放的数据转成fasta格式。
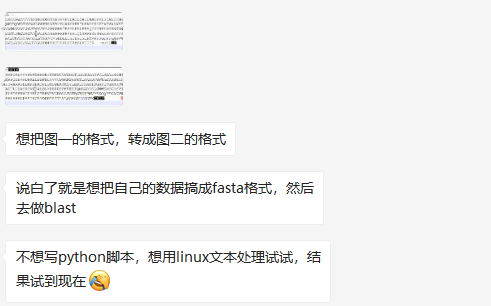
还是直接上图比较直观:
原始的文件是这样的:

名称1 tab分隔 名称2 tab分隔 名称3 tab分隔 序列 tab分隔 null
转成:

>名称1|名称2|名称3
序列
好,那第一步先把tab分隔变成分行:
$ cat temp |sed 's/\t/\n/g'|head -8
MetaCYC
G-12237
Q7X281
MKVACIGAGPGGLFFATLLKRSRPDAEVVVFERNRPDDTFGFGVVFSDATLDAIDAADPVLSEALEKHGRHWDDIEVRVHGERERVGGMGMAAVVRKTLLSLLQERARAEGVQMRFQDEVRDPAELDDFDLVVVCDGANSRFRTLFADDFGPTAEVASAKFIWFGTTYMFDGLTFVHQDGPHGVFAAHAYPISDSLSTFIVETDADSWARAGLDAFDPATPLGMSDEKTKSYLEDLFRAQIDGHPLVGNNSRWANFATRRARSWRSGKWVLLGDAAHTAHFSVGSGTKMAMEDAVALAETLGEASRSVPEALDLYEERRRPKVERIQNSARPSLSWWEHFGRYVRSFDAPTQFAFHFLTRSIPRGKLAVRDAAYVDRVDGWWLRHHEAGPLKTPFRVGPYRLPTRRVTVGDDLLTGTDGTGIPMVPFSGQPFGAGVWIDAPDTEEGLPLALDQVRETAEAGVLLVGVRGGTALTRVLVAEEARLAHSLPAAIVGAYDDDTATTLVLSGRADLVGGTK
null
MetaCYC
EG10460
P05719
稍微解释一下:
-
-
-
-
g
:全局替换。不加的话只替换第一个,加上就是替换所有的。
接下来用
grep -v
把null这行去掉:
$ cat temp |sed 's/\t/\n/g'|grep -v "null"|head -8
MetaCYC
G-12237
Q7X281
MKVACIGAGPGGLFFATLLKRSRPDAEVVVFERNRPDDTFGFGVVFSDATLDAIDAADPVLSEALEKHGRHWDDIEVRVHGERERVGGMGMAAVVRKTLLSLLQERARAEGVQMRFQDEVRDPAELDDFDLVVVCDGANSRFRTLFADDFGPTAEVASAKFIWFGTTYMFDGLTFVHQDGPHGVFAAHAYPISDSLSTFIVETDADSWARAGLDAFDPATPLGMSDEKTKSYLEDLFRAQIDGHPLVGNNSRWANFATRRARSWRSGKWVLLGDAAHTAHFSVGSGTKMAMEDAVALAETLGEASRSVPEALDLYEERRRPKVERIQNSARPSLSWWEHFGRYVRSFDAPTQFAFHFLTRSIPRGKLAVRDAAYVDRVDGWWLRHHEAGPLKTPFRVGPYRLPTRRVTVGDDLLTGTDGTGIPMVPFSGQPFGAGVWIDAPDTEEGLPLALDQVRETAEAGVLLVGVRGGTALTRVLVAEEARLAHSLPAAIVGAYDDDTATTLVLSGRADLVGGTK
MetaCYC
EG10460
P05719
MSAGKLPEGWVIAPVSTVTTLIRGVTYKKEQAINYLKDDYLPLIRANNIQNGKFDTTDLVFVPKNLVKESQKISPEDIVIAMSSGSKSVVGKSAHQHLPFECSFGAFCGVLRPEKLIFSGFIAHFTKSSLYRNKISSLSAGANINNIKPASFDLINIPIPPLAEQKIIAEKLDTLLAQVDSTKARFEQIPQILKRFRQAVLGGAVNGKLTEKWRNFEPQHSVFKKLNFESILTELRNGLSSKPNESGVGHPILRISSVRAGHVDQNDIRFLECSESELNRHKLQDGDLLFTRYNGSLEFVGVCGLLKKLQHQNLLYPDKLIRARLTKDALPEYIEIFFSSPSARNAMMNCVKTTSGQKGISGKDIKSQVVLLPPVKEQAEIVRRVEQLFAYADTIEKQVNNALARVNNLTQSILAKAFRGELTAQWRAENPDLISGENSAAALLEKIKAERAASGGKKASRKKS
grep -v "null"
是去除含有"null"字符串的行。也可以写的更严谨一些:
grep -v "^null$"
。
接下来,就是把前面3行变成一行,并且
|
分隔。
$ cat temp |sed 's/\t/\n/g'|grep -v "null"|awk '{if(NR%4!=0){printf "|%s",$0}else{printf "\n" $0 "\n"}}'|head -4
|MetaCYC|G-12237|Q7X281
MKVACIGAGPGGLFFATLLKRSRPDAEVVVFERNRPDDTFGFGVVFSDATLDAIDAADPVLSEALEKHGRHWDDIEVRVHGERERVGGMGMAAVVRKTLLSLLQERARAEGVQMRFQDEVRDPAELDDFDLVVVCDGANSRFRTLFADDFGPTAEVASAKFIWFGTTYMFDGLTFVHQDGPHGVFAAHAYPISDSLSTFIVETDADSWARAGLDAFDPATPLGMSDEKTKSYLEDLFRAQIDGHPLVGNNSRWANFATRRARSWRSGKWVLLGDAAHTAHFSVGSGTKMAMEDAVALAETLGEASRSVPEALDLYEERRRPKVERIQNSARPSLSWWEHFGRYVRSFDAPTQFAFHFLTRSIPRGKLAVRDAAYVDRVDGWWLRHHEAGPLKTPFRVGPYRLPTRRVTVGDDLLTGTDGTGIPMVPFSGQPFGAGVWIDAPDTEEGLPLALDQVRETAEAGVLLVGVRGGTALTRVLVAEEARLAHSLPAAIVGAYDDDTATTLVLSGRADLVGGTK
|MetaCYC|EG10460|P05719
MSAGKLPEGWVIAPVSTVTTLIRGVTYKKEQAINYLKDDYLPLIRANNIQNGKFDTTDLVFVPKNLVKESQKISPEDIVIAMSSGSKSVVGKSAHQHLPFECSFGAFCGVLRPEKLIFSGFIAHFTKSSLYRNKISSLSAGANINNIKPASFDLINIPIPPLAEQKIIAEKLDTLLAQVDSTKARFEQIPQILKRFRQAVLGGAVNGKLTEKWRNFEPQHSVFKKLNFESILTELRNGLSSKPNESGVGHPILRISSVRAGHVDQNDIRFLECSESELNRHKLQDGDLLFTRYNGSLEFVGVCGLLKKLQHQNLLYPDKLIRARLTKDALPEYIEIFFSSPSARNAMMNCVKTTSGQKGISGKDIKSQVVLLPPVKEQAEIVRRVEQLFAYADTIEKQVNNALARVNNLTQSILAKAFRGELTAQWRAENPDLISGENSAAALLEKIKAERAASGGKKASRKKS
awk '{if(NR%4!=0){printf "|%s",$0}else{printf "\n" $0 "\n"}}'
的含义是,如果行号(NR)取余不等于0(即非4倍数的行),那么打印
|
和整行内容($0),否则就打印换行符+整行+换行符。
最后就比较简单了。把
>
加上:
$ cat temp |sed 's/\t/\n/g'|grep -v "null"|awk '{if(NR%4!=0){printf "|%s",$0}else{printf "\n" $0 "\n"}}'|sed 's/|MetaCYC/>MetaCYC/'|head -4
>MetaCYC|G-12237|Q7X281
MKVACIGAGPGGLFFATLLKRSRPDAEVVVFERNRPDDTFGFGVVFSDATLDAIDAADPVLSEALEKHGRHWDDIEVRVHGERERVGGMGMAAVVRKTLLSLLQERARAEGVQMRFQDEVRDPAELDDFDLVVVCDGANSRFRTLFADDFGPTAEVASAKFIWFGTTYMFDGLTFVHQDGPHGVFAAHAYPISDSLSTFIVETDADSWARAGLDAFDPATPLGMSDEKTKSYLEDLFRAQIDGHPLVGNNSRWANFATRRARSWRSGKWVLLGDAAHTAHFSVGSGTKMAMEDAVALAETLGEASRSVPEALDLYEERRRPKVERIQNSARPSLSWWEHFGRYVRSFDAPTQFAFHFLTRSIPRGKLAVRDAAYVDRVDGWWLRHHEAGPLKTPFRVGPYRLPTRRVTVGDDLLTGTDGTGIPMVPFSGQPFGAGVWIDAPDTEEGLPLALDQVRETAEAGVLLVGVRGGTALTRVLVAEEARLAHSLPAAIVGAYDDDTATTLVLSGRADLVGGTK
>MetaCYC|EG10460|P05719
MSAGKLPEGWVIAPVSTVTTLIRGVTYKKEQAINYLKDDYLPLIRANNIQNGKFDTTDLVFVPKNLVKESQKISPEDIVIAMSSGSKSVVGKSAHQHLPFECSFGAFCGVLRPEKLIFSGFIAHFTKSSLYRNKISSLSAGANINNIKPASFDLINIPIPPLAEQKIIAEKLDTLLAQVDSTKARFEQIPQILKRFRQAVLGGAVNGKLTEKWRNFEPQHSVFKKLNFESILTELRNGLSSKPNESGVGHPILRISSVRAGHVDQNDIRFLECSESELNRHKLQDGDLLFTRYNGSLEFVGVCGLLKKLQHQNLLYPDKLIRARLTKDALPEYIEIFFSSPSARNAMMNCVKTTSGQKGISGKDIKSQVVLLPPVKEQAEIVRRVEQLFAYADTIEKQVNNALARVNNLTQSILAKAFRGELTAQWRAENPDLISGENSAAALLEKIKAERAASGGKKASRKKS
到这里其实已经结束了。但是我还是感觉写的太罗嗦了。于是换了一种解决方法:
$ cat temp |sed 's/\t/\n/g'|grep -v "null"|sed 'N;N;s/\n/|/g;s/^/>/;N'|head -4
>MetaCYC|G-12237|Q7X281
MKVACIGAGPGGLFFATLLKRSRPDAEVVVFERNRPDDTFGFGVVFSDATLDAIDAADPVLSEALEKHGRHWDDIEVRVHGERERVGGMGMAAVVRKTLLSLLQERARAEGVQMRFQDEVRDPAELDDFDLVVVCDGANSRFRTLFADDFGPTAEVASAKFIWFGTTYMFDGLTFVHQDGPHGVFAAHAYPISDSLSTFIVETDADSWARAGLDAFDPATPLGMSDEKTKSYLEDLFRAQIDGHPLVGNNSRWANFATRRARSWRSGKWVLLGDAAHTAHFSVGSGTKMAMEDAVALAETLGEASRSVPEALDLYEERRRPKVERIQNSARPSLSWWEHFGRYVRSFDAPTQFAFHFLTRSIPRGKLAVRDAAYVDRVDGWWLRHHEAGPLKTPFRVGPYRLPTRRVTVGDDLLTGTDGTGIPMVPFSGQPFGAGVWIDAPDTEEGLPLALDQVRETAEAGVLLVGVRGGTALTRVLVAEEARLAHSLPAAIVGAYDDDTATTLVLSGRADLVGGTK
>MetaCYC|EG10460|P05719
MSAGKLPEGWVIAPVSTVTTLIRGVTYKKEQAINYLKDDYLPLIRANNIQNGKFDTTDLVFVPKNLVKESQKISPEDIVIAMSSGSKSVVGKSAHQHLPFECSFGAFCGVLRPEKLIFSGFIAHFTKSSLYRNKISSLSAGANINNIKPASFDLINIPIPPLAEQKIIAEKLDTLLAQVDSTKARFEQIPQILKRFRQAVLGGAVNGKLTEKWRNFEPQHSVFKKLNFESILTELRNGLSSKPNESGVGHPILRISSVRAGHVDQNDIRFLECSESELNRHKLQDGDLLFTRYNGSLEFVGVCGLLKKLQHQNLLYPDKLIRARLTKDALPEYIEIFFSSPSARNAMMNCVKTTSGQKGISGKDIKSQVVLLPPVKEQAEIVRRVEQLFAYADTIEKQVNNALARVNNLTQSILAKAFRGELTAQWRAENPDLISGENSAAALLEKIKAERAASGGKKASRKKS
看上去没多少人话了。。。。显得很专业的样子。
sed 'N;N;s/\n/|/g;s/^/>/;N'
是什么意思呢?
一个N相当于把当前行(MetaCYC)和下一行(G-12237)读取到模式空间中(就是某个地方存起来),这时候模式空间就有2行内容(MetaCYC换行符G-12237),且用换行符隔开。再加一个N,就是再下一行(第3行)也加进去。里面就存了3行内容了(MetaCYC换行符G-12237换行符Q7X281)。后边
s/\n/|/g
就是将换行符替换成
|
(MetaCYC|G-12237|Q7X281),而
s/^/>/
就是在前面处理的内容前面加
>
(>MetaCYC|G-12237|Q7X281)。最后一个N就是把下一行放到这个处理好的行的后边。
好了~~今天到这。
放上本文的测试数据:
链接:https://pan.baidu.com/s/1w31KXlvyGOJqeS0dOfYsjA
提取码:rpag
如果觉得不错,点个“在看”哦~~






