2017年
10
月
19
日至
21
日,由中国计算机学会主办的全国高性能计算学术年会
HPC China 2017
以“应用驱动,生态共建”为主题,在安徽合肥圆满召开。
PerfXLab
澎峰科技作为参展方参加了此次盛典,并在会场展位展示了跨平台嵌入式深度学习方案以及深度学习技术主题分论坛。

HPC学术年会是国际知名的高性能计算盛会,吸引了全球相关行业的学者、科研机构、学校、硬件厂商和软件开发企业共襄盛举。
从HPC现阶段的应用领域可以得知,
AI
已成为应用方向市场的主导因素,而终端
AI
产品也在逐步成为应用趋势。对此,澎峰科技展示了跨平台嵌入式深度学习方案,旨在解决深度学习产品在嵌入式平台上的落地问题。
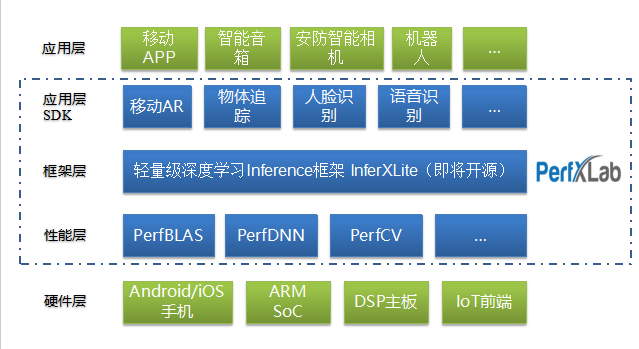
在会场展位平台我们以PerfBLAS与早期推出的开源矩阵计算库OpenBLAS进行了一系列的数据对比,得出以下结果。
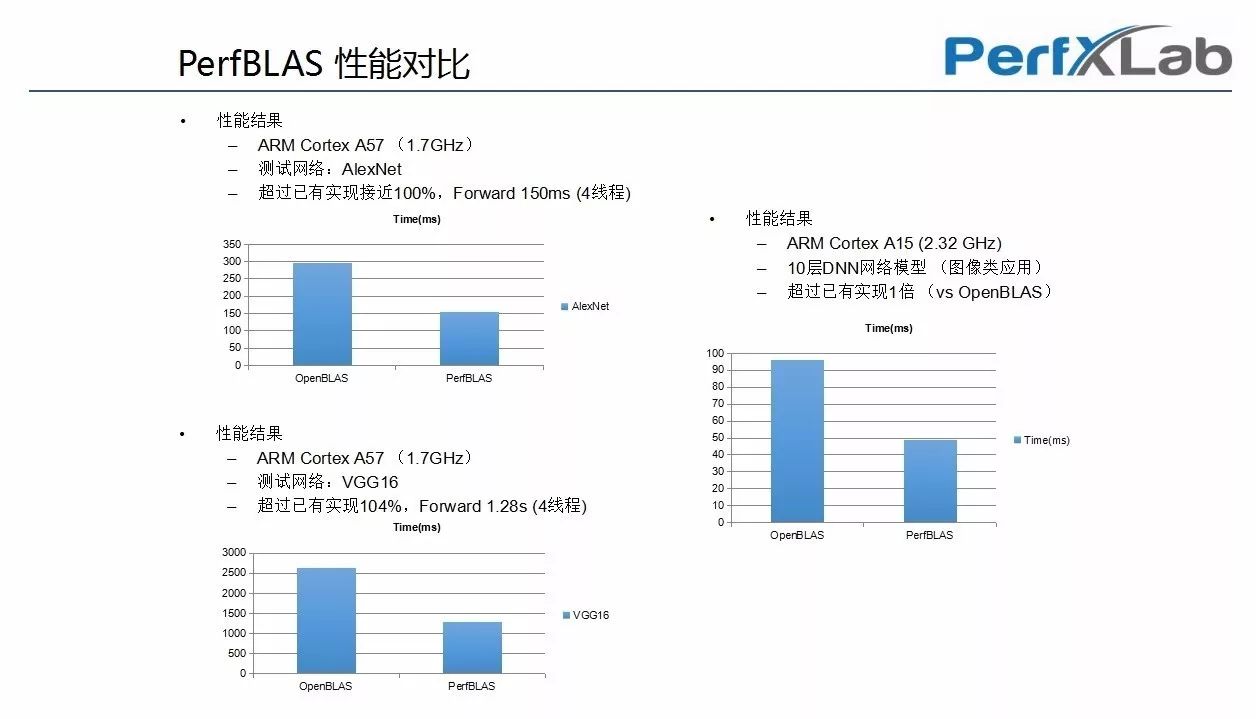
-深度学习专用版PerfBLAS性能优于开源矩阵库OpenBLAS.
PerfBLAS所具备以下优势:
1.支持ARM CPU,嵌入式GPU,x86,Power平台
2.针对DNN模型矩阵特点优化
3.可精简,最低可达到50KB以下
大会期间组织了第一届国产CPU并行应用挑战赛,其中澎峰科技
CEO
张先轶作为挑战赛的评审嘉宾为获得单项奖的团队颁奖。

在 HPC China 2017 的第三天,澎峰科技发起了“HPC深度学习技术论坛”,吸引了业界人士和各大院校的同学围观探讨,其中参与本次分论坛的嘉宾和演讲主题分别为:
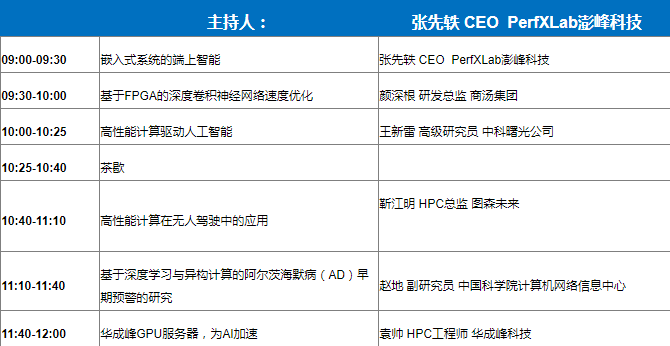


在论坛中澎峰科技CEO首先分析了
目前在嵌入式AI领域如何绕坑所涉及到硬件:(NVIDIA TX1,TX2 、ARM+FPGA、ARM CPU/ ARM CPU+ Mali GPU、MIPS、Movidius, 寒武纪)等硬件产品的差异和优劣性能对比,性能库(OpenBLAS\PerfBLAS、NNPACK)以及模型算法和框架的分析,以及PerfBLAS的数据评测结果等。
想要了解以上内容的小伙伴可以到社群中了解(
添加管理员备注“嵌入式”,管理员同学会第一时间把各位小伙伴添加到我们的讨论学习小组^_^,可以随时提问发言。
)

..................





