今年服务器芯片市场最引人瞩目的事件莫过于AMD携带依托Zen架构代号Naples的EPYC在上次进军服务器市场被挫败10年之后再次向英特尔发起了挑战。
而作为服务器市场霸主的英特尔同样拿出了代号Skylake-SP的Xeon Scalable可扩展处理器家族系列积极应战。
尽管在双方的发布会PPT中都看出了各自性能的提升以及相对竞争对手所取得的优势,但有趣的是,至少在中国,由于无法取得测试样机,因此尚无第三方可以对两者进行横向对比。
为了挖掘背后的真相,中关村在线企业站通过全球权威硬件评测媒体AnannTech的对两者的测试数据来给读者和服务器行业一个清晰直观的认知。

Xeon可扩展家族
从测试结果来看,AMD的EPYC在浮点运算上和内存带宽上取得的优势是惊人的,但是与此同时英特尔在内存延迟、单线程整数运算以及事务型数据库上的优势地位同样难以动摇,双方更是在大数据测试、Java性能测试环节中难分伯仲。而接下来我们将通过测试数据来对比两者之间的性能和优劣。
再次声明:本文中所有数据均出自AnandTech,如数据有误还请见谅。
竞争从口水战开始
在奥斯丁,一名AMD的工程师在详解Zen架构和Skylake架构区别的幻灯片前谈论到。"尽管从幻灯片上来看差不多,但实际上他们有很大差别"。
英特尔的发言人表示完全同意:"实际这两个产品完全是两回事""我们必须得让消费者明白他们不能简单的用AMD的32核心去对比我们的28核心。"
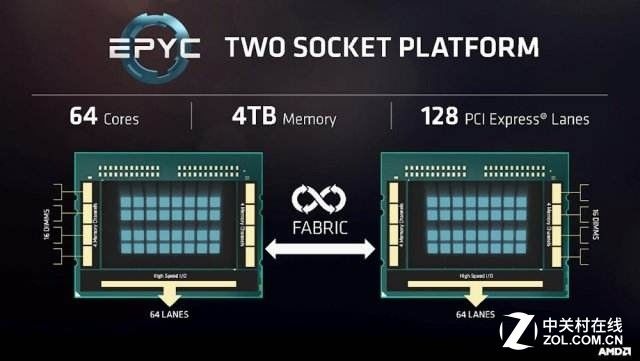
EPYC的32核心令人印象深刻
对于服务器CPU行业来说,英特尔发布的最新一代Skylake-SP的Xeon处理器最新一代使用Skylake-SP架构的Xeon处理器让人感到心喜,代号"Purley"100系列处理器包含了英特尔最新的CPU和网络光纤技术。
而此前AMD发布的全新EPYC 7000系列处理器,凭借AMD公司的Zen架构和可扩展的服务器级别I/O和核心数量更是让业内感到振奋。

Xeon可扩展家族提升亮点同样不少
EPYC代表着AMD取得的史诗级成就。这也让两家公司在近五年之后再一次展开了高性能服务器的性能竞争。目前的这种状况在两家公司之间已经很久没有发生。
英特尔一直不在乎AMD的挑战,也不看重两者之间的竞争,不过对于之前的AMD来说也没有能力与英特尔一战。但是现在情况则完全不同,两者都非常关注彼此下一步的举动。
实际上,全新的Skylake-SP架构对标的并不是前一代Xeon(E5v4),而是AMD崭新的EPYC服务器CPU。两个CPU毫无疑问有很多不同;micro architecture(微架构), ISA extentions(ISA扩展), memory subsystem(内存子系统), node topology(节点拓扑)...而这些技术在具体应用中又会怎样呈现呢?我们先做一个简单的对比。
Skylake-SP VS Zen
英特尔和AMD这次发布的新产品相比过去都有了很大的改变,英特尔的Skylake-SP家族有如下新特点。
1.AVX-512指令集(可提供不同的ISA扩展)
2.1 MB(取代过去的256KB)的2级缓存并带有非包含式剔除3级缓存(只保存从二级缓存中剔除的或者写回的数据)。
3.Mesh拓扑连接方式让每个核心和三级缓存捆绑在一起。
而AMD这边则使用了MCM封装方式:每一块芯片封装中有4块Die,每一片中都包含8个完全一样的核心,这和AMD Ryzen的处理方式一样。
每一个Die拥有两个核心群组,每一组包含4个核心,并支持两条内存通道,单个EPYC处理器最多可拥有32颗核心和8条内存通道。不同的Die通过AMD最新的内部连接器(Infinity Fabric)连接。
至于两者之间的不同,通过下面这张表可以简单了解一下。
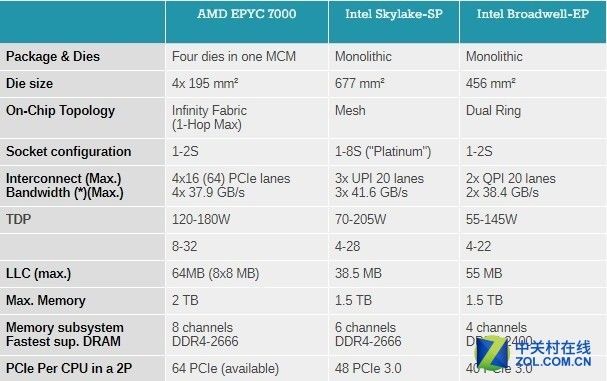
规格对比
从某种角度来说,英特尔拥有最先进的多核拓扑结构,因为它们能够在网格中集成多达28个核心。
Mesh结构将允许英特尔在未来几代中添加更多的内核,同时在大多数应用程序中保证表现一致。最后一级缓存具有很好的延迟表现,适用于需要占用大量内存的应用程序。
访问本地L3缓存块和一个更远的缓存之间的平均延迟差异可以忽略不计,L3缓存成为L2缓存之间进行快速数据同步时的中央存储。
当然,性能最强的Xeon处理器尺寸庞大,而生产价格也非常昂贵。
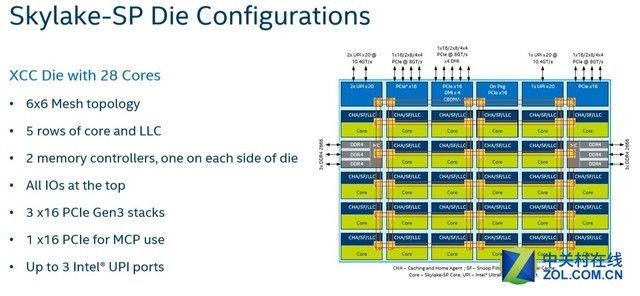
全新的Mesh架构
AMD的MCM解决方案从制造角度来说要便宜不少。在4个die以及每个die配备的两个内存通道支持下,内存峰值带宽和容量都要更胜一筹。
然而,它没有最后一级的中央缓存可以让不同的内核(除了在一个CCX群组内)的L2高速缓存之间实现低延迟的数据协调。八个8 MB的L3缓存在一些情况下表现不尽如人意。
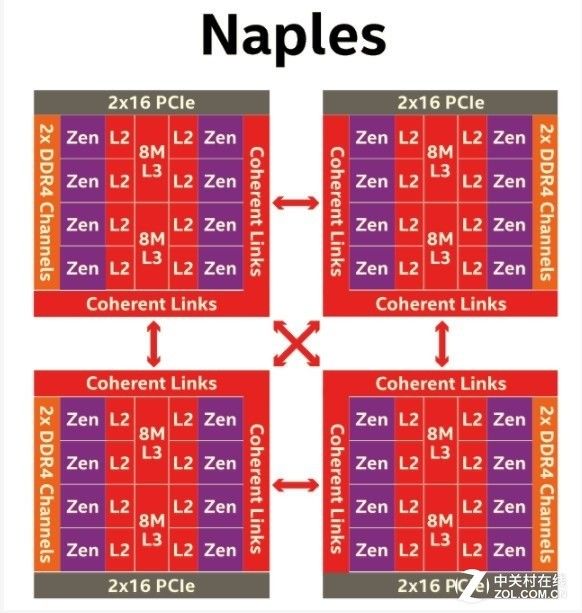
Naples的4*8 MCM架构
测试环境及测试配置和方法
AnandTech在本次测试中使用了更贴近EPYC的Xeon 7601而不是最强的Xeon 8180,同时为了更好地对比性能,还选择了差不多有5年历史的Sandy Bridge-EP架构的Xeon E5-2690。
原因很简单,做为一台服务器来说,5年的服役历史本身就有足够的理由去更换,而这样的测试结果对于那些需要更换服务器的部门经理来说显得更加有参考价值。
所有的测试都基于Ubuntu系统,代号为"Xenial"16.04.2 LTS(Linux kernel 4.4.0 64 bit)。编译器为GCC 5.4.0。首先是Xeon 8176的配置:
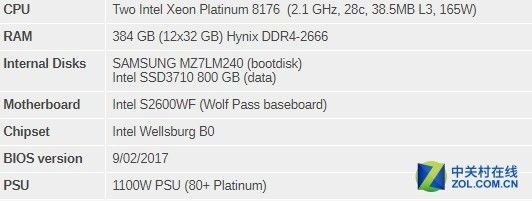
双路Xeon 8176
下图展示了常用的Bios设置,在测试中启用超线程和英特尔虚拟化技术。
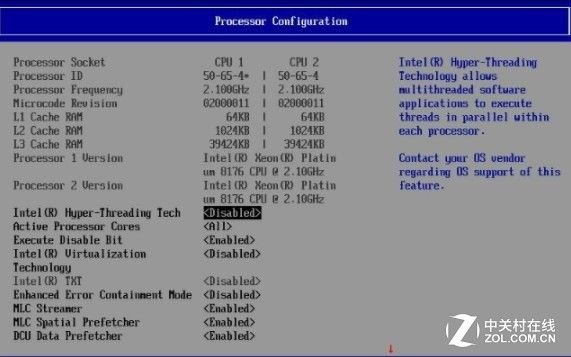
然后是双路系统的,AMD EPYC 7601。

双路EPYC
配置如下:
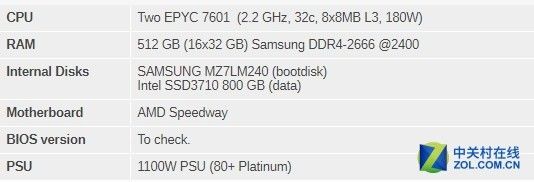
双路EPYC 7601服务器配置
最后是双路Intel's Xeon E5服务器– S2600WT

上一代和5年前的双路E5。
Bios设置如下:
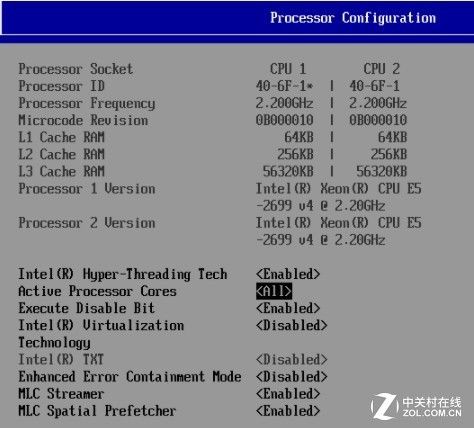
双路E5 2699 v4
其他事项
两个服务器都采用了欧洲标准230V(最大16安)的电源线,房间温度被Airwell CRACs控制在23摄氏度。
内存带宽测试
由于核心数和内存通道数的不断增长,用Stream bandwidth benchmark来测试最新的CPU的全部带宽潜力变得更加困难。
因此在64位的版本号为17的Linux,GCC 5.4上的英特尔编译器(icc)编译5.10流源代码。下列编译器指令用在icc上。
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
注意,这里特别增加了Array,让数据保持在6GB左右,测试中一次用AVX编译,另一次则没有AVX,结果用每秒GB表示。
同时,下列编译器指令被用在gcc上:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
注意一点,在EPYC系统上我们用的DDR4 DRAM运行在2400GT/s(8通道),而英特尔系统的DRAM则是在2666GT/s(6通道)。
因此双路AMD系统理论上内存数据为每秒307GB(2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets),英特尔系统则是每秒256GB(2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets)。
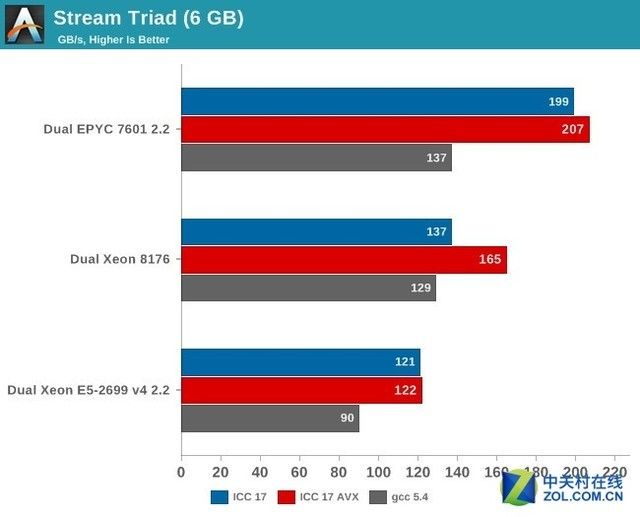
Stream Triad测试
AMD跟AnandTech说他们不是非常相信使用ICC编译器获得的结果,如果使用他们自己完全定制的编译器可以达到250GB/s。
比较有意思的是,英特尔宣称优化过的AVX-512可以达到199GB/s(Xeon E5-2699 v4搭配DDR-2400是128GB/s),但是这样的带宽数只适用于特定的HPC。
所以实际上评测的数据更能反映现实。128线程,8通道 DDR4内存给AMD EPYC处理器大概25%~45%的带宽优势,这可能与大部分的服务器应用没什么关系,但是在很多稀疏矩阵类HPC(超算)应用中却能带来很多好处。
最大带宽是一码事,但带宽必须要尽快投入使用,为了更好的让人理解内存子系统,因此按照不同的核心数来和线程数进行一下梳理。
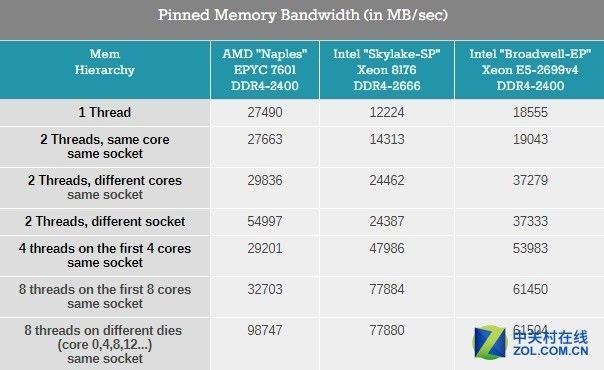
内存带宽在不同线程下的反映
新的Skylake-SP提供的单线程带宽很一般:虽然测试中用了更快的DDR4-2666内存但是只有12GB/s。
而Broadwell-EP用了更慢的DDR4-2400内存却能拥有50%更多的带宽,很显然Skylake SP需要更多的线程来获得尽可能多的可用内存带宽。
再来看AMD这边,如果需要的话,Naple核心的单线程可以达到27.5GB/s。
这非常有前途,这意味着在单线程层面,HPC的应用可以获得充沛的带宽从而运行程序足够快,但是一个四核心的CCX可以调用的带宽只有30GB/s。
总体来说,英特尔Skylake-SP Xeon的内存带宽表现相比EPYC更加线性,所有的Xeon核心都可以访问所有的内存通道,因此内存带宽直接根据线程数提升。
内存延迟和子系统测试
现在的CPU性能很大程度上取决于缓存子系统,有些应用也非常依赖内存子系统,在这方面可以通过LMBench来评估缓存和内存的延迟。
设置的数据为"Random load latency stride=16 Bytes(随机负载延迟幅度= 16字节)" 结果如下:
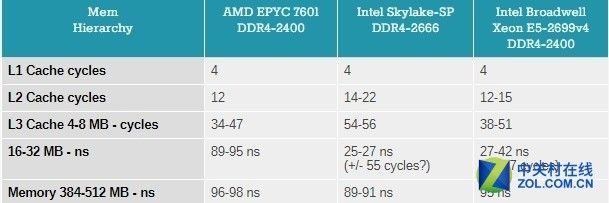
缓存测试
有人形容AMD的Infinty Fabric将两个CCX封装一个Die上,而在一个MCM中四个不同的Zeppelin Die相互连接。对于Naples来说,将两个CCX封装在一个 Die上肯定不是最佳选择。
访问本地"嵌在CCX内的"8MB 3级缓存延迟非常低。但是一旦核心需要访问另一个3级缓存块时,即使在同一个Die上,Unloaded延迟也会非常糟糕。
这只比访问内存的延迟好一点,所有目前推出的CPU在访问内存的进程都有很高延迟。信号需要从内存控制器到内存总线,而DDR4-2666内的内存矩阵只运行在333MHz频率上(因此DDR4的CAS延迟非常高),所以令人惊讶的是on-chip fabric访问SRAM需要这么多周期。
这对最终用户意味着什么呢?64MB的3级缓存在规格表上并不真的存在,实际上即使是在单一的Zeppelin Die上的16MB的3级缓存也是由两个8MB的3级缓存组成。在MCM上没有真正单一且统一的3级缓存,而是8个独立的8MB三级缓存。
对于占用空间适用于8MB 3级缓存的应用来说表现很好,像是虚拟机(JVM,虚拟机只依赖于一个)还有HPC/大数据应用并行运行在不同的数据块内(比如map/reduce中的map),然而这样的设计对于那些需要"核心"访问一些大得数据池的应用来说肯定会有损害,比如在数据库应用和大数据应用的"Shuffle Phase"操作。
内存子系统测试
为了再次确认延迟测试并更深入的了解各自的架构,因此AnandTech使用了开源测试软件TinyMemBench,源代码是由x86的GCC 5.4编译,优化级别设置为"O3"。
TinyMemBench的操作手册对于测试有个很好的解释:
随机内存访问不同大小缓存的平均时间会被检测,越大的缓存对TLB,一级二级缓存丢失和DRAM访问的的相对贡献越大。所有的数字代表额外的时间,需要增加一级缓存的延迟(4个周期)。
通过测试双随机读取,可以看到内存系统是如何成功应对多个读取需求的。
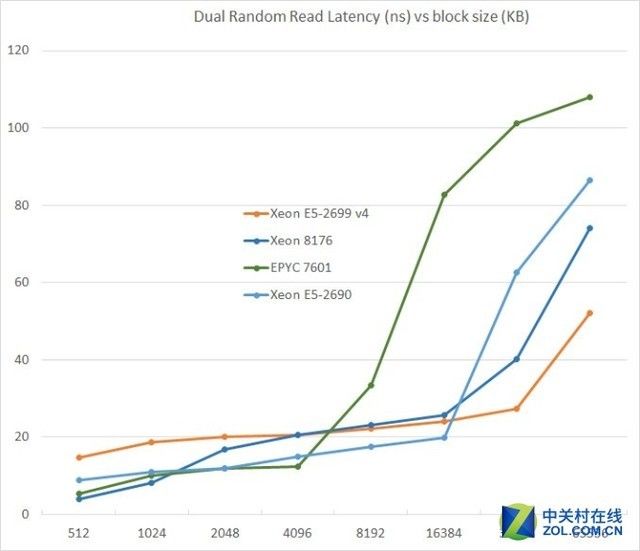
不同大小数据下的延迟表现
近几年来,CPU的三级缓存的大小一直在稳步增加。Xeon E5 v1有20MB,v3升到45MB,v4的"Broadwell EP"进一步增加到55MB,但是越大的缓存造成了越大的延迟。
从Sandy Bridge-EP到Broadwell-EP,三级缓存的延迟翻了一倍。所以难怪这次Skylake把二级缓存增大并用了更快且更小的三级缓存。这让512KB的测试中二级缓存的延迟降低了4倍。
AMD的unloaded延迟在8MB以下的测试中表现出非常强的竞争力,相对以前的AMD服务器CPU来说是一个巨大的飞跃。
但不幸的是在8MB以上的表现相比Broadwell核心访问内存的延迟更加糟糕。而在缓慢的三级缓存访问测试中,AMD的内存访问速度依然是最慢的。
Unloaded延迟的重要性当然不应该被过分夸大,不过对于指针追踪和其他对延迟比较敏感的应用来说依然是个坏消息。
单线程整数运算性能:SPEC CPU2006
即使在服务器市场也是高核心数的CPU称雄。单线程高性能表现依然值得拥有。
它确保在任何情况下都能保证一定的性能发挥,而不是仅仅为了"embarrassingly parallel(易并行计算)"软件的"throughput situations"(吞吐情况)
SPEC CPU2006以HPC和工作站为主,它包括了针对整数运算的各种工作负载测试。
为了尽可能贴近一些关键软件的编译性能,而不是试图去达到更高的分数。因此在测试时:
使用64位的GCC:目前为止Linux使用最多的针对整数工作负载的编译器。
好且全面的编译器是不会试图破坏测试(libquantum…)或者偏向某一架构。
使用版本号为5.4的GCC:Ubuntu 16.04 LTS标配编译器(注意一点,在早期的文章中使用的是4.8.4)
使用-Ofast -fno-strict-aliasing优化:在性能和保持测试简单之间达成一种平衡。
增加"-std=gnu89"可移植性指令来解决在一些测试中GCC5.x编译器中无法编译的问题。
运行一次测试。
这个测试的终极目标是在"非积极优化"的应用测试中测试性能,因为一些原因,"对多线程不太友好的"测试一直让我们拭目以待。
首先是单线程测试结果,很重要的一点是感谢现在的Turbo技术,所有的CPU相对基础频率来说都运行在更高的频率上。
The Xeon E5-2690 ("Sandy Bridge")能够加速到3.8GHz
The Xeon E5-2690 v3 ("Haswell")能够加速到3.5GHz
The Xeon E5-2699 v4 ("Broadwell")能够加速到3.6GHz
The Xeon 8176 ("Skylake-SP") 能够加速到3.8GHz
The EPYC 7601 ("Naples") 能够加速到3.2GHz
首先让我们单纯看一下数字。
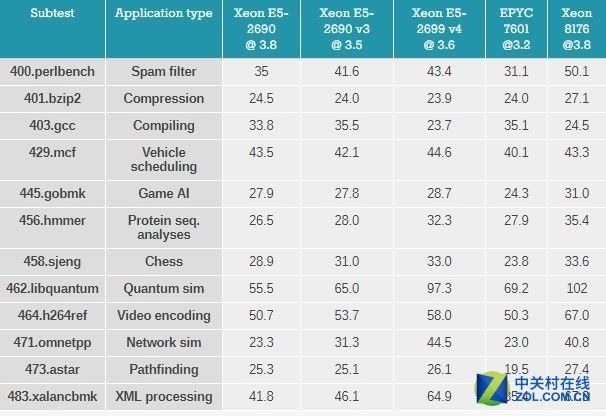
测试结果
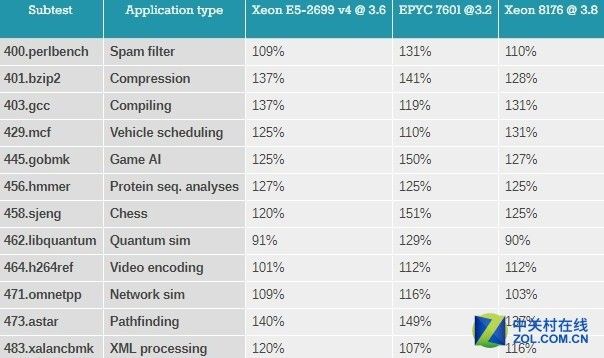
原始的SPEC数据在密密麻麻的数据表中处理起来很费劲,因此用百分比的方式来对比基础数据看起来更直观。
Sandy Bridge EP(Xeon E5 v1)已经有五年历史了,由于定位为将要被取代的服务器芯片,因此用它的数据作为100%的的基准,然后去对比其他架构的单线程性能。
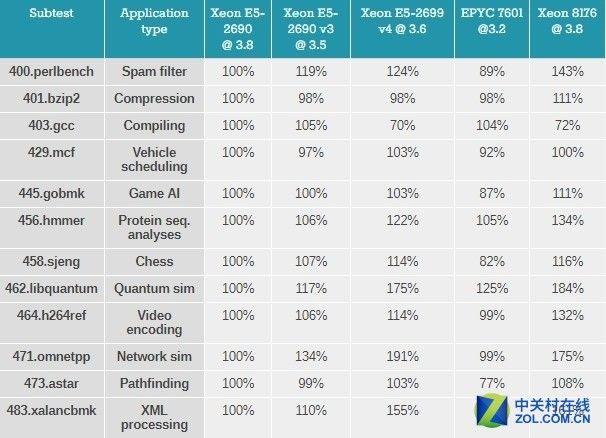
测试结果对比
首先是评估不同架构的IPC(Inter-Process Communication,进程间通信)效率。
考虑到EPYC的核心运行频率相比英特尔低12-16%的情况下取得了90%左右的性能,因此可以理解为Zen架构的IPC性能很强。
作为英特尔最新的CPU,需要注意到Sky-lake SP核心拥有相对上一代"Broadwell"更大的二级缓存所带来的影响,特别是在perlbench,gobmk,hmmer和h264ref项目上取得的优势。
同时,由于新的GCC 5.4编译器,英特尔在"403.gcc benchmark"的表现可视为新架构的一种退步。
虽然Xeon E5-2699 v4的表现相对"Sandy Bridge"架构的Xeon E5-2690只有83-95%,但这一次进一步倒退到70%。
另一方面,AMD的Zen核心在运行GCC时表现的非常出色。在混合指令占据高百分比((比较容易预测)的分支指令中,比如,在占用的空间更小,并且对低延迟(大多数是L1/L2/8MB L3)依赖较高的指令表现很好,在对分支指令预测影响更高的工作负载中(某种程度上更高比例的分支指令丢失)-gobmk,sjeng,hmmer-在"Zen"上运行的也很好,相比上一代AMD架构,分支指令预测错误惩罚要明显更低,这些都要感谢uop缓存。
另外在指针追逐测试中-XML处理和路径查找需要更大的三级缓存,这是EPYC表现最差的项目。
还需要注意的是事实上在低IPC omnetapp(可理解为互联网的sim卡)项目上,Skylake-SP要比Broadwell慢,不过依然比AMD的EPYC要快。
Omnetapp受益于Broadwell巨大的三级缓存,这就是为什么在Skylake-SP上会出现性能下降的情况。
当然,这也意味着AMD EPYC处理器那种拆分式的8*8MB 三级缓存表现的要比英特尔最新的CPU慢很多。这个结论同样在视频编码基准测试"h264ref"项目上同样符合。
但是编码测试更看中DRAM带宽。事实上因为EPYC拥有更高的DRAM带宽确保其不会落后英特尔太多。
总而言之,Zen架构在单线程的表现是出色的,但是对于较低的Turbo频率和"更小"的8*8三级缓存上还是感到有点失望。
SPEC CPU2006 SMT整数性能测试
接下来是测试单核心上的SMT(simultaneous multithreading,并发多线程)性能。通过在同一个核心上同时使用两个线程进行测试,可以评估核心是如何处理SMT的。
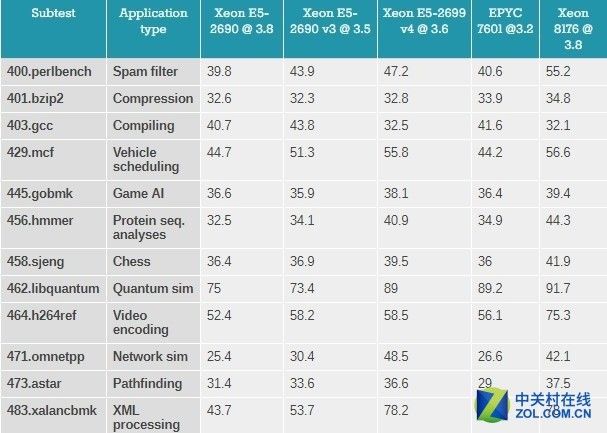
SMT性能
用百分比的方式来对比单线程的测试结果,可以看出启用SMT后有多少性能提升。
对比结果
平均而言,Xeon E5-2699 v4和Xeon 8176由于SMT都提高了20%(超线程),而EPYC 7601提升更大,差不多提高了28%左右。有很多可能可以用来解释这一现象 ,但其中两种可能性最大。
在AMD EPYC单线程IPC非常低的情况下,由于超过了三级缓存(>8MB)因此延迟较高需要等待,第二个线程可以确保CPU能够更好的被利用起来(比如压缩,和网络SIM)。
第二个可能性是,可以看到AMD核心能够在轻线程场景下调用更多的内存,这对于测试中更看重内存的部分(比如视频编码,量子sim)起到帮助。不管怎样,光AMD确实让吞吐量得到了提升。
SPEC CPU2006多核测试
SPEC CPU"速率"数据对于评估服务器CPU性能没有太大价值,因为大多数应用程序不会并行运算很多完全独立的进程,至少会在线程中有一些交互。
但此前AMD官方放出来的宣传图曾引起了市场的争议。EPYC 7601是否真的在整数运算上有领先47%的实力?通过测试可以知道答案。
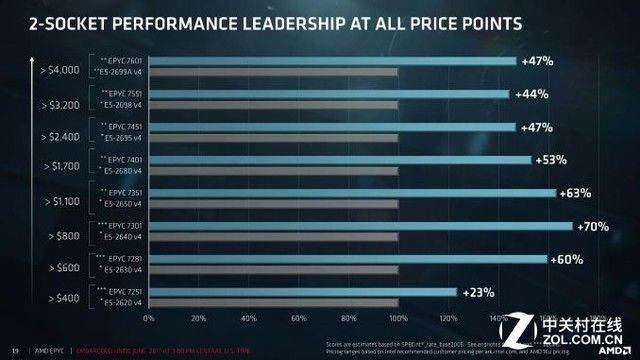
AMD官方放出来的数据曾引发市场争议
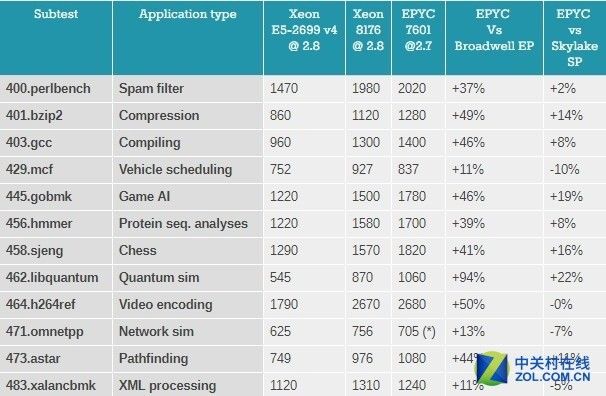
多核性能测试对比
在AnandTech的测试中,所用的是47.omnetpp线程数设置为64,因为如果设置为128则会报错,根据AnandTech的估计,因为如果设置为128则性能还可以提升10%到20%。
需要提前声明的一点事:SPECint的比例测试可能是不切合实际的。
如果启动88到128个实例,就会创造出一个巨大的带宽瓶颈,而且CPU的负载一直在100%。这两种可能性在大多数的整数应用程序中都不太现实。
再加上没有同步进行,这对于像AMD EPYC 7601这样的服务器CPU来说是一种非常理想的情况。
比例测试或多或少的对整数处理的峰值性能做出评估,忽略了在大多数整数应用程序中存在的细微的可伸缩性问题。
不过,AMD的说法还是靠谱的,就平均而言,使用合理设置的"中立"编译器,AMD 7601相对Xeon E5-2699v4拥有40%(在Omnetpp可以取得42%的性能优势,一旦修复了128位线程错误)的整数性能优势,甚至比Xeon 8176还要快6%,不要期望这些数据可以真的在大多数的整数应用程序中实现,但它显示出AMD取得了多大的进步。
多线程整数性能测试
虽然单纯的压缩和解压缩并不是真实世界中的测试部分(至少在服务器领域),但是目前越来越多的服务器工作中的很大一部分职责就是负责这些工作(比如数据库压缩,网站优化) 。
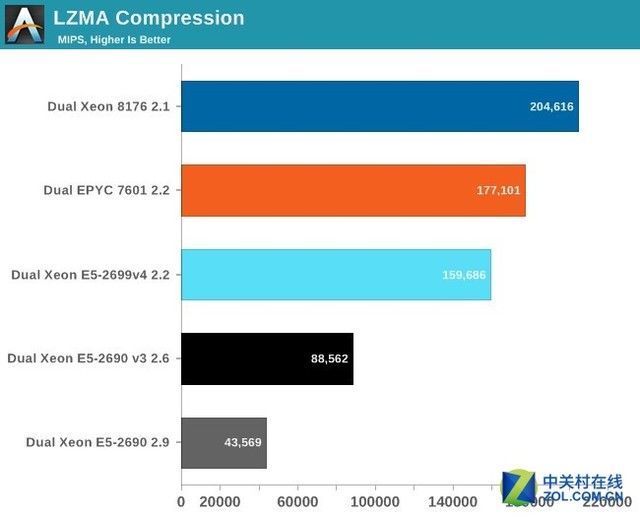
压缩测试分数越越好
压缩很依赖缓存,内存延迟和TLB((Translation Lookaside Buffer)转换检测缓冲区)效率。
这对于AMD的EPYC来说绝对不是一个理想的情况。最好的AMD CPU相比上一代英特尔Xeon拥有几乎多达50%的核心,但是在性能上只提高了11%。
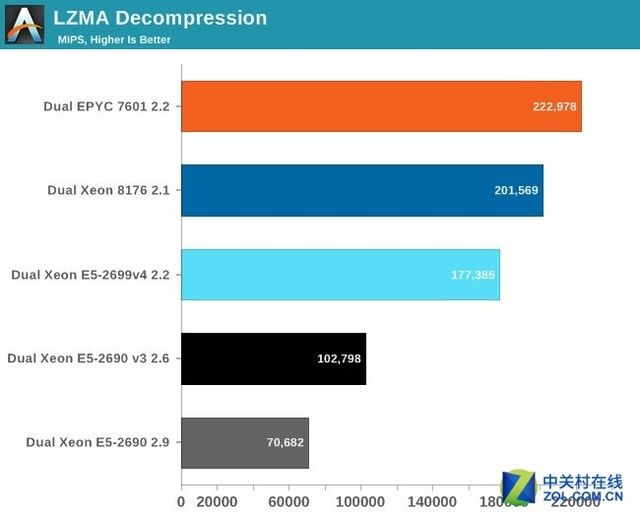
解压缩测试分数越高越好
解压缩对应较少的整数指令(移位、乘法)。英特尔和AMD的核心在处理这些整数指令上看起来很类似,但AMD的芯片多了4个核心。多出这14%的核心数带来了10%的解压性能提升。
数据库性能测试
在数据库测试中,AnandTech使用的是Percona Server 5.7,增强了Drop-in的MySQL。而测试工具是,Sysbench 1.0.7,相比之前0.4,0.5版本更加高效。
在测试中使用Read-Only OLTP Benchmark,尽管有点不贴近现实。但仍然比其他的Sysbench测试要有趣得多。这能够在不产生I/O瓶颈的情况下测试CPU的性能。
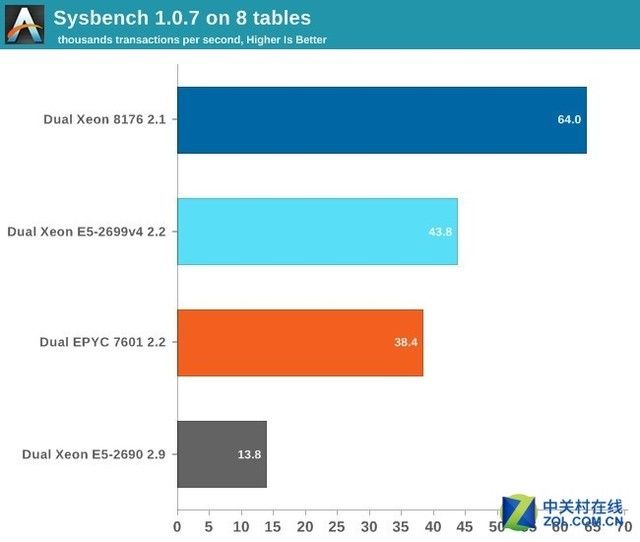
得分越高越好
正如预期的那样,EPYC在数据库项目上无法拥有的高性能表现。一个小型数据库大多需要存在三级缓存中成了EPYC最糟糕的场景。就是说,需要相当多的调试。
根据AMD的说法,如果启用了内存交叉性能应该可以提升一些(10%-15%?),总的来说,EPYC在事务性数据库的表现很平庸。如果配合比较好的调教它也许可以超过Xeon v4,但距离冠军8176还差的远了一些。
这使得测试EPYC在非事务性数据库(文档存储,Key-Value)的表现变得很有趣,但是传统的事务性数据库领域依然是英特尔的天下。
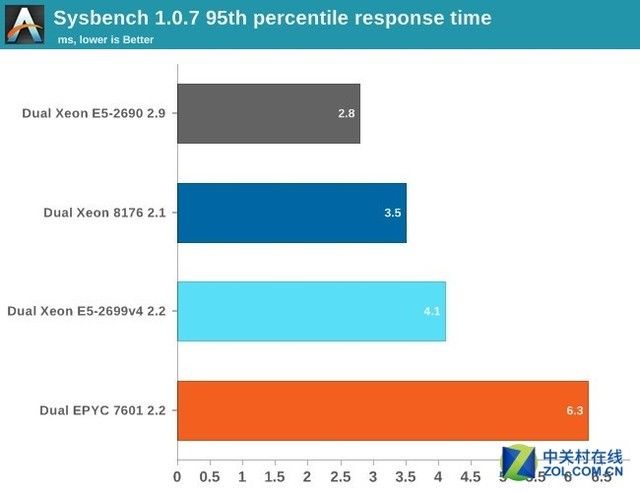
通常在由于响应时间很高被报告的时候,会表现出低单线程性能。然而EPYC不是这样,在测试一个比8MB三级缓存大一点的数据库时的响应时间高可能是因为三级缓存的延迟所致。
Java性能测试
SPECjbb 2015 Benchmark的测试模块来源于"面向全球市场的超市零售公司所使用的可以处理销售需求,在线交易和数据IT架构",测试模块使用了最新的JAVA7的特性来实现XML,通信压缩和信息安全。
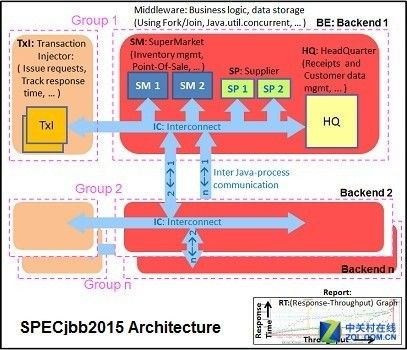
SPECjbb2015 架构
通过设置4组事务注入器和后台的场景来通过SPECjbb测试,我们之所以用"Multi JVM"测试是因为这更贴近现实:服务器上有多个VMs是很常见的做法。
Java版本为 OpenJDK 1.8.0_131,在测试中采用了相对基础的调教来模拟真实世界,即目标为所有东西都装在128G RAM的服务器内。测试指令如下:
“-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:+UseLargePagesIndividualAllocation”
下面这张图显示了在MultiJVM SPECJbb测试中最大的吞吐量。
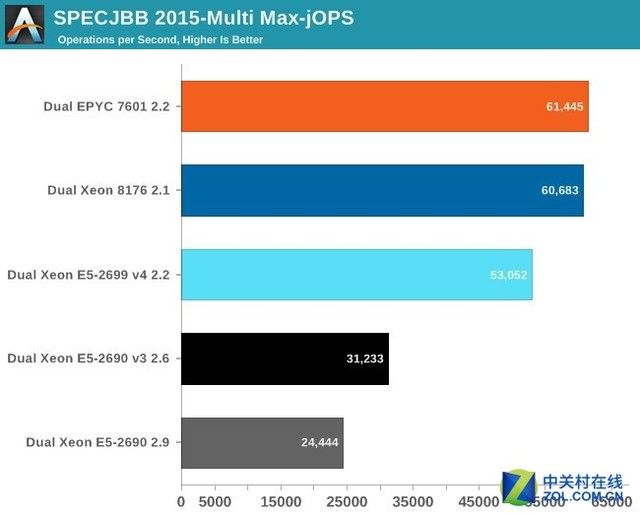
Java性能测试
虽然这个测试对于AMD来说不是最理想状况(在现实中可能会选择8个甚至16个后台),但是EPYC还是稍微超过了Xeon 8176,使用8个 JVM让差距从1%扩大到4-5%。
Critical-JOPS的测量标准是在限定的响应时间内的吞吐量。
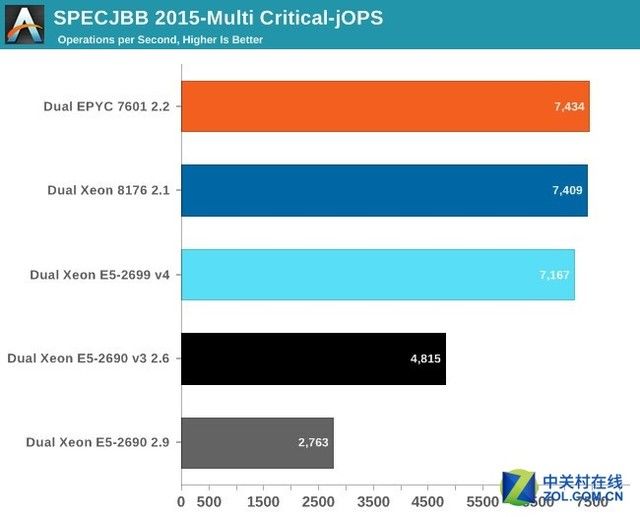
CriticalJOPS测试,结果越高越好
在当前活跃线程数的情况下,可以通过增大每个JVM的内存来获得更高的Critical-JOPs。
大数据测试
Apache Spark是大数据处理的代表。大数据应用加速,因此在这个环节中AnandTech利用Aparche Spark的很多特性来进行测试。

Apache Spark测试
上图是对这个测试的说明:首先从Common Crawl的压缩300GB数据开始。这些压缩文件主要是大量的网络档案,通过Java 库中的"BoilerPipe"提取出有意义的文档数据。
使用斯坦福CoreNLP自然语言处理工具,从文本中选择目标(有含义的单词)。然后计算哪个URL中出现这些目标的次数最高,然后使用交替最小二乘法算法来推荐哪一个URL对于确定的主题最接近。
在过去的大量CPU测试中,SPARK 1.5在独立模式下(Non-Cluster,非集群)的结果非常好,但随着核心数的上升结果呈现了递减的态势。
只在一个JVM里来释放300GB压缩数据对于超过30核心的系统来说不是很适用,比如具有高核心数的Xeon 8176和EPYC 7601。根据AnandTech的说法,第一次用这种方式测试的时候出现了很严重的性能问题。
64核心的EPYC 7601表现的像是16核心的Xeon。而56核心的Sky-lake SP系统也就勉强强过24核心的Xeon E5 v4。显然,需要另一种测试方法。
因此,最后AnandTech将服务器后台变成虚拟集群。第一次的尝试是4个executor。
于此同时,也通过工程师将Apaache benchmark升级到可以支持Apache Spark 2.1.1.
Apache Spark测试
接下来是结果:
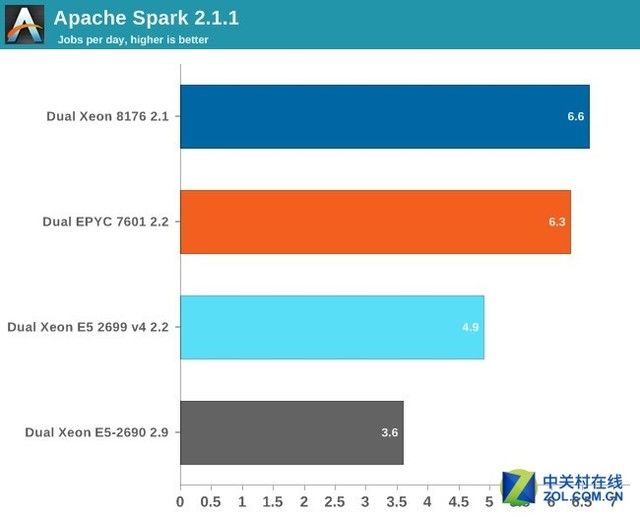
分数越高越好
如果你想知道除了需要虚拟化几十个虚拟机的人以外,谁还需要这样的服务器怪物的话,答案自然是是大数据。
大数据分析对于整数处理性能的需求是永远填不饱的。即使在AnandTech最快的机器上,这个测试大概也需要四个小时来完成,这毫无疑问是一个杀手级应用。
Spark测试需要大概120GB内存来运行。存储I/O上花费的时间是可以忽略的。
数据处理非常并行,但是在数据清洗过程中需要大量的内存交互,ALS阶段在很多线程上的扩展不是很好,但只占了不到4%的整体时间。
鉴于更高的时钟频率在轻线程和单线程部分,更快的清洗阶段让英特尔领先了仅仅5%左右。
而从这一点也能看出两者均针对大数据这一服务器市场的热门应用场景进行了深度的开发和优化
浮点运算性能测试
AnandTech通过C-ray,POV-Ray和NAMD来测试他们的浮点运算性能,C-ray用来测试1级缓存,POV-Ray用来测试2级缓存,AMD用来测试内存子系统。
C-ray测试
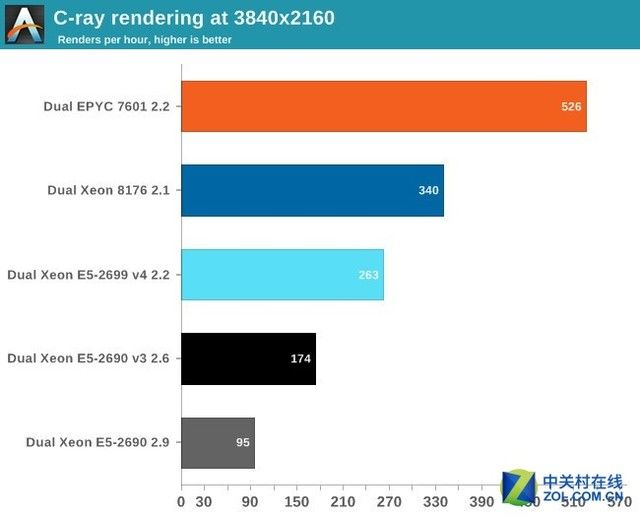
C-ray是一个非常简单的光线跟踪源工具,它不是真实世界中的光线追踪应用。
事实上,它本质上是一个运行在1级缓存中的浮点基准测试工具。在测试中使用标准的测试分辨率(3840*2160)并用"sphfract"文档来衡量性能,代码预编译过。
C-ray测试结果
从结果来看,AMD的EPYC取得了极大的优势,相对竞争对手的优势不少于50%,当然,如果是所有数据都位于一级缓存的话那么很容易提供给FP部分,接下来是POV-Ray。
POV-Ray测试
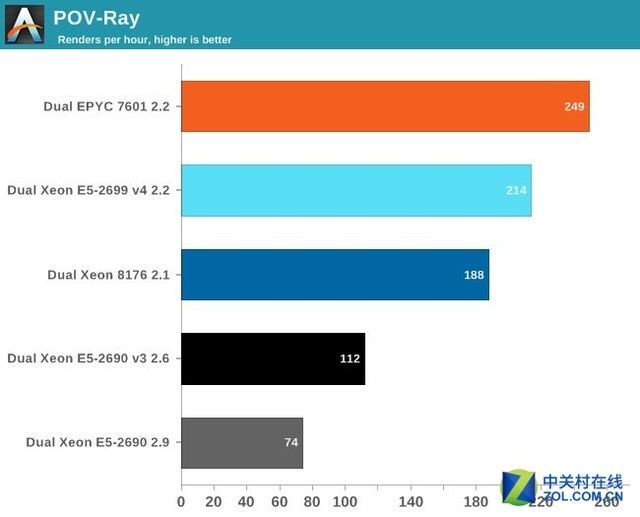
POV-Ray是一个非常著名的开源光线追踪程序。测试用编译的版本基于在github(https://github.com/POV-Ray/povray.git)中找到的。没有进行特殊的优化,采用"prebuild.sh"来进行配置和安装。
POV-Ray测试
众所周知,POV-Ray主要运行在二级缓存中,因此EPYC核心拥有的巨大的内存带宽在这里发挥不出大作用。
然而,EPYC的性能是非常惊人的,相对Xeon 8176快了16%,但如果加上AVX和内存访问呢?
NAMD测试
伊利诺伊大学香槟分校理论和计算生物物理小组开发的NAMD都是针对并行分子动力学的代码,主要面向上千个内核上的极端并行情况。NAMD也是SPEC CPU2006 FP的一部分。
相比以往的FP测试,NAMD的代码通过为AVX优化过的英特尔的ICC来编译,这理论上会给英特尔带来一定的优势。
首先,使用"NAMD_2.10_Linux-x86_64-multicore"指令。并用最流行的测试负载,apoa1(Apolipoprotein A1),结果用纳秒来评估,测量500步。

NAMD
再一次,EPYC 7601用41%的压倒性优势战胜了英特尔的28核心。英特尔在运行重矢量代码(比如linpack)时可能要快很多。但是AMD最新的处理器运行其他的FP代码更快。
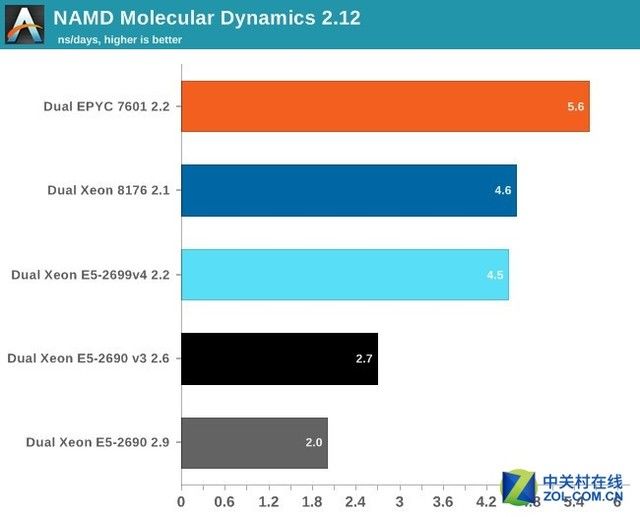
我们在第一次测试中使用2.10版本这样可以对比我们过去的数据。2.12版本似乎可以更好的使用到英特尔的特性(英特尔的编译器在矢量化和自动调度上已经为支持AVX指令集提高了性能)
NAMD 2.12测试
最老的Xeon性能看起来有25%的提升,而对于新的Xeon来说提升就变少了一些,大概在13-15%左右。
值得注意的是,新的代码在EPYC 7601上运行要慢了4%。三种不同的FP测试指向了同一个结果:Zen可能无法实现理论上最高的浮点运算峰值性能,但是大部分浮点运算代码在EPYC上运行的最好。
能源测试和最终结论
能源测试
AnandTech在之前的测试中还顺手对服务器的能耗进行了一分钟测试。第一个场景是MySQL中表现最好的时候:在响应时间明显提高以前,吞吐量最高的时候。第二个是测试浮点运算性能,POV-Ray调用所有可用线程的时候。
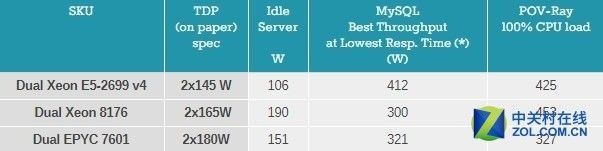
EPYC的实际能耗显然比英特尔低不少
Xeon 8176和双路EPYC相比双路Xeon E5-2699v4系统都有一些额外的部分(比如一个独立的的10GbE网卡),但这并不能解释为何空载功率那么高,特别是双路Xeon 8176。
目前比较浅显的结论是:EPYC 7601在运行整数运算的时候可能需要更多的能源。而英特尔CPU的众多的FP单元是真正的耗电大户,即使在不需要运行重AVX应用的时候依然耗电不少。
最终结论
从测试结果来看,AMD EPYC确实拥有和英特尔最新的Xeon可扩展处理器家族一战的实力。
虽然受制于MCM的封装方式和结构,在内存延迟和数据库依然无法战胜Xeon,但是在不少环节中都大幅领先竞争对手,包括 一直被人诟病的功耗问题,也表现亮眼,也难怪AMD此次信心十足。
但不可否认的一点,英特尔的优势除了架构、工艺和指令集外,其生态的成熟度是目前AMD无法比拟的。
对于最终购买用户来说,如果没有足够的技术实力来调试EPYC让其在运行程序时发挥出最大的性能,Xeon依然是很好的选择。
不过对于云计算服务商来说,由于拥有调试EPYC的技术实力,再加上EPYC的高性价比(如果考虑到每美元对应的性能,显然EPYC要比Xeon更有吸引力),EPYC已拥有替代Xeon的性能表现,这也是为何英特尔这次会重视AMD。
AMD的复兴之战才刚刚开始,而未来是否能继续稳步提升表现我们尚不得知,但我们可以看到,伴随着双方的激烈竞争,最终受益的是用户,因此我们非常期待接下来双方的进一步动作。











