机器之心原创
作者:Liao
参与:Joni、Nurhachu、黄小天
近日,加利福尼亚大学和 Adobe Research 在 arXiv 上联合发表了一篇名为《生成人脸修复(Generative Face Completion)》的论文,论文中的模型包括包括一个生成器、两个鉴别器以及一个语义解析网络,可针对缺失图像直接生成局部或整张的逼真图像。此论文已被 CVPR 2017 接收,机器之心对该篇论文做了扼要介绍和解读。论文链接请移步文末。
论文作者及单位:

1. 简介
这篇论文提出了一个用来进行人脸修复的深度生成模型,如下图所示,针对一副面部图片中的缺失区域,这个模型可以直接修复人脸。

与之前很多其他工作不同,针对人脸修复任务,这篇论文的作者同时使用了两个鉴别器来构建整个模型,因此不论是局部图像还是整个图像,看上去都更加逼真。
2. 方法
2.1 模型结构
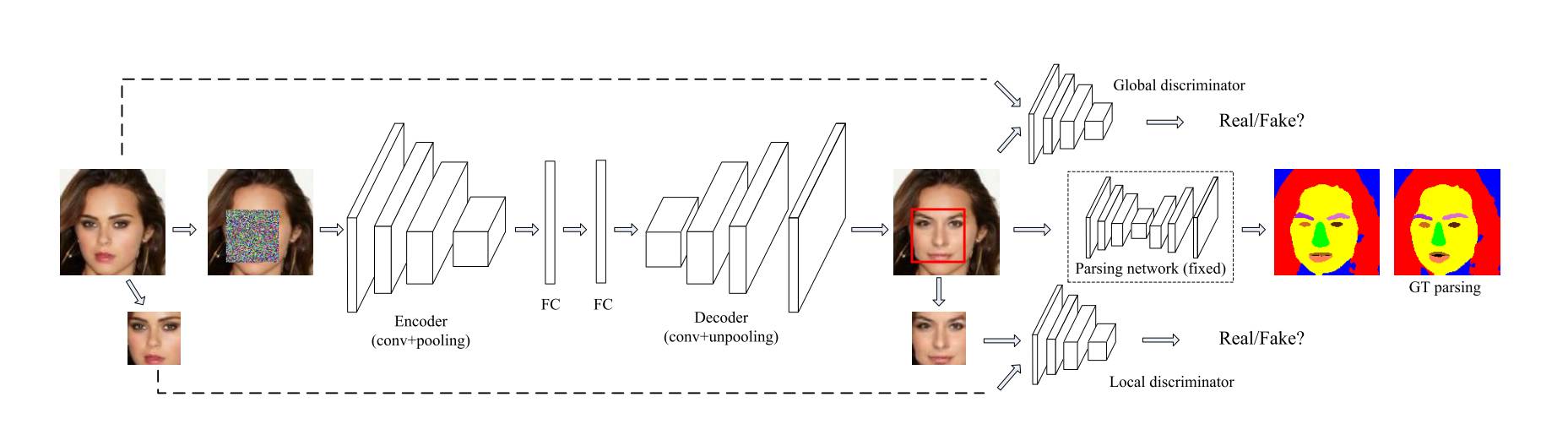
如上图所示,整个模型包括一个生成器、两个鉴别器以及一个语义解析网络。
这个项目中的生成器是一个基于 VGG-19 的自动编码器。此外论文作者还构造了两个卷积层,并在顶部有一个池化层,然后在后面加了一个全连接层作为编码器。解码器具有反池化层,结构与编码器对称。
局部鉴别器被用来判别图像缺失区域中合成的图像补丁是否真实。整体鉴别器则用来判别整张图像的真实性。这两个鉴别器的架构相似于论文《用深度卷积生成对抗网络来进行非监督表征学习》中的所述架构。
语义解析网络用于改进上述生成对抗网络生成的图片,语义解析网络是基于论文《使用全连接卷积编码-解码网络进行物体轮廓检测》,因为这种网络能够提取到图像的高水平特征。以这种方式,生成的图像补丁 (人脸部分) 会具有更加自然的形态和尺寸。
2.2 损失函数
生成器中的重建损失函数 L_r 计算生成器的输出和原始图像之间的 L_2 距离。
两个鉴别器共享定义相同的损失函数 L_ai,如下图方程所示,L_ai 经常用于生成对抗网络。
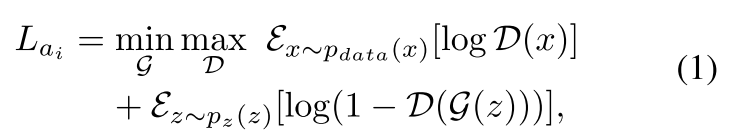
两个鉴别器的损失函数的不同之处在于:局部鉴别器的损失函数 (L_a1) 仅仅反向传播图像缺失区域的损失梯度,而整体鉴别器的损失函数 (L_a2) 反向传播整个图像的损失梯度。
解析网络的损失函数 L_p 是以像素为单位的 softmax 损失,softmax 也是很多其他分类神经网络中常用的损失函数。
综上所述,整个模型的损失函数定义如下:
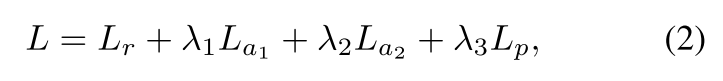
对网络的训练,论文作者将过程划分为三个阶段。第一阶段,仅仅用 L_r 来训练网络以重构图像。第二阶段,用局部对抗损失来对网络进行微调。第三阶段,使用全局对抗损失和语义正则化获取最终结果。
3. 实验结果
正如本文第一张图像所示,生成人脸修复算法有着非常好的结果。图 7 展示了这个模型对不同种类的遮盖有着很好的鲁棒性,它和现实应用非常接近。无论什么形状的遮盖,网络都能生成令人满意的结果。

图 7. 脸部修复。在每一组,左边:被遮盖部分的人脸输入,右边:修复结果
如图 9 所示,作者还对比了遮盖大小对结果的影响。他们发现,在遮盖中等大小的时候,存在一个性能的局部最小值。因为当遮盖是这个尺寸的时候,它很可能遮住一张人脸的五官之一 (如鼻子、眼睛......),而这种情况对这个模型来说是很难合成的。
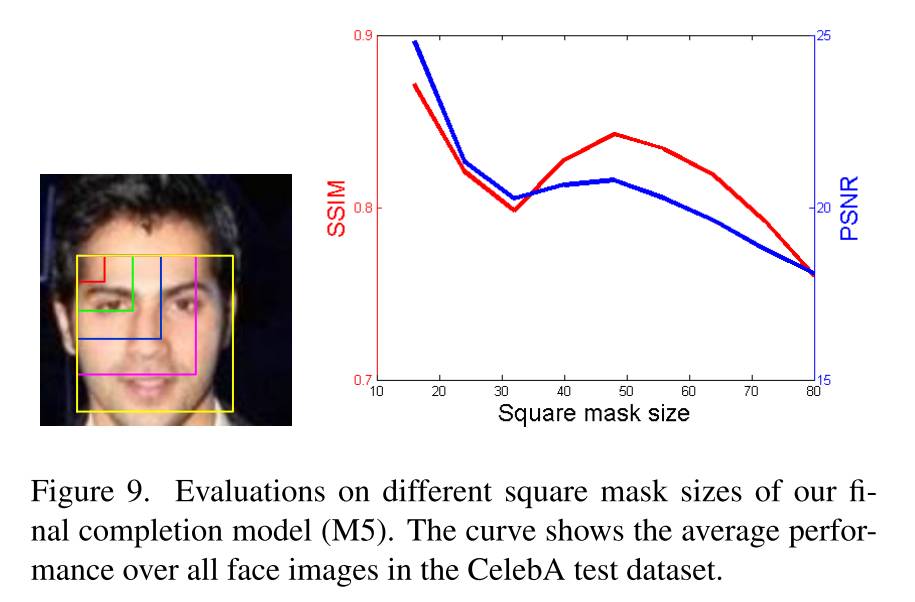
图 9:不同尺寸的正方形遮盖下模型的性能评价。曲线展示了在 CelebA 数据集上的所有图像中模型性能的平均值。
图 12 展示了这个生成模型的局限性。首先,尽管这个模型包含了语义解析网络,它在训练过程中能够获得一些高层次的特征,但是它并不能识别人脸的位置和方向。所以,这个模型不能处理那些未对齐的人脸。第二,如上所述,对这个模型而言,生成人脸的局部要比生成整张人脸要困难,因为这个模型不能总是检测到相邻像素之间的空间关联性。

图 12 模型的局限性。上排:在没对齐的图像中,我们的模型未能成功地合成人眼。下排:仍难生成正确属性的语义部分 (例如,红色唇彩)。
5. 结论
这个基于生成对抗网络的模型具有两个鉴别器和一个语义正则化网络,能够处理人脸修复任务。它能够在随机噪声中成功地合成缺失的人脸部分。
6. 点评
整体评价:
这篇论文提出了一个在人脸修复任务上有成功实例的生成模型。论文作者从数量和质量两个方面评估了其模型,因此结果相当可信。
这篇论文的贡献:
他们提供了一个设计生成对抗网络模型的新方式:同时使用多个鉴别器达成不同目标。例如,传统的自编码器使用 L_2 距离来重构图像,所以经常输出非常平滑的结果。之前的工作经常使用从深度分类神经网络中得到的映射向量来改善这个结果。但是在这篇论文中,作者证明使用不同的鉴别器也能够得到更低的平滑度,从而结果更好。
论文作者把训练过程分成了几个阶段,这对训练生成对抗网络而言确实是一个好想法。这就像人类学习的方式:人们首先学习一个物体的轮廓 (和这个项目中的图像重建类似),然后一步一步地学习每一部分的细节 (类似于这个项目中第二阶段的微调以及第三阶段)。
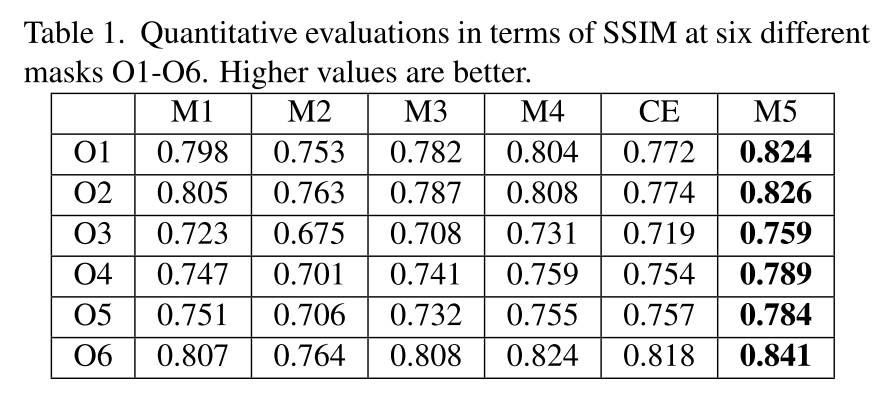
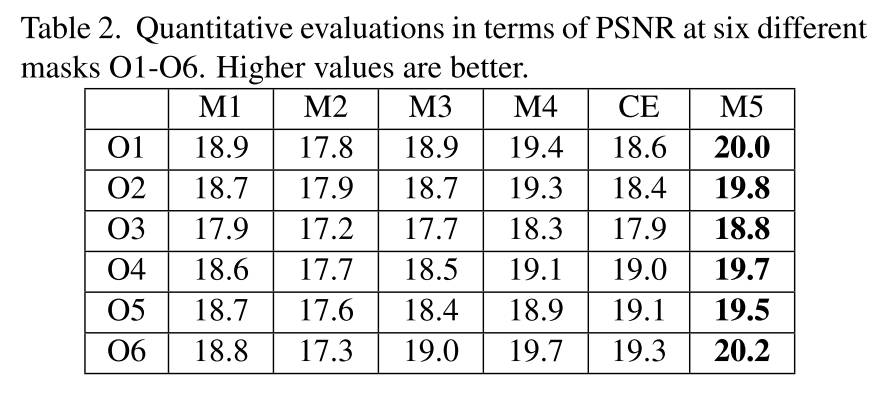
论文作者还证明了「峰值信噪比 (PSNR)」和「结构性相似指数,SSIM」不足以评价重构或生成结果,因为这两个指标是倾向于平滑和模糊的结果。如图 3、表 1 和表 2 所示,子图 M1 比 M2 和 M3 具有更高的 SSIM 和 PSNR。但是 M2 和 M3 明显具有语义层面更加合理的生成结果。
这篇论文还证明,语义解析网络能够在生成对抗网络的随机噪声上提供一些额外的 (语义) 限制,以得到更加逼真的结果。图 10 还展示了这些限制使得生成对抗网络能够识别人脸的组成部分,因此生成对抗网络能够在不同的随机噪声中以相似的形状和尺寸生成人脸的缺失部分,仅仅在一些细节上有差别,例如眉毛的阴影。


改进建议
这个模型一个局限是并不能处理一些未对齐的人脸,可以增加一个面部变形的网络来将输入的人脸规范化。
使用其他类型的图像 (如建筑或风景) 来训练这个模型,来判断其对其他类型的修复任务是否具有鲁棒性。 
参考文献
[1] Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
[2] Yang, Jimei, et al. "Object contour detection with a fully convolutional encoder-decoder network." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
论文链接:https://arxiv.org/abs/1704.05838
点击阅读原文,查看全部嘉宾阵容并报名参与机器之心 GMIS 2017 ↓↓↓









