有些浏览器的数据并不好爬,比如需要登录后才能访问指定网页,或者先检测浏览器是否支持JS或者需要预先加载JS脚本才能浏览。对于这类网站,我们得请出神器
selenium
!selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。一起来看看selenium在R中的应用。
点击查看之前爬数据库的文章:
使用R语言爬取Pubchem药物信息
使用R语言爬取DailyMed药物信息
R语言批量爬取NCBI基因注释数据
还是以上期的
pubchem
数据库为例,如果直接使用
Rcurl
、
rvest
、
XML
来爬的话,你会发现你爬下来的完全不是想要的,比如药物
9
-
Cis
-
Retinoic
20Acid
,其在pubchem中的页面如下:
 我们使用常规方法爬取,根据页面链接获得此页面的所有内容并保存到
我们使用常规方法爬取,根据页面链接获得此页面的所有内容并保存到
test
.
html
:
library(XML)
library(RCurl)
doc getURL("https://pubchem.ncbi.nlm.nih.gov/compound/9-Cis-Retinoic%20Acid")
writeLines(doc,"./test.html")
打开上面爬取的页面
test
.
html
,结果是这样的:
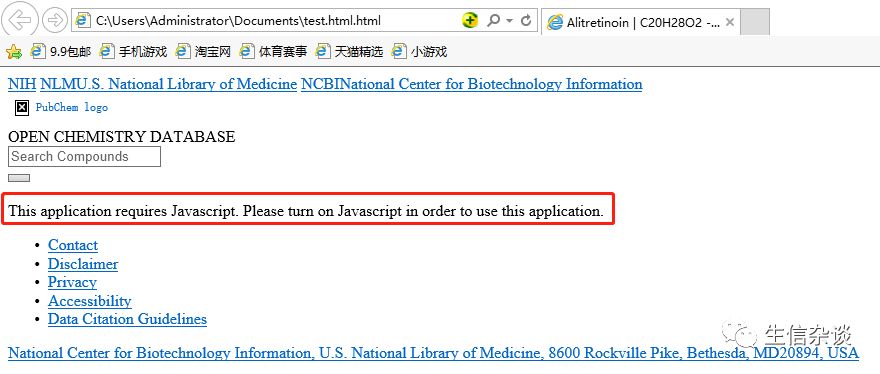 也就是说在爬取此页面时,
也就是说在爬取此页面时,
pubchem
服务器先检测你的浏览器是否能执行JS,如果不行的话,你就给劳资爬开吧。 但我们不能爬开,我们还是要爬!
操作如下:
首先是
Selenium
Server
及相关依赖的安装:
-
安装Java运行环境,因为用到的
Rseienium
是个
jar
包,下载链接如下: http://www.oracle.com/technetwork/java/javase/downloads/index.html,安装JDK后记得修改环境变量,不会百度之。
-
下载
selenium
-
server
-
standalone
-
3.9
.
0.jar
文件,下载链接如下: http://selenium-release.storage.googleapis.com/index.html。
-
下载Google浏览器,并默认路径安装。
-
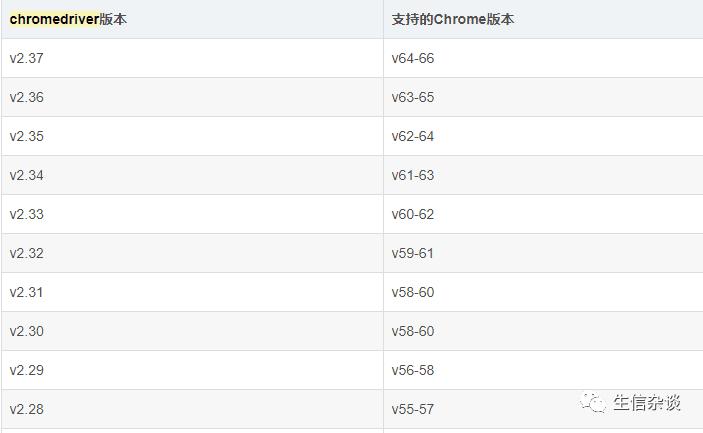
下载
ChromeDriver
用来驱动Google浏览器,其版本映射表如下:
-
将
ChromeDriver
.
exe
放置在
chrome
.
exe
同一目录下,如果默认安装Google浏览器的话,目录应该是:
C
:
\Program
Files
(
x86
)
\Google\Chrome\Application
。
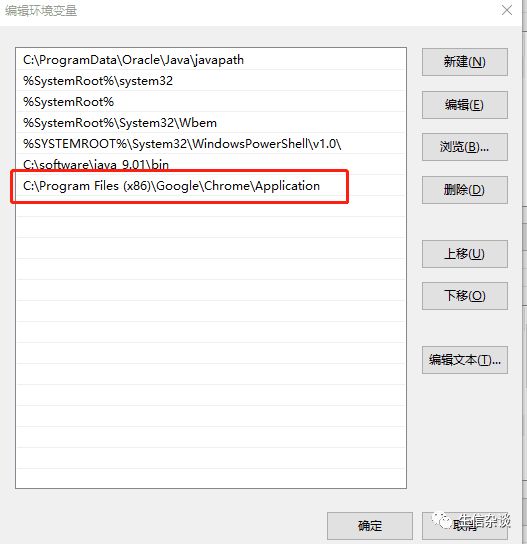
-
将上面的路劲添加到环境变量,操作如下: 我的电脑(计算机) >> 右键属性 >> 左边高级系统设置 >> 右下角环境变量 >> 系统变量Path >> 添加路径即可:
-
在
selenium
-
server
-
standalone
-
3.9
.
0.jar
文件所在的位置,通过shift+鼠标右键选择“在此处打开命令行”。在命令行中运行如下命令启动Selenium Server。
java -jar selenium-server-standalone
-3.9.0.jar
一通操作猛如虎,但我们只完成了准备工作...下面才步入正题,打开R:
rm(list=ls())
library(data.table)
library(openxlsx)
library(stringr)
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
设置服务器连接:
remDr remoteDriver(remoteServerAddr = "127.0.0.1"
, port = 4444
, browserName = "chrome")#连接Server
打开浏览器
remDr$open()
定义提取函数:
webElement_get
function(xpath){
error_flagtry({
webElem_web remDr$findElement(using = "xpath",xpath)
webElem_web_text read_html(webElem_web$getElementAttribute("outerHTML")[[1]]) %>% html_text()
},silent=TRUE)
if('try-error' %in% class(error_flag)){
webElem_web_textNA
}
webElem_web_text
}
使用RSelenium打开网页并加载网页:
remDr$navigate("https://pubchem.ncbi.nlm.nih.gov/compound/9-Cis-Retinoic%20Acid")
Sys.sleep(i%%2+6)
调用上面定义的函数根据Xpaht提取药物ID:
webElement_get('//*[@id="summary-app"]//table[@class="top-summary-items"]//td[preceding-sibling::th[text()="PubChem CID: "]]')
提取完成~
更多原创精彩视频敬请关注
生信杂谈:






