
本文由混沌大学(ID:dfscx2014)授权转载。混沌大学是一所没有围墙的互联网创新大学,遍邀全球名师,拓展认知边界,奉献最专业、最实用、最顶级的互联网创新课程,陪伴这个时代最有梦想的人,早半步认知这个混沌的世界。
本文约
4133
字
,
建议阅读
9
分钟。
本文
是一份关于AI热门应用的案例集,包含了难点、窍门以及最新的研发方向,非常珍贵而又接地气,值得你反复研读和收藏。
机器学习未来的发展路径和前景就是从模块出发,构建一个复杂系统。
——邢波

邢波,师从机器学习泰斗级学术大咖 Michael Jordan ,
卡耐基梅隆大学机器学习和医疗中心主任,2017年机器学习学术水平排名世界第一。
同时,他还是生物化学与计算机科学的双料博士,创立了通用机器学习平台Petuum,并获得软银投资。
卡耐基梅隆大学计算机科学学院教授
通用机器学习平台 Petuum 创始人
翻跟头、倒着飞、倒着转圈……想象一下,一个直升飞机驾驶员,他敢这么飞吗?事实上,如今,最好的直升机驾驶员其实是计算机,依靠的就是机器学习。那么,怎样写一个程序,让直升机这么飞?
我很好的朋友,加州伯克利大学的同学吴恩达博士,他的毕业论文就是用增强学习的算法,写出了飞行的程序。
他在模拟机上,不断随机模拟各种各样飞行的可能性、环境的可能性,用一个增强学习的程序,对模拟出来的环境和动作进行适应,然后不断评估、修正,并最终部署在真正的飞机上,实现神奇的特技动作。
其实,这个增强学习的算法,就是一个典型的机器学习的应用:有学习能力,可以根据大量的场景数据,不断修正方程里的参数,最后达到一个稳定的状态。
所以,从本质上讲,机器学习是传统编程的第二曲线,它是一个写动作的程序,而不是描述动作本身的程序。它是在学习一个方程,而这个方程的X和Y是一个函数、变量,并不是一个确定的值。
Tips:回看整个科学史,机器学习变革意义重大
牛顿定律,怎么发现的?靠的是“人肉智能”:开普勒和第谷积攒了很多行星运行的图表、数据,然后伽利略和牛顿分析以后,发现规律;
同样的道理,元素周期表是如何发现的?
16世纪、17世纪的时候,出现了对分子光谱的描述,某几个物理学家根据这些数据分析发现,氢族、氧族、硫族等都会有同样的光谱分布,从而发现了规律。
而现在,机器学习的出现,让数据分析变得非常高效,从而出现了非常多有价值的应用,计算引擎成了无名英雄。比如:
自动驾驶汽车可以实现自我导航;通过遗传信号可以推断人类祖先的长相……
机器学习这么厉害,我在哪里能买到呢?很不幸,机器学习现在更像一套秘籍,买不到。
接下来,我用一些具体的例子,再详细分享一下它的难点、窍门。
案例集一:自然语言处理
人读书,会有两个基本动作,能读懂,还能讲出来,同理,自然语言处理也包含两大类工作:
理解自然语言
和
生成自然语言
。
1. 理解自然语言
理解是怎么回事?背诵下来,是不是理解了呢?
因此,
需要把理解划分为不同的具体任务
,一旦具体以后,机器就可以找到切入点。
由浅入深,包括以下内容:
从分好类、有标注的训练数据出发,采用不同算法,训练一个分类器。
举个例子,分析一个文章,假如“白宫”出现多次,就可以判断,文章是讲政治的。防垃圾邮件的软件,用的就是这个原理。
这是Google等搜索引擎里的常用功能:通过关键字输入,输出根据相关度排序的结果,再高级点,还有个性化匹配。
举个例子,搜索苹果,结果可能是水果,或是手机。
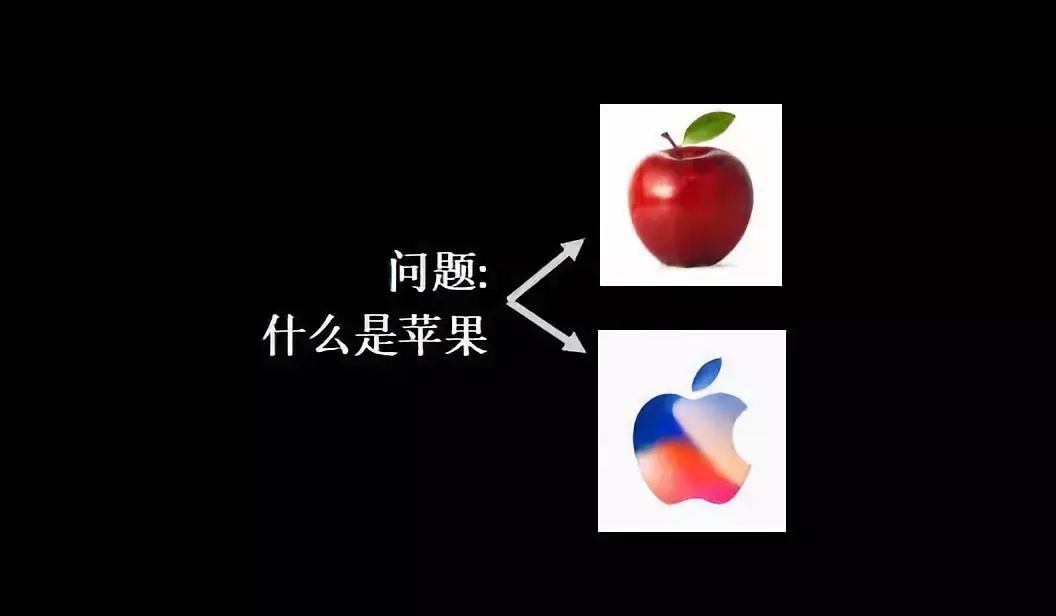
如果搜索引擎对你一无所知,两个结果都可能靠谱。如果你是一位果农或者一位高科技白领,那么就能猜出你想要搜的东西。
也就是说,要实现个性化匹配,需要考虑你的生活习惯、行为特征、以及搜索场景。
将声音信号转化为文本信号的技术,涉及隐马尔科夫链、递归神经网络等机器学习模型,智能音箱、Siri等,都属于这类的应用。
在嘈杂,或是前后关联破碎的场景下,机器很难识别清晰,但是人可以,因为有常识、背景知识,比如人在信号很差的电话环境里,连蒙带猜,也能理解对方的话。
因此,人和机器要有一些互补。
几年前,IBM沃森在知识问答游戏Jeopardy里战胜了人,很轰动。
其实这个系统并不难,因为知识竞赛里的对话很简单,比如——
谁是美国的第一任总统?——乔治·华盛顿
所以,这个系统是一个纯工程,它跟人类智能不一样。
比如问这样一个问题:中国不在大河边上的第二大城市是什么?
小学生很容易就能回答,但你去Google或者百度,却找不到答案。为什么?
不是知识库里没有内容,而是它听不懂你问的是什么,于是它就懵了!
所以,在这里面,有一些关键问题需要大家特别重视:
机器理解人的语言,相当有限,所以,如何提出更好的问题,非常关键。
大家天天在讲的问题,到底有没有价值?到底能不能体现出工程的进步、应用或者市场的需要?
什么是高级的理解?标准测试,比如,大学的入学考试,托福、GRE等
为什么人工智能不去做这种测试?因为比较难,比如:
①得真正看懂测试的问题;
②训练的时候,不能人为输入规则,而是直接把教科书交给机器学习,让它自己把规则、定理、原理、作业题都完全看懂;
③最后自训练,吃透了以后去考试;
④算法要能够给学生解答这个答案的意思。
教育里最难的一点就是出题库,然后训练学生做题。如果有一个人工智能系统,既能出题,也可以跟学生一起做题,甚至还可以给他解释,就会有很多价值。
在这样的做题程序中,深度学习的方法已经被淘汰,其他的机器学习手段得分也不高。下一步,再怎么往上走?还不知道。
换句话说,既能回答问题,又能提问题,这是人工智能最弱的方面,也是一个未知的空间。
我们现在正在做这样的尝试,让机器自动的问一些问题,从而达到自训练或者训练用户的目的。
2. 自然语言生成
这是人机界面中,主动来自机器的动作,是一个很好玩的题目,我重点介绍两个领域的应用:
人在做翻译的时候,通常先听完好几句话,理解后,再用另外一种语言说出来,但是,机器翻译的主要手段是对齐,把两个语句做一一对应,很机械。
在对话系统中,也会有机器味。那么,什么才是有人味的对话呢?
一方面是对感情的把握,和对对方感情的理解;另一方面是对相关常识的引用和理解。
这在目前对话系统里,十分困难,因为没有一个很好的数学模型,对这些任务做清晰的定义。
大数据即使再大,还是体现不出人类语言中不言而喻的内容,该怎么办?
目前,比较新的研究方向是把生成模型和人的背景知识,进行数学层面上严格和自洽的融合,把深度学习的技术和人类逻辑学的知识,
结合在统一的数学模型里
。
这样就可以把人的感情因素融入生成模型,从而让对话看上去更有人味。
计算机视觉是现在相当火爆的方向,大致可以分成两大类问题:
图像感知
与
视觉推理
。
1. 图像感知
它包含的是一些比较原始和低级的任务,比如:
把不同的色块,从背景里面识别出来。
比如一个花花绿绿的人,机器看到的只是几块颜色。
把不同的色块重新整合起来,构成有完整单元含义的目标。
比如,人和车,会被分割在比较自洽的边界内部,然后做标注。行人检测、安防里的刷脸等,用的就是这个道理。

在医疗上,图像识别应用于对X光、CT等做一个自动的诊断,实现精准医疗。
目前,在实践中,最大的困难不是对标准图片的识别,而是在
自然工作环境下,对于自然图片内容的判断和理解。
比如,医疗影像中的噪音,误差,还有设备之间不同的标准,会造成很多算法的失灵,但这些问题很少被提及。
最近的一个有名的例子是,IBM沃森的癌症治疗软件,在美国最好的癌症研究所部署后,就遭遇了比较不幸的失败。所以,人工智能在医疗领域的应用,还是应该谨慎些。








