虽然欺骗行为很容易定义,但是在实验室去研究人们的欺骗,总有一个硬伤:如何让参与者在真正意义上说谎,而不是根据研究者的指导语去说谎?加勒特等人想出了一个巧妙的方法:他们让每个实验参与者参与到一个“估值任务”当中,并告诉参与者,他/她将与另一人进行合作。参与者会看到一罐子硬币的图片,罐子里面装着一堆1便士的硬币,大约是1500个到3500个之间。参与者需要自己估计出罐子里的钱数,然后告诉另一个人(研究者安排的“内应”)。
研究人员让参与者相信,另一个人看不到这一罐子硬币的图片,只能根据参与者提供的信息对罐子里的钱数进行最终评估并上交给实验员,而实验员将根据这个评估的结果对实验中的两人进行奖励。这就给了参与者可以撒谎但不被发现的机会。
 在一轮又一轮的测试中,参与者都可以在给出自己的估计时夸大其词。为了了解参与者在做出诚实估计时的极限水平,研究者另外设置了一个“估计得越准确,参与者最终获得的奖励越多”的分组。
在一轮又一轮的测试中,参与者都可以在给出自己的估计时夸大其词。为了了解参与者在做出诚实估计时的极限水平,研究者另外设置了一个“估计得越准确,参与者最终获得的奖励越多”的分组。
为了操控参与者说谎的动机,加勒特等设置了不同的奖励规则:既有“损人利已”的条件,即猜测的数目越大,则奖励给参与者的钱越多,但给另一方的钱越少;也有“利人利已”的条件,即猜测的数目越大,给参与者与另一方的奖励越多。当然,反过来,也有损己利人的情况——在另一个分组中,参与者猜测的数目越大,参与者自己就越亏。
55名成年人参与了这项实验,每个参与者需要进行60次上述的决策,但实验结束后的奖励,将从这几十次决策中选择一次来作为给他们的奖励。这种设置一方面可以给研究者省钱(如果一次就奖赏15到35镑,一个实验下来花费就快2000镑了!),另一方面,由于没有奖励的累积,所以参与者在实验后期出现说谎尺度更大的情况,就可能不是由于金钱的奖励,而是确实是习惯了说谎——毕竟谁也不知道最后抽中的是哪一次,在实验的后期说谎与在前面说谎可能带来的奖励是没有差别的。
研究者发现,
如果说谎能对自己带来好处——无论是利人利己还是损人利己——随着实验的进行,参与者说谎的尺度都会越来越大。
但是说谎对自己没有好处时,谎言不会随着时间变化。
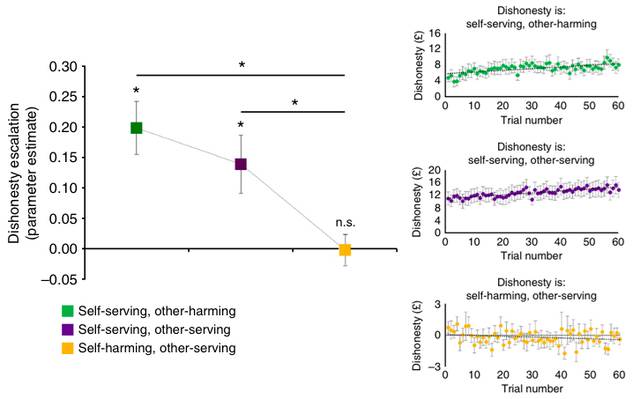 左图:不同条件下,谎言尺度增加的平均值。绿色(损人利己)和紫色(利人利己)代表的是两种对参与者自己有好处的条件,这两种条件下,谎言尺度增加的程度明显高于0,而在黄色所代表的条件(损己利人)下,则与0没有差别。右图:三种条件下,参与者不诚实的程度(英镑数)随测试轮数的变化。
左图:不同条件下,谎言尺度增加的平均值。绿色(损人利己)和紫色(利人利己)代表的是两种对参与者自己有好处的条件,这两种条件下,谎言尺度增加的程度明显高于0,而在黄色所代表的条件(损己利人)下,则与0没有差别。右图:三种条件下,参与者不诚实的程度(英镑数)随测试轮数的变化。





