【新智元导读】
最近,来自
LMSYS Org
的研究人员不仅一次发了两个支持16k token上下文长度的开源大模型LongChat-7B和LongChat-13B。而且,他们还测试了号称支持长上下文能力的几个大模型的实际表现,发现开源模型虚标严重。
早先发布Vicuna模型和大语言模型排位赛的LMSYS Org(UC伯克利主导)的研究人员又开始搞事情了。
这次
,
他们
开发出了一个支持长上下文的开源大模型家族Long
Chat-7B和LongCha
t
-13B,支持高达16
K
token的上下文长度。
但是吧,其实市面上
早
已出现
支持65
K
(MPT-7B-storyteller)和32
K
(CHatGLM2-6B)
token的
选手了。
抱着一边向他们虚心学习一边质疑的研究者心态,他们设计一个专门评估大语言模型处理长上下文
任务的性能的工具,测了测
一众号称支持长上下文的模型们性能到底怎么样。
不测不知道,一测发现之前宣称能支持长上下的开源模型几乎水平都不怎么样,而自家的LongChat在一众「开源李鬼」里才是真的李逵。
而商业闭源大模型的长上下文能力,是真的不错,各个都很能打。
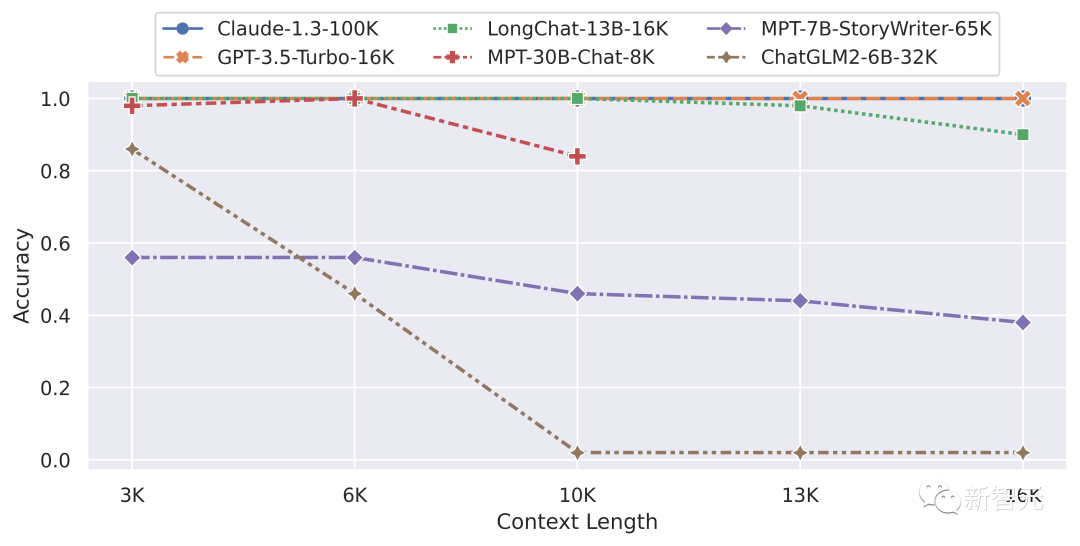
在长距离主题检索任务上比较LongChat和其他模型
根据研究人员测试的结果,闭源的商业长上下文模型确实能兑现它们的承诺:gpt-3.5-16k和Anthropic Claude在基准测试中几乎都达到了完美的性能。
然而,现有的开源模型在长上下文长度方面的表现却比自己「声称」的要差很多。
LongChat模型不仅可以处理高达16k token的上下文长度,而且还能准确地遵循对话中的人类指令,并在人类偏好基准MT-Bench中展示出强大的性能。
· lmsys/longchat-13b-16k
感兴趣的同学可以在命令行界面或Web界面中使用FastChat来跑一下试试:
Pythonpython3 -m fastchat.serve.cli --model-path lmsys/longchat-7b-16k
在研究团队的LongChat存储库中可以找到用于重现研究结果结果的数据和代码,研究人员还贴心地提供了可视化效果展示。
那么我们来看看LongChat是怎么一步一步从LLaMA的2048个token的上下文长度训练到16
K
的。
第一步:压缩旋转嵌入( Rotary embedding)
旋转位置嵌入是一种将位置信息注入Transformer的位置嵌入方法。
在Hugging Face的Transformer库中,它的实现方式如下:
Pythonquery_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
其中position_ids是索引,如1、2、3等,用于表示句子中token的位置。
例如,在句子「today is a good day」中,token「today」的position_ids为1。apply_rotary_pos_emb()函数根据提供的position_ids应用变换。
LLaMA模型使用旋转嵌入在序列长度2048上进行预训练的。
这就意味着在预训练阶段就观察不到position_ids > 2048的情况。
研究团队没有强制LLaMA模型适应position_ids > 2048,而是将position_ids > 2048的部分压缩到0到2048之间。
直观地说,研究人员假设这种压缩可以最大程度地重用在预训练阶段学到的模型权重。
他们通过将目标新上下文长度y除以2048来定义压缩比率。
然后将每个position_ids除以这个比率,并将其输入apply_rotary_pos_emb()函数。
Pythonquery_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids / ratio)
在此版本中,研究人员将模型微调到上下文长度为16384,压缩率设为8。
例如,把position_ids = 10000的token变为position_ids = 10000 / 8 = 1250,而相邻的token10001变为10001 / 8 = 1250.125。
这个技术最先由开源社区的一个叫Kaiokendev的开源爱好者发现(https://kaiokendev.github.io/context)并传播和讨论。LMSys Org的研究人员发现这个技术确实很好使,而且这一步只需要改一行代码,不需要进行训练。
在压缩嵌入之后,研究人员使用他们精心挑选的对话数据集执行微调过程。
研究团队重新使用了先前用来训练Vicuna的用户分享对话数据。
使用FastChat数据处理流程清理数据,截断了这些对话,使其长度不超过16
K
。
然后再使用标准下一个token预测损失对模型进行微调。
最后他们分别使用80,000个和18,000个对话对7B和13B模型进行微调。
假设在云上使用A100花费每小时3美元,7B模型的成本约为300美元,而13B模型的成本约为700美元。
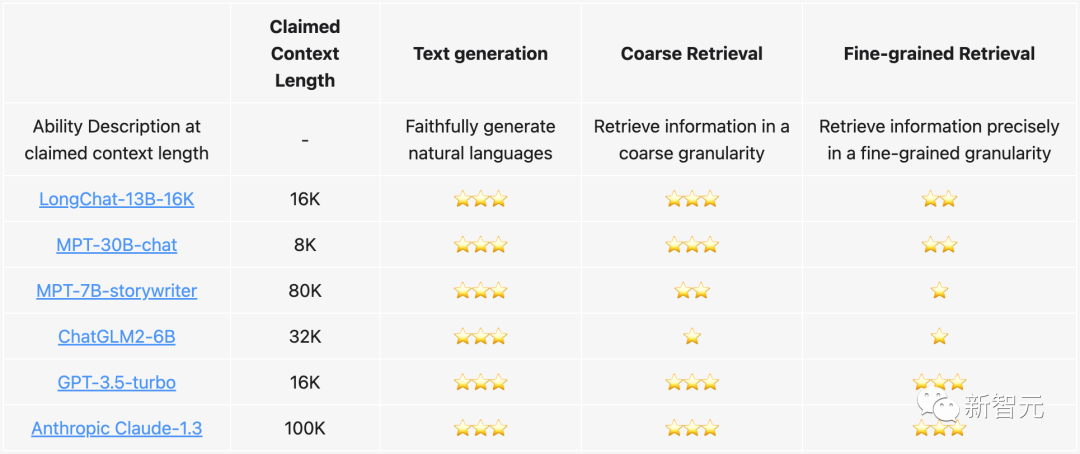
为了验证商业闭源和开源模型宣传支持的长上下文能力(从8
K
、32
K
到100
K
)到底有多强,研究团队开发了一套验证工具包。
不同的模型作者可能对所谓的「长上下文能力」对有着不同的理解。
举个例子,MPT-7B-StoryWriter所宣称的65
K
上下文长度是否与OpenAI的ChatGPT在16
K
上下文长度下具有相同的性能?
在LongChat开发过程中,同样的问题也困扰着研究团队。
如何迅速有效地确认一个新训练的模型是否能够真地有效处理预期的上下文长度?
为了解决这个问题,研究团队可以基于需要LLM处理长上下文的任务进行评估。
例如文本生成、检索、摘要和长文本序列中的信息关联。
受最近的研究启发,研究人员们设计了一个名为LongEval的长上下文测试套件。
这个套件包括两个难度不同的任务,提供了一种简单快捷的方式来衡量和比较长上下文的性能。
在现实世界的长对话中,用户通常与聊天机器人的讨论会在多个主题间跳转。
这个任务会要求聊天机器人检索由多个主题组成的长对话中的第一个主题,来模拟这种情景。
Python… (instruction of the task)USER: I would like to discuss ASSISTANT: Sure! What about xxx of ?… (a multi-turn conversation of )USER: I would like to discuss …USER: I would like to discuss …USER: What is the first topic we discussed?ASSISTANT:
这个任务测试模型是否能够定位长下文中的一段文本并将其与正确的主题名称相关联。
研究人员设计了很多个由400到600个token组成的对话,并随机组合它们达到到想要测试的长度,将组合出来的长文本作为 Prompt.
所以,这是一个粗粒度的对话,因为当模型能够定位到距离正确位置不太远(<500个token距离)的位置时,它可能会给出正确的预测。
为了进一步测试模型在长对话中定位和关联文本的能力,研究人员引入了更精细的行检索测试(Line Retrieval test)。
在这个测试中,聊天机器人需要精确地从长文档中检索一个数字,而不是从长对话中检索一个主题。
Pythonline torpid-kid: REGISTER_CONTENT is <24169>line moaning-conversation: REGISTER_CONTENT is <10310>…line tacit-colonial: REGISTER_CONTENT is <14564>What is the in line moaning-conversation?
这个任务最初是在「Little Retrieval Test」中被设计出来的。
原始的测试中,是使用数字来表示一行,但研究人员发现较小的LLM通常无法很好地理解数字。
为了解开这些因素并使其更适合测试不同大小的开源聊天机器人,他们通过使用随机的自然语言(例如「torpid-kid」)进行改进。
1. 任务可以有效捕捉到文本生成、检索和长上下文信息关联的能力,最终反映在检索准确性上。
2. 可以轻松将测试扩展到任意长度,以测试模型在不同上下文长度下的能力。
3. 研究人员已经对这两个任务进行了检查,并观察到了预期的结果。
例如,对于使用2
K
上下文进行预训练的原始LLaMA模型,在测试输入长度小于2
K
时可以实现完美的准确性。
研究人员通过这个原理,就能检测不同模型对于不同上下文长度时,执行信息检索和关联相关信息的能力。
根据粗粒度的主题检索测试结果,团队观察到开源的长上下文模型的性能似乎没有自己宣称得那么好。
例如,Mpt-7b-storywriter声称具有84
K
的上下文长度,但即使在它声称的上下文长度的四分之一(16
K
)处,准确率也仅达到50%。
Chatglm2-6B在长度为6
K
(46%准确率)时无法可靠地检索第一个主题。
当在大于10
K
的上下文长度上进行测试时,其准确率几乎为0%。
另一方面,研究人员观察到LongChat-13B-16K模型可靠地检索到第一个主题,并且准确率与gpt-3.5-turbo相当。










