来自:数据工程师成长之路
作者:清雨影
链接:www.cnblogs.com/TsingJyujing/p/6549780.html(点击尾部阅读原文前往)
已获转载授权
前言
最近迷上了看黄片(大雾)。每次总是去搜索想看的片子,什么asian porn anal pussy 什么的我都不知道。
搜索着搜索着我手也累了,而且我喜欢的片子也是有一定的特征的,我不想把所有的时间花费在重复劳动上,于是决定让机器帮我……找出喜欢的片子。
(所有代码都在Github上了,文中不放出全部代码了,实在太冗长了)
代码在此:https://github.com/TsingJyujing/xhamster_analysis
我连表结构(CREATE TABLE的SQL语句)都放上去了啊同志们!!!所以我打这么厚的马赛克你么你也得原谅我啊!!!!
主要的代码是这个:
https://github.com/TsingJyujing/xhamster_analysis/blob/master/PornDataAnalysis.ipynb
PS:最近准备找新东家,有没有公司愿意养我这个喜欢喝咖啡的老不正经,我保证用从硬到软的强大的原型开发能力给你一个HUG。
简历见:https://github.com/TsingJyujing/Resume/blob/master/README.md
原始数据的采集
首先是原始数据的收集,我随机收集了大约30万部片子,包括标签,下载链接,标题,时长,好评率等等。
使用的代码是这个:https://github.com/TsingJyujing/DataSpider
自己写的一个数据获取的API,xhamster也是好脾气,我爬取的过程中并没有遭到限速或者封IP之类的问题。关于爬虫的编写,在这里不是重点,可以回去自己补设计模式和并发的课。
数据的预处理
首先最重要的是我为300~400部电影打了分,打分的方式是建立一个django网站,随机抽取一些片子,显示其预览图并且给我打分的选项,源代码也已经公开了。说实话,打分完成以后看太阳都是绿色的……
评分依据当然是根据个人的喜好,比如我对平刘海有着深刻的好感,没有平刘海简直就不是女生(逃
为了让机器知道我喜欢那些电影,以后自动帮我下载(误
我需要让机器学习一下我的癖好,就根据网站上的标签(我简称之为Tag,其实是Categories,否则打字太痛苦了)
Logistic Regression进行影片分类
原理不明的可以看这两篇:
https://zhuanlan.zhihu.com/p/20511129
https://zhuanlan.zhihu.com/p/20545718
下面是用Logistic Regression对性癖进行学习,使用了sklearn中的LogisticRegressionCV(带交叉验证的Logistic回归) 我特地没有考虑时间因子,因为实际验证的时候,因为有些片子的时间有错误,有的长达十几个小时,导致推荐的都是这些乱七八糟的影片。
短时间的视频大多数都是渣渣,但是长时间的也未必好看,我不如去掉这个因子让它不再干扰我。 虽然使用时间能达到更高的精度,但是却和“学习性癖”这个主题背道而驰了,最终的效果也并不理想。
import sklearn.linear_model
regr = sklearn.linear_model.LogisticRegressionCV(
Cs=60, fit_intercept=True, cv=4, dual=False,
penalty='l2', scoring=None, solver='lbfgs', tol=0.0001,
max_iter=1000, class_weight=None, n_jobs=1, verbose=1)
regr.fit(Xt_train, y_train>-0.5)
y_train_predict = regr.predict(Xt_train)
y_test_predict = regr.predict(Xt_test)
y_train_real = np.reshape(y_train>-0.5,y_train_predict.shape)
y_test_real = np.reshape(y_test>-0.5,y_test_predict.shape)
# 输出报告
from sklearn import metrics
print('------------ACCURACY-------------')
print "Train accuracy: %f%%" % (sum(y_train_predict==y_train_real)*100.0/len(y_train_real))
print "Test accuracy: %f%%" % (sum(y_test_predict==y_test_real)*100.0/len(y_test_real))
输出:
------------ACCURACY-------------
Train accuracy: 68.211921%
Test accuracy: 70.886076%
还可以,说实话,数据噪声比较大,能做到这样我已经比较欣慰了。回头用CNN带图像的时候争取做到95%+
线性的Logistic回归有很好的可解释性,让我们来看一下究竟是哪些标签让我着迷呢?
我们输出对正负分别贡献最大的N个标签:
index = np.argsort(regr.coef_[0])
tag_sorted = []
for i in index:
tag_sorted.append(tag_list[i])
# 显示对分类有正贡献的词汇和负贡献的词汇
N = 20 print "Positive top N words:",",".join(tag_sorted[-N:])
print "Negative top N words:",",".join(tag_sorted[:N])
输出:
Positive top N words: Fucking,Porno Vrai,Blowjobs,German,Shaved,French,Young Masturbating,Masturbating,Chubby,Sexy Latina,Fisting and Squirting,Teens,Gangbang,Pussy Fucking,Muscular Women,Double Penetration,Hardcore,Creampie,Japanese,Anal
Negative top N words: Amateur,Close-ups,Throat Fuck,Big Dick,Bisexuals,Sexy Horny,Flashing,Outdoor,Hidden Cams,Public Nudity,Redheads,Wife,Sofia Gucci,Anal Fuck,Granny,Cock Suckers,Student,Oral,Mexican,Private
(好吧我觉得我暴露了)
Logistic模型实战用于影片推荐
虽然后来又试了SVR或者Lasso等回归方法来推荐,但是最后还是选择了Logistic回归为我的影片进行打分。
下面是用训练好的Logistic模型为我爬虫爬到的所有电影打分,并且我使用了一个django网站来显示这些影片的预览,来看看和我的喜好是否相符合。
我可以对推荐的视频进行打分,打分多了以后可以重新学习,提高系统精度。
我们来看一下机器给我的30W个视频打分的分布:(0最低,1最高)
我们可以看到,高于0.5分(分类界)的视频少之又少,说明这个网站整体质量欠佳(至少对我而言),但是不乏也有一些金矿可以开发。
附录们
附录:评分的分布
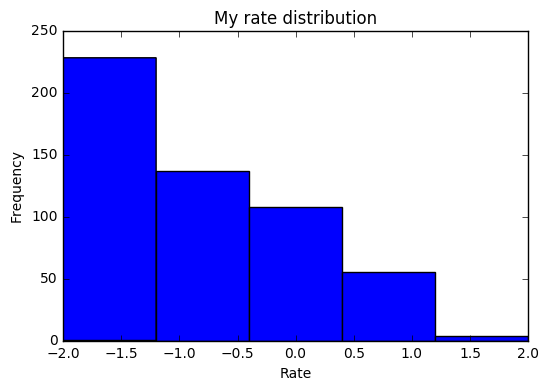
可以看到我打分是偏低的,并不是说我是一个严格的评分者,而是网站并不很对我胃口。
最后我以-0.5为分界线作为正样本和负样本的标签依据。
附录:播放时间的统计分析
数据下载到本地的数据库以后(本文使用的是PostgreSQL数据库)随后我对这30万个数据进行了初步的分析:
首先查看播放时间的分布:
[F,x,p]=hist(Tall,bins=35)
xlabel('Time(s)')
ylabel('Frequency')
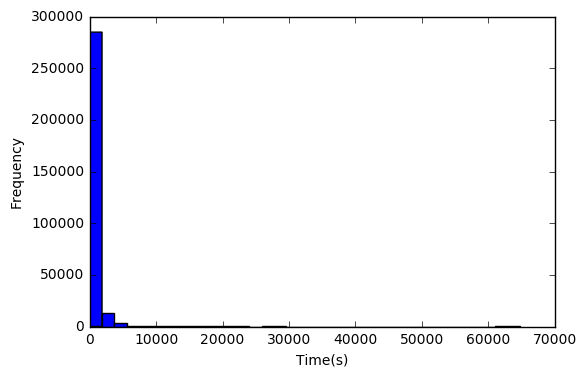
我们发现聚集在0附近的比较多,而且播放时间都是大于0的(这算常识了) 我们再统计一下log(T)的分布:
[F,x,p]=hist(np.log10(Tall),bins=50,normed=True,histtype='stepfilled',alpha=0.35)
xlabel('log_10(Time(s))')
ylabel('Frequency')
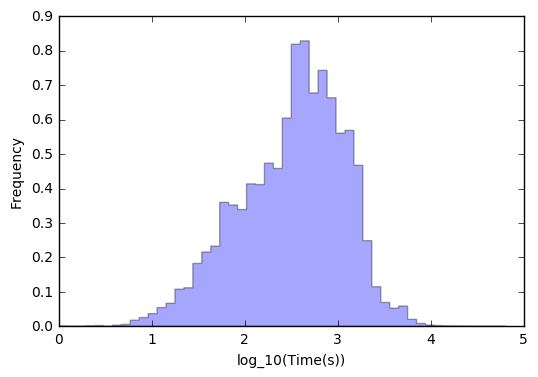
可以看到现在的分布比较好看了,也具有更“好”的性质了(其实就是长的像正态,至于是不是正态应该qqplot一下)
import pylab
import scipy.stats as stats
stats.probplot(np.log10(Tall).reshape((len(Tall),)), dist="norm", plot=pylab)
pylab.show()
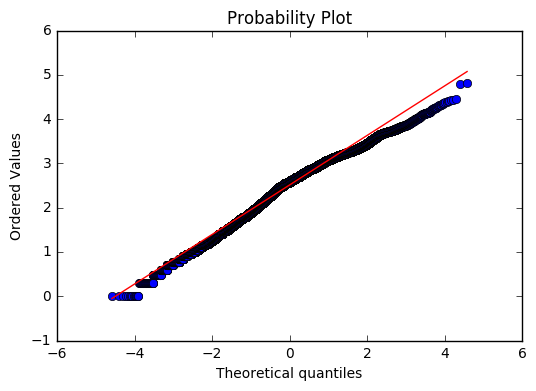
可以看到,还是基本符合正态分布的。但是最后的分析并没有用到时间,原因有说明。
附录:彩蛋一枚,请唱出来
Logistic, 带带我,我要上火车啊
Logistic, 带带我,我要看小片啊
Logistic不是那种“人”,那种事情不可能
阿哩哩,阿哩哩,阿哩阿哩哩
Logistic, 带带我,并行性能高啊
Logistic, 带带我,鲁棒性能好啊
管你分类不分类,噪声太大先清洗
阿哩哩,阿哩哩,阿哩阿哩哩
Logistic, 带带我,我的数据多啊
Logistic, 带带我,可解释性好啊
梯度上升要并发,送入模型快训练
阿哩哩,阿哩哩,阿哩阿哩哩
小贴士:返回上一级搜索“机器学习”获取更多相关文章。
●本文编号2383,以后想阅读这篇文章直接输入2383即可。
●输入m获取文章目录

大数据技术
更多推荐《15个技术类公众微信》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、iOS开发、C/C++、.NET、Linux、数据库、运维等。










