

图源:unsplash
原文来源
:TensorFlow
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
导语:TF-Hub是一个可以共享机器学习专业知识的平台,里面包含在可重用资源中打包的机器学习专业知识,特别是在预先训练的模块中的技能。接下来,本文将介绍该如何使用“TF-Hub”构建一个简单的文本分类器。本教程主要从两个部分展开:使用TF-Hub训练文本分类器和迁移学习的分析。
介绍:使用TF-Hub训练文本分类器
我们将使用一个TF-Hub文本嵌入模块来训练一个简单的情绪分类器,并具有合理的基线精确度。然后,我们将分析预测结果以确保我们的模型是合理的,并提出改进以提高准确度。
进阶:迁移学习分析
在本节中,我们将使用各种TF-Hub模块来比较它们对估计精确度的影响,并论证迁移学习的优点和缺点。
可选的先决条件
•对Tensorflow预制估计量框架的基本理解。
•对Pandas Library的熟悉。
准备环境
# Install the latest Tensorflow version.
# Install TF-Hub.
!pip install -q tensorflow-hub
关于安装Tensorflow的更多详细信息请见:
https://www.tensorflow.org/install/
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
/usr/local/lib/python2.7/dist-packages/h5py/__init__.py:36: FutureWarning:Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
开始
数据
我们将尝试解决从群众Mass等获得的大型电影评论数据集(Large Movie Review Dataset)v1.0任务。该数据集由IMDB电影评论组成,并被根据积极性从1到10进行标注。我们的任务是将这些评论标注为
负面
或
正面
。
# Load all files from a directory in a DataFrame.
def load_directory_data(directory):
data = {}
data["sentence"] = []
data["sentiment"] = []
for file_path in os.listdir(directory):
with tf.gfile.GFile(os.path.join(directory, file_path), "r") as f:
data["sentence"].append(f.read())
data["sentiment"].append(re.match("\d+_(\d+)\.txt", file_path).group(1))
return pd.DataFrame.from_dict(data)
# Merge positive and negative examples, add a polarity column and shuffle.
def load_dataset(directory):
pos_df = load_directory_data(os.path.join(directory, "pos"))
neg_df = load_directory_data(os.path.join(directory, "neg"))
pos_df["polarity"] = 1
neg_df["polarity"] = 0
return pd.concat([pos_df, neg_df]).sample(frac=1).reset_index(drop=True)
# Download and process the dataset files.
def download_and_load_datasets(force_download=False):
dataset = tf.keras.utils.get_file(
fname="aclImdb.tar.gz",
origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True)
train_df = load_dataset(os.path.join(os.path.dirname(dataset),
"aclImdb", "train"))
test_df = load_dataset(os.path.join(os.path.dirname(dataset),
"aclImdb", "test"))
return train_df, test_df
# Reduce logging output.
tf.logging.set_verbosity(tf.logging.ERROR)
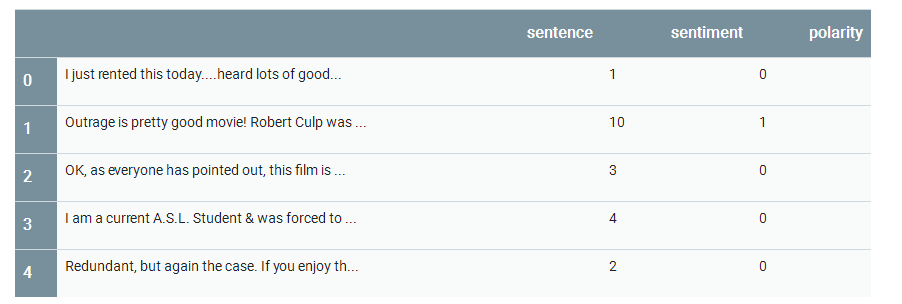
train_df, test_df = download_and_load_datasets()
train_df.head()
Downloading data from http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
84131840/84125825 [==============================] - 1s 0us/step
84140032/84125825 [==============================] - 1s 0us/step
模型
输入函数
估计框架(Estimator framework)提供了包装Pandas数据框的输入函数。
# Training input on the whole training set with no limit on training epochs.
train_input_fn = tf.estimator.inputs.pandas_input_fn(
train_df, train_df["polarity"], num_epochs=None, shuffle=True)
# Prediction on the whole training set.
predict_train_input_fn = tf.estimator.inputs.pandas_input_fn(
train_df, train_df["polarity"], shuffle=False)
# Prediction on the test set.
predict_test_input_fn = tf.estimator.inputs.pandas_input_fn(
test_df, test_df["polarity"], shuffle=False)
特征列
TF-Hub提供了一个特征列,它在给定的文本特征上应用了一个模块,并进一步传递了模块的输出。在本教程中,我们将使用nnlm-en-dim128模块。为了达成本教程的目的,几个最重要的事实是:
•该模块将
一组1-D的字符串张量中的句子
作为输入。
•该模块负责
对句子进行预处理
(例如,删除标点符号并分隔空格)。
•该模块可以处理任何输入(例如,
nnlm-en-dim128
会将没有出现在词汇表中的单词散列到~20.000桶内)。
embedded_text_feature_column = hub.text_embedding_column(
key="sentence",
module_spec="https://tfhub.dev/google/nnlm-en-dim128/1")
估计
对于分类,我们可以使用DNN分类器(请注意,在本教程的最后有关于不同建模函数的进一步附注)。
estimator = tf.estimator.DNNClassifier(
hidden_units=[500, 100],
feature_columns=[embedded_text_feature_column],
n_classes=2,
optimizer=tf.train.AdagradOptimizer(learning_rate=0.003))
训练
以合理数量的步骤对估计量进行训练。
# Training for 1,000 steps means 128,000 training examples with the default
# batch size. This is roughly equivalent to 5 epochs since the training dataset
# contains 25,000 examples.
estimator.train(input_fn=train_input_fn, steps=1000);
预测
以对训练和测试集进行预测
train_eval_result = estimator.evaluate(input_fn=predict_train_input_fn)
test_eval_result = estimator.evaluate(input_fn=predict_test_input_fn)
print "Training set accuracy: {accuracy}".format(**train_eval_result)
print "Test set accuracy: {accuracy}".format(**test_eval_result)
Training set accuracy: 0.802160024643
Test set accuracy: 0.792879998684
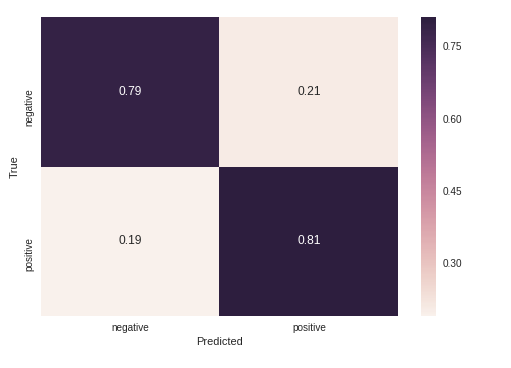
混淆矩阵
我们可以直观地检查混淆矩阵来确定错误分类的分布。
def get_predictions(estimator, input_fn):
return [x["class_ids"][0] for x in estimator.predict(input_fn=input_fn)]
LABELS = [
"negative", "positive"
]
# Create a confusion matrix on training data.
with tf.Graph().as_default():
cm = tf.confusion_matrix(train_df["polarity"],
get_predictions(estimator, predict_train_input_fn))
with tf.Session() as session:
cm_out = session.run(cm)
# Normalize the confusion matrix so that each row sums to 1.
cm_out = cm_out.astype(float) / cm_out.sum(axis=1)[:, np.newaxis]
sns.heatmap(cm_out, annot=True, xticklabels=LABELS, yticklabels=LABELS);
plt.xlabel("Predicted");
plt.ylabel("True");
进一步改进
情绪回归
:我们使用分类器将每个样本分配到极性类中。但实际上,我们还有另一个分类特征——情绪。在这里,类实际上表示一种规模,基础值(正/负)可以很好地映射到一个连续的范围内。我们可以通过计算回归(DNN Regressor)而非分类(DNN Classifier)来利用这一特性。
更大的模块
:为了达到本教程的目的,我们使用了一个小模块来限制内存的使用。有些模块拥有更大的词汇量和更大的嵌入空间,可以提供更多的精准点。
参数调整
:我们可以通过调整学习速率或步骤数等元参数来提高精确度,尤其当我们使用不同模块时。如果要得到合理的结果,那么验证集是非常重要的,因为它很容易建立一个学习预测训练数据的模型,而不需要很好地泛化到测试集。
更复杂的模型
:我们使用了一个模块,通过嵌入每个单词,将它们与平均值相结合来计算句子嵌入。我们还可以使用序列模块(如通用句子编码器模块)来更好地捕捉句子的性质。或两个或多个TF-Hub模块的组合。
正则化
:为了防止过度拟合,我们可以尝试使用执行某种正则化的优化器,例如Proximal Adagrad Optimizer。
进阶:迁移学习分析
迁移学习可以
节省训练资源
并实现良好的模型泛化,即使
在小数据集上进行训练
时也是如此。在这一部分中,我们将通过使用两种不同的TF-Hub模块进行训练来证明这一点。
•
nnlm-en-dim128
– 预训练文本嵌入模块
•
random-nnlm-en-dim128
– 与
nnlm-en-dim128
具有相同词汇表和网络的文本嵌入模块,但权重只是随机初始化,从未在真实数据上进行过训练。
通过两种模式进行训练
•只训练分类器(即冻结模块)
•分类器同模块一起训练
让我们运行几组训练和评估,看看使用不同模块会给精确度带来哪些影响。
def train_and_evaluate_with_module(hub_module, train_module=False):
embedded_text_feature_column = hub.text_embedding_column(
key="sentence", module_spec=hub_module, trainable=train_module)
estimator = tf.estimator.DNNClassifier(
hidden_units=[500, 100],
feature_columns=[embedded_text_feature_column],
n_classes=2,
optimizer=tf.train.AdagradOptimizer(learning_rate=0.003))
estimator.train(input_fn=train_input_fn, steps=1000)
train_eval_result = estimator.evaluate(input_fn=predict_train_input_fn)
test_eval_result = estimator.evaluate(input_fn=predict_test_input_fn)
training_set_accuracy = train_eval_result["accuracy"]
test_set_accuracy = test_eval_result["accuracy"]
return {
"Training accuracy": training_set_accuracy,
"Test accuracy": test_set_accuracy
}
results = {}
results["nnlm-en-dim128"]=train_and_evaluate_with_module(
"https://tfhub.dev/google/nnlm-en-dim128/1")
results["nnlm-en-dim128-with-module-training"] = train_and_evaluate_with_module(





