
数据挖掘入门与实战 公众号: datadw
数据分析有一半以上的时间会花在对原始数据的整理及变换上,包括选取特定的分析变量、汇总并筛选满足条件的数据、排序、加工处理原始变量并生成新的变量、以及分组汇总数据等等。这一点,我想大部分使用EXCEL的童鞋都深有体会,写论文时,这么多的数据进行处理,手动汇总、筛选、变换,工作量实在是太大。而本文介绍的dplyr包简直就是Hadley
Wickham (ggplot2包的作者,被称作
“一个改变R的人”
)大神为我们提供的“数据再加工”神器啊。
本文试图通过一个案例,对神奇的dplyr包的一些常用功能做简要介绍。在此抛砖引玉,欢迎广大盆友拍砖。先放上实践课的一个问题:
航行距离与到达延误时间有什么关系??
带着这个问题,我们将首先使用dplyr包对给出的航班数据进行处理。
1.dplyr包的安装加载与示例数据准备
1.1 安装dplyr包
脚本输入代码:
install.packages("dplyr") #加载dplyr包
library(dplyr)
1.2
安装 nycflights13包
,该软件包中的飞机航班数据将用于本文中dplyr包相关函数的演示。
脚本输入代码:
install.packages("nyclights13") #加载nyclights13
library(nyclights13)
flights #查看数据表
dim(flights) #查看变量的维数
输出结果如下:
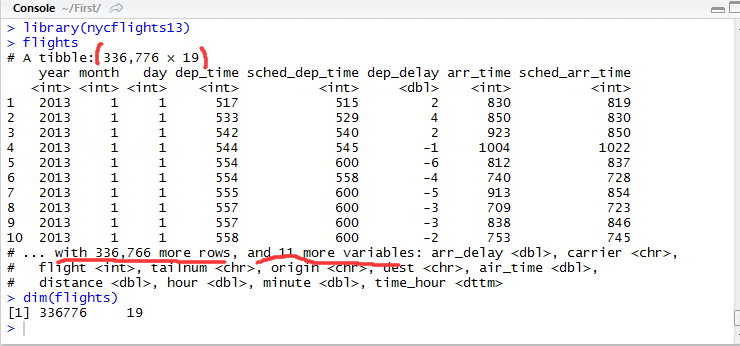
如图可知,nycflights13是一个data.frame类型的对象,包含336776条数据记录、19个变量。
在处理数据之前,让我们再来回顾一下数据处理的一般步骤:
选择子集、
列名重命名、
删除缺失数据、
处理日期、
数据类型转换、
数据排序
接下来,就可以进行数据处理了:
2.数据处理
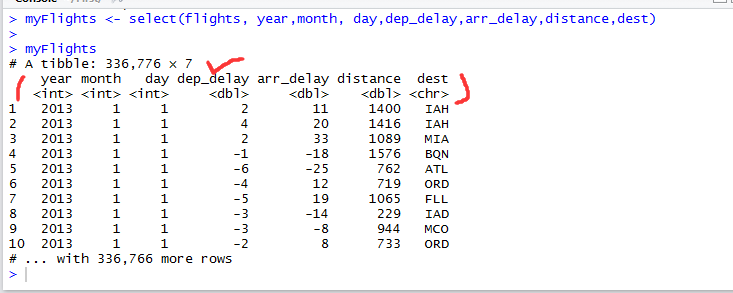
2.1 选择子集
所谓选择子集,就是选择出能够实现分析目标的变量,本次数据分析的目标是得出航行距离与延误时间的关系,因此,相应的子集就是以下几个字段:
year 航班日期-年
month 航班日期-月
day 航班日期-月
dep_delay 起飞延迟时间(分)
arr_delay 到达延迟时间(分)
distance 航行里程(英里)
dest 目的地
为此,我们首先
使用dpylr包里的select函数,进行变量筛选:
脚本输入代码:
myFlights
myFlights #查看数据表
如图,子集选择完毕。
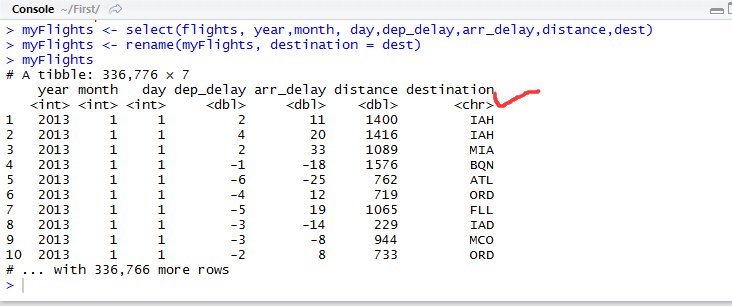
2.2 列名重命名
为了让列名简单易懂,可以使用rename函数,进行列名重命名。
脚本输入代码:
myFlights
myFlights
重命名完毕。
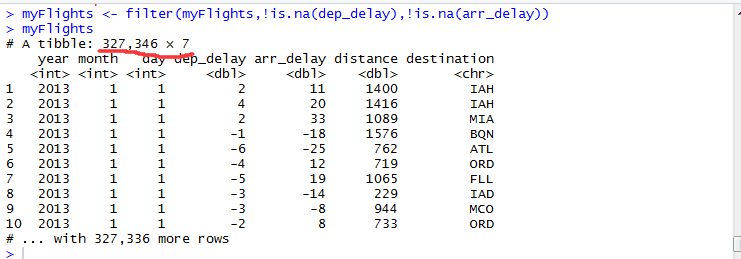
2.3 删除缺失数据
我们采用dplyr包中的filter()函数,进行缺失数据的删除。脚本输入代码:
myFlights
myFlights
由图可知,我们首先采用is.na()函数找出缺失值,再采用逻辑运算符“!X”将限定有效数据,最后用
filter()函数“过滤”得到有效数据,成功地删除了缺失数据(由原先的336,776个数据变为327,346个数据)。
2.4 数据排序
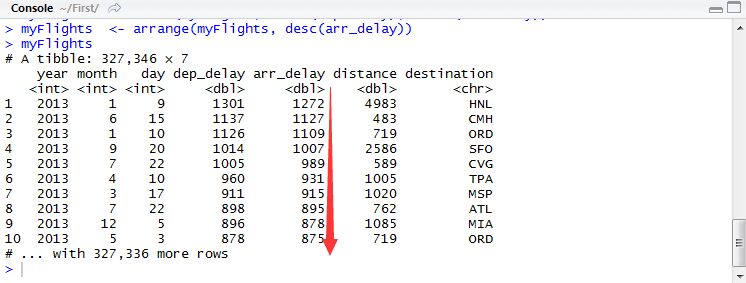
为了数据的整齐性,我们可以选择相应的变量进行排序。这里要穿插一个排序函数arrange(),默认情况下,为升序排列,也可以对列名加desc()进行降序排序。脚本输入代码:
myFlights
myFlights
如图所示,数据按照变量
arr_delay
(到达延迟时间(分))进行降序排列。
3.数据计算
数据处理之后,就进入计算分析步骤啦。在这个环节,主要历经三个过程:
数据分组(
Split
):可以指定目标变量,将数据进行分组。由于本次分析的目标是找出航行距离与到达延误时间的关系,所以我们得根据到达目的地对数据进行分组,从而计算出不同目的地的平行航行距离以及平均延误时间;
应用函数(
Apply
):对不同组的数据,应用相应函数获取所需统计指标。比如本次不同目的地的平行航行距离以及平均延误时间;
组合结果(
Combine
):将计算后的统计指标值与第一步当中对应的分组进行组合。
3.1 数据分组
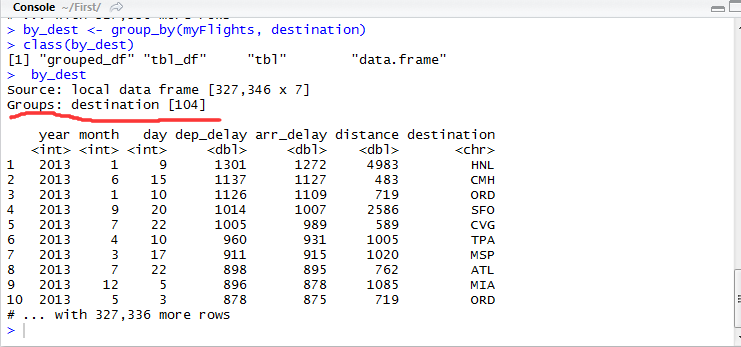
dplyr包里的分组是由group_by()函数实现的,脚本输入代码:
by_dest
class(by_dest)
by_dest
由图可知,经分组后,一共有104组数据,即本次分析的目的地有104个。
3.2 应用函数及组合结果
我们使用dplyr包中的summarize()函数,进行数据统计指标的获取及组合。计算出不同目的地的平行航行距离以及平均延误时间。脚本输入代码:
delay_sum
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE))
delay_sum
delay_sum
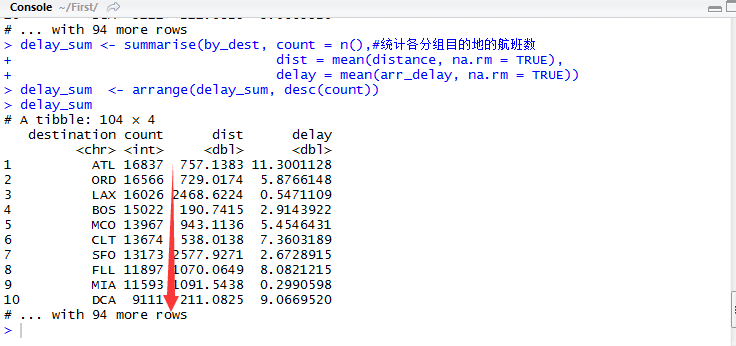
从上图可得知104个目的地的航班数排序。为了统计的科学合理性,需要对数据量太少的组别进行剔除,即剔除噪音数据,再次使用filter()函数剔除,剔除限度设为count>20。脚本输入代码:
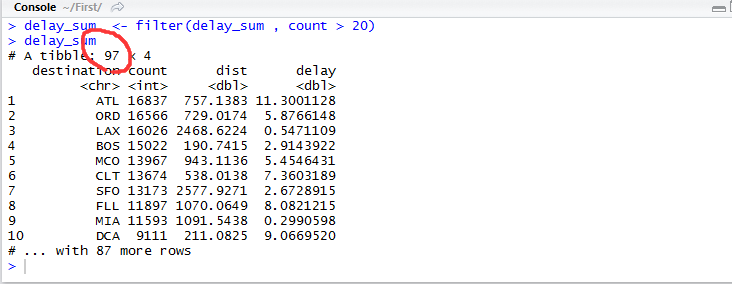
delay_sum
delay_sum 20)
如上图可知,剩余97组数据,即本次参与统计的目的地有97个。
PS.
这里穿插一个好用的工具,
“管道”
,即通过使用操作符把数据集名作为开头, 然后依次对此数据进行多步操作。这种运算符的编写方式使得编程者可以按数据处理时的思路写代码, 一步一步操作不断叠加,在程序上就可以非常清晰的体现数据处理的步骤与背后的逻辑。
通过管道的连接方式,让数据或表达式的传递更高效,使用向右操作符%>%,可以直接把数据传递给下一个函数调用或表达式。(
%>%是最常用的一个操作符,就是把左侧准备的数据或表达式,传递给右侧的函数调用或表达式进行运行,可以连续操作就像一个链条一样。
)拿上述的代码进行举例,在没用管道之前,代码是这样的:
by_dest
delay_sum
dist = mean(distance, na.rm = TRUE),#计算平均航行距离
delay = mean(arr_delay, na.rm = TRUE))#计算平均延误时间
delay_sum
delay_sum 20)#剔除噪音数据
delay_sum#显示列表
用了管道“%>%”,代码是这样的:
delay_sum % #将右侧航行数据赋值给左侧delay_sum
group_by(destination) %>% #对delay_sum进行分组
summarise( count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>% #对分组后的delay_sum进行计算统计
filter(count > 20)#对统计结果进行噪音剔除
delay_sum#显示列表
果然简洁了很多!
4.数据显示
所谓一图胜千言啊,在大数据可视化普及的今天更是这样。本次同样使用Hadley Wickham 大神(ggplot2包的作者)贡献的ggplot2包进行绘图。调用ggplot()函数进行绘图,脚本输入代码:
ggplot(data = delay_sum) +
geom_point(mapping = aes(x = dist, y = delay)) +#绘制平均航程(dist)和平均延误时间(delay)的散点图
geom_smooth(mapping = aes(x = dist, y = delay))#拟合一条平滑曲线
(注意,连接符号+不可省略)
所得结果如下所示:
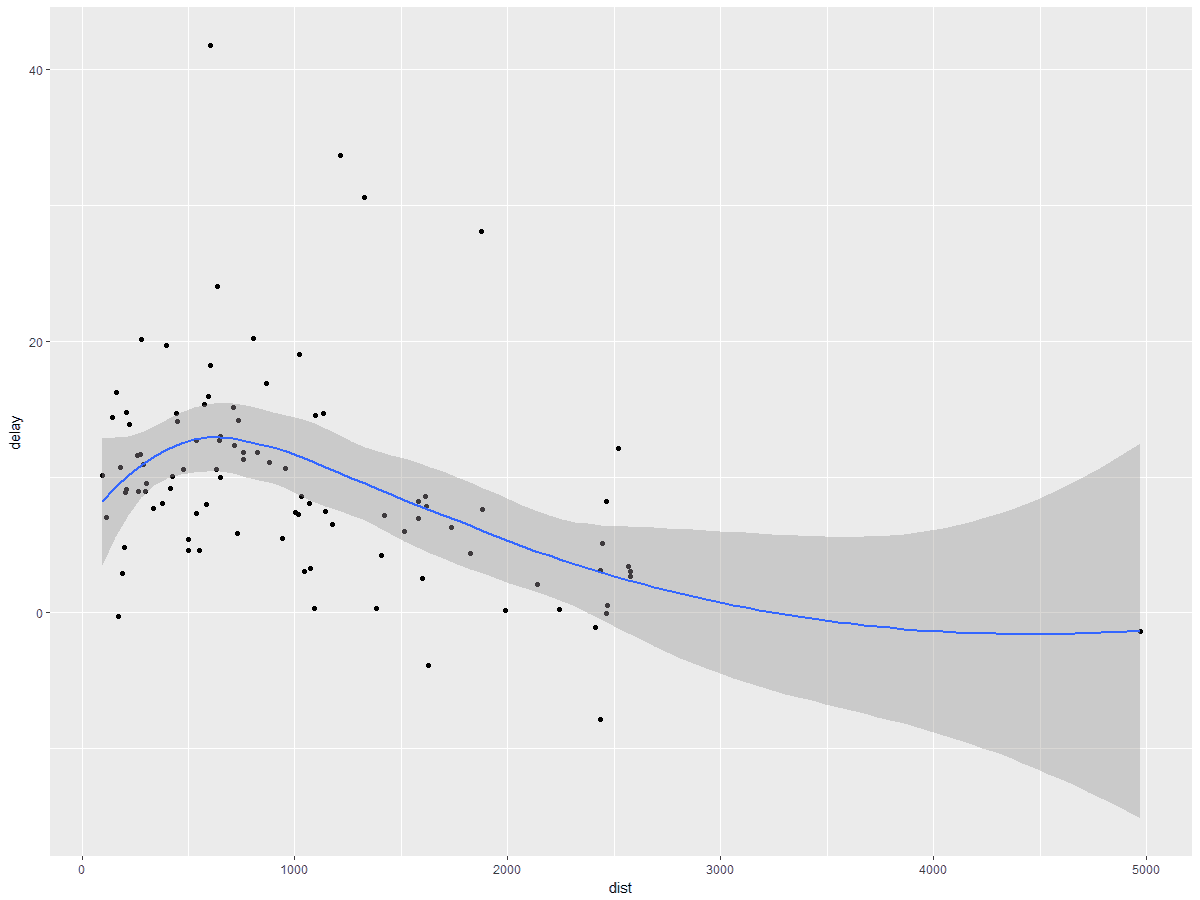
由上图,我们就可以初步分析航程和延误时间并非线性关系,至于这种非线性关系该怎么解释,仍需进一步统计调查分析。
数据挖掘入门与实战
搜索添加微信公众号:datadw










