
作者深入内核讲述了 MySQL semijoin 从识别到优化器根据代价决定最优执行策略,以及执行方式的全过程,掌握 MySQL semijoin 这一篇就够了!
MySQL semijoin也被称为半连接,主要是解决外查询一个或多个表的记录在包含一个或多个表的子查询结果中的存在性问题,比如IN/EXIST子查询。如果按照IN/EXIST谓词的原语义去执行,对外查询的每行记录都去计算IN/EXIST谓词的结果,子查询的内容就需要单独执行,在关联子查询的情况下,子查询需要多次重复执行,整体的执行效率很低。实际上,部分存在性问题(SPJ 子查询)类似于外查询的多个表与子查询的多个表(以下简述为外表和内表)的连接(JOIN)问题,能连接上说明存在。但是与普通JOIN不同的点在于,当外表和内表JOIN的时候,外表的每行记录都有可能和内表的多行连接上,这就导致了外表行的重复记录,但是按照原语义IN/EXIST子查询只是对外表行上进行的过滤,数据只能减少,而不能膨胀。
如何在外表和内表JOIN的同时保证这一点呢?MySQL中实现了四种执行策略来避免重复行:Materialize、DuplicateWeedOut、FirstMatch 和LooseScan,以下是几种执行方式的简单概括和示意图。
select * from Country where Country.code IN (select City.Country from City where City.Population > 7*1000*1000) and Country.continent='Europe'
Materialize是将内表独立进行JOIN后的结果物化到临时表并去重,然后将物化表与其他外表做JOIN的执行方式。由于物化表已经去重,与外表做JOIN并不会引起数据膨胀,所以就变成普通的JOIN,与外表的JOIN ORDER可以任意调整。
 DuplicateWeedout是创建一个临时表,在执行将外表记录的主键写入临时表上带有唯一索引的rowids字段,起到对外表因为和内表JOIN之后产生的重复行去重的作用。
DuplicateWeedout是创建一个临时表,在执行将外表记录的主键写入临时表上带有唯一索引的rowids字段,起到对外表因为和内表JOIN之后产生的重复行去重的作用。

FirstMatch是在外表的一行记录和内表JOIN得到一行输出后,直接跳过所有内表接下来的数据行,读取外表的下一行执行,从而避免外表产生重复行的方式。
FirstMatch是在外表的一行记录和内表JOIN得到一行输出后,直接跳过所有内表接下来的数据行,读取外表的下一行执行,从而避免外表产生重复行的方式。
 LooseScan是在内表有索引存在的情况下,通过做内表上的LooseScan(仅扫描索引记录不相同的行)来达到对内表记录去重的目的,然后和外表进行连接,这样也不会导致外表出现重复行。
为什么要有四种执行策略呢?因为在内外表不同的JOIN ORDER、索引存在性、不同的JOIN条件情况下,只有特定的执行策略才能被应用,四种组合起来才构成了semijoin JOIN ORDER的灵活性,MySQL通过代价来选择JOIN ORDER和对应的执行策略。用以下SQL举例(后续文章中均采用同一 schema),ct表示correlated table,为外查询中与子查询关联的表;it表示inner table,为子查询的内表。
LooseScan是在内表有索引存在的情况下,通过做内表上的LooseScan(仅扫描索引记录不相同的行)来达到对内表记录去重的目的,然后和外表进行连接,这样也不会导致外表出现重复行。
为什么要有四种执行策略呢?因为在内外表不同的JOIN ORDER、索引存在性、不同的JOIN条件情况下,只有特定的执行策略才能被应用,四种组合起来才构成了semijoin JOIN ORDER的灵活性,MySQL通过代价来选择JOIN ORDER和对应的执行策略。用以下SQL举例(后续文章中均采用同一 schema),ct表示correlated table,为外查询中与子查询关联的表;it表示inner table,为子查询的内表。
CREATE TABLE t1 ( a INT, b INT, KEY(a), KEY(b));
INSERT INTO t1 VALUES (1, 2), (3, 4), (5, 6), (7, 8), (9, 10), (2, 1), (4, 3), (5, 6);
CREATE TABLE ct1 LIKE t1;INSERT INTO ct1 SELECT * FROM t1;
CREATE TABLE ct2 LIKE t1;INSERT INTO ct2 SELECT * FROM t1;
CREATE TABLE it1 LIKE t1;INSERT INTO it1 SELECT * FROM t1;
CREATE TABLE it2 LIKE t1;INSERT INTO it2 SELECT * FROM t1;
SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
重点关注JOIN ORDER中外表和内表的相对顺序(括号内的表连接顺序可变),得到执行策略对JOIN ORDER的支持如下:
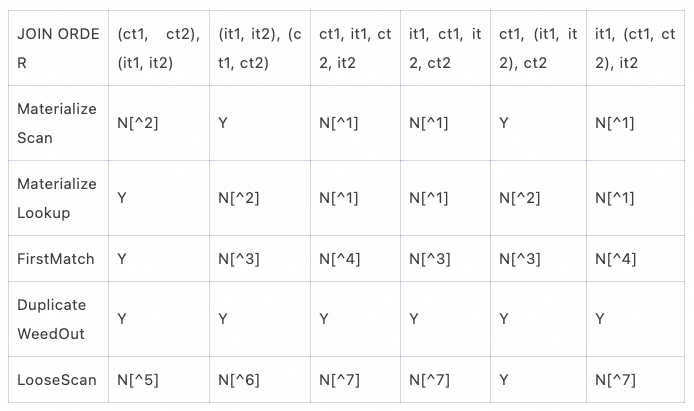
[^1]: Inner tables are not joined together.
[^2]: MaterializeLookup requires all dependent tables are in front of the inner tables. Use MaterializeScan instead.
[^3]: FirstMatch requires all dependent tables are in front of the inner tables.
[^4]: FirstMatch doesn't allow any outer tables to be interleaved within inner tables.
[^5]: LooseScan requires there exists at least a correlated outer table appears after the LooseScan inner table.
[^6]: LooseScan requires all semijoin conditions after the LooseScan table are only dependent on index columns of LooseScan.
[^7]: LooseScan requires inner tables appear continuously.
可以看到DuplicateWeedOut是最通用的策略,其他的策略只能应用在特定的JOIN ORDER下。表格中没有覆盖it表之间、ot表之间交换顺序的情况;以及原SQL中还包含其他不和IN/EXIST子查询关联的外表时,大部分情况下,该外表可以在ct表之间灵活交换顺序,或者处于semijoin范围之外任意位置,所以实际场景中每种执行策略支持的JOIN ORDER范围会更广。
以下就深入内核,探寻semijoin应用的条件和优化器如何根据代价决定semijoin执行策略的。
在对外层查询的谓词resolve/fix_fields()过程中,递归对子查询Query_block::prepare,由子查询自身调用Query_block::resolve_subquery,判断可以转换为semijoin的基本条件,如果满足的话,就会将子查询对应的Item_exists_subselect(Item_in_subselect的基类)加入外层查询的Query_block::sj_candidates数组中,等待递归返回后,外层查询调用Query_block::flatten_subqueries处理。这些基本条件包括:
1. 子查询是IN/EXIST类型,=ANY也会是IN子查询;
2. 是一个简单查询块(非UNION/INTERSECT/EXCEPT等集合操作符组成);
3. 不带有显式或隐式的聚集函数、不带有HAVING 和WINDOW函数(Semijoin 是将子查询里的表提出来与外层的表先join后再做后续运算,而这些操作符都是需要先读取完子查询里的表做运算后才能计算外层的谓词);
4. 子查询处于ON/WHERE语法中,且是AND谓词连接的top level;
5. 谓词True/False、nullability是和转换兼容的。
简单来说,最主要的条件就是SPJ的IN/EXIST子查询。
在bottom-up的resolve过程中,由包含semijoin候选的外层查询块将子查询的表上拉,并消除子查询,这一过程在
Query_block::flatten_subqueries
中。
for SELECT#1 WHERE X IN (SELECT #2 WHERE Y IN (SELECT#3)) :
Query_block::prepare() (select#1) -> fix_fields() on IN condition -> Query_block::prepare() on subquery (select#2) -> fix_fields() on IN condition -> Query_block::prepare() on subquery (select#3) -> flatten_subqueries: merge #3 in #2 -> flatten_subqueries: merge #2 in #1
在外层查询块中,依次遍历所有semijoin的候选子查询:
1. 将它们在外层查询块的谓词位置(WHERE 条件或者嵌套join的ON条件)用恒True表达式替换;
2. 创
建semijoin nested Table_ref结构,加入到嵌套的join nest结构或者outer-most join list中,以下简称 (sj-nest);
3. 将子查询所有的表加入到Table_ref::NESTED_JOIN中,链接进外层查询的 leaf_tables,给这些表按照外层的tableno重新编号;
4. 构建NESTED_JOIN::sj_outer_exprs和NESTED_JOIN::sj_inner_exprs向量,IN 子查询就是左表达式和子查询投影列一一对应起来,EXIST子查询就是WHERE/ON 条件中的关联条件(IN子查询也会收集这些关联条件来方便执行使用),被收集的条件原有位置置空或者True,比如下列谓词:
ot1.a = ANY(SELECT it1.a FROM it1, it2)收集到sj_outer_exprs: ot1.a; sj_inner_exprs: it1.a
ot1.a = ANY(SELECT it1.a FROM it1, it2 WHERE it1.b = ot2.b)收集到 sj_outer_exprs: ot1.a, ot2.b; sj_inner_exprs: it1.a, it1.b。
5. 确定子查询中剩下的WHERE/ON条件所依赖的外层表集合 NESTED_JOIN::sj_corr_tables(非简单关联条件,用于优化过程中判断semijoin条件是否可计算);
6. 用sj_outer_exprs和sj_inner_exprs构建多个Item_func_eq表达式,与子查询剩下的 WHERE 条件结合,放入到外层查询对应JOIN/WHERE条件上;
7. NESTED_JOIN::sj_depends_on包含所有semijoin条件和子查询WHERE条件中对原外查询中表的依赖,标记查询块 has_sj_nests/has_aj_nests 为 True。
之后,在Query_block::apply_local_transforms -> Query_block::simplify_joins 中,会对嵌套的semijoin/anti-join做简单处理,将嵌套的结构展平,因为外层的结构是semijoin时,内层的输出结果是否发生重复也不影响结果,比如A SJ (B SJ (C)) -> A SJ (B JOIN C), A AJ (B SJ (C)) -> A AJ (B JOIN C)。将内层的semijoin的表移到外层的join list中,并移除原内层(sj-nest)。记录(sj-nest) Table_ref::sj_inner_tables为原子查询所有内表的used_tables,将所有的(sj-nest)加入当前查询块的Query_block::sj_nests数组中。
MySQL对semijoin的执行支持好几种不同的执行策略,在不同的执行策略下 semijoin内表和外表的JOIN ORDER不同,从而能够提供更为灵活的JOIN ORDER选择;不同的执行策略通过不同的方式来达到去重的目的,避免原本的semijoin转化为JOIN之后的数据膨胀;不同的执行策略可以利用上不同的索引或者表访问方式。这些执行策略包括:FirstMatch、DuplicateWeedout、LooseScan、Materialize,Materialize根据物化表和外表JOIN ORDER的不同又分为MaterializeScan和 MaterializeLookup。优化器的目的就是评估这些执行策略的可行性(开关、索引是否支持等),选择估算代价最低的策略。
本小节会介绍这些执行策略的公共处理逻辑,具体到每种执行策略的不同和优化细节将会在以下每种执行策略的章节介绍。
主要的过程在JOIN::make_join_plan中:
在update_ref_and_keys之后,如果semijoin的内表是可以eq_ref(唯一索引) 外表,且(sj-nest)中不存在其他内表依赖它,那么该表就可以从(sj-nest)中移出来,放置在外层的join list中,因为这样的表和外层表join是不会产生数据膨胀的。这样可以简化 (sj-nest)的内表结构,如果所有的内表都可以被提出来,那么(sj-nest) 就可以被直接移除,消除了semijoin。
在外层优化之前,为可能选择Materialize执行的(sj-nest)优化内表的JOIN ORDER,计算其cost和fanout,基于这些数据才能在和外层表的优化过程中计算 cost。详细见Materialize章节。
每当一个新表(外表 + 子查询的内表)被尝试加入到JOIN序列,且选择完它的最优访问方式(best_access_path)后,就会调用
Optimize_table_order::advance_sj_state 考虑此时可用
的semijoin执行策略,并计算不同策略各自的cost,选择最低代价的策略作为当前JOIN序列的最优策略,存放在当前表的POSITION中(不同策略有不同的状态变量),并且更新最优策略下的代价和cardinality(prefix_cost和prefix_rowcount)。
注意,这里对于部分执行方式,比如Materilize/FirstMatch会重新评估一定范围内每个表的访问方式,以算出在当前策略下,选取最优访问方式后的代价。但是这些访问方式的重新考虑并不会持久
化到JOIN::positions枚举状态中,避免对外层接下来greedy search的影响。只是会持久化prefix_cost/prefix_rowcount和当前表POSITION中记录semijoin执行策略选择的变量,如果枚举完整JOIN序列仍然是最优 plan,就会持久化到best_positions中。所以当整个greedy search结束,在 Optimize_table_order::fix_semijoin_strategies 识别到POSITION中关于semijoin的策略选择结果,需要对涉及表的访问方式再次做选择,此时
持久化访问方式。
具体对每种执行策略在代价上的考虑,在以下各执行策略章节陈述。
Materialize
Materialize是将 (sj-nest) 的内表JOIN结果物化到临时表并去重后,物化表与其他外表做JOIN的执行方式。由于物化表已经去重,与外表做JOIN并不会引起数据膨胀,所以就变成普通的JOIN,与外表的JOIN ORDER可以任意调整。根据物化表最终是全表扫、还是在临时表上索引的eq_ref lookup分为MaterializeScan和MaterializeLookup两种方式。
JOIN::make_join_plan -> optimize_semijoin_nests_for_materialization |--遍历所有的 (sj-nest) |--如果 NESTED_JOIN::sj_corr_tables 不为空,意味着子查询存在无法提取的复杂关联条件,这种情况下子查询无法独立物化,跳过 |--semijoin_types_allow_materialization/types_allow_materialization 检查类型能否物化,物化表索引长度是否超过最大值 |--Optimize_table_order::choose_table_order // 对 semijoin 的内表集合选取最优 join order |--calculate_materialization_costs // 计算物化表的 NDV、物化的代价、全表扫物化表的代价、物化表 lookup 的代价, // 存放在 NESTED_JOIN::Semijoin_mat_optimize 中,方便后续不同执行策略的代价比较 |--根据优化得到的 best_positions 里每个表的 read_cost 和 evaluate cost 计算物化代价和 fanout 行数 |--fanout 行数简单的与每个表的输出行数乘积取较小值作为物化表的输出 NDV |--Cost_model_server::tmptable_readwrite_cost 计算物化表操作代价 |--将 best_positions 信息存储在 Semijoin_mat_optimize::positions 数组中作为 (sj-nest) 内表的最优计划
MaterializeScan
SET optimizer_switch='semijoin=on,materialization=on,loosescan=off,firstmatch=off,duplicateweedout=off';
EXPLAIN SELECT /*+ JOIN_SUFFIX(ct1, ct2) */ * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);+----+--------------+-------------+------------+-------+---------------+------+---------+---------------+------+----------+--------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------+-------------+------------+-------+---------------+------+---------+---------------+------+----------+--------------------------------------------+| 1 | SIMPLE | | NULL | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | Using where || 1 | SIMPLE | ct1 | NULL | ref | a | a | 5 | .a | 1 | 100.00 | NULL || 1 | SIMPLE | ct2 | NULL | ref | b | b | 5 | .b | 1 | 100.00 | NULL || 2 | MATERIALIZED | it1 | NULL | index | a | a | 5 | NULL | 16 | 100.00 | Using index || 2 | MATERIALIZED | it2 | NULL | index | b | b | 5 | NULL | 16 | 100.00 | Using index; Using join buffer (hash join) |+----+--------------+-------------+------------+-------+---------------+------+---------+---------------+------+----------+--------------------------------------------+
| -> Nested loop inner join (cost=259 rows=334) -> Nested loop inner join (cost=142 rows=293) -> Filter: ((``.a is not null) and (``.b is not null)) (cost=53.2..39.2 rows=256) -> Table scan on (cost=53.3..59 rows=256) -> Materialize with deduplication (cost=53.3..53.3 rows=256) -> Filter: ((it1.a is not null) and (it2.b is not null)) (cost=27.7 rows=256) -> Inner hash join (no condition) (cost=27.7 rows=256) -> Index scan on it2 using b (cost=0.116 rows=16) -> Hash -> Index scan on it1 using a (cost=1.85 rows=16) -> Index lookup on ct1 using a (a=``.a) (cost=0.286 rows=1.14) -> Index lookup on ct2 using b (b=``.b) (cost=73.2 rows=1.14) |
-
Optimize_table_order::advance_sj_state
开始考虑MaterializeScan执行方式的前提条件(semijoin_order_allows_materialization)为,当前表为(sj-nest) 内表,且所有其他内表都出现在前序且连续。代码里用POSITION::sjm_scan_last_inner来表示内表的最后一个位置,从下标 sjm_scan_last_inner - Table_ref::sj_inner_tables + 1 ~ sjm_scan_last_inner 为内表 POSITION 的范围。
从这个位置开始,将POSITION::sjm_scan_need_tables
设置为所有 sj_inner_tables和NESTED_JOIN::sj_depends_on(semijoin条件依赖的外表)的集合,表示当这些表都处于JOIN前序时,才能做MaterializeScan的JOIN。满足条件的情况下,会基于物化表的fanout重新评估sjm_scan_last_inner到当前位置所有外表的访问方式(遍历表调用best_access_path传入新的fanout),来计算如果选择MaterializeScan执行策略的代价,这个过程在Optimize_table_order::semijoin_mat_scan_access_paths中。
-
如果当前 JOIN 前缀下,MaterializeScan已经是代价最低的策略,那么会标记当前外表的:
POSITION::sj_strategy
为SJ_OPT_MATERIALIZE_SCAN
同时加入下一个外表时,不再重新考虑MaterializeScan的访问方式代价,因为此时已经将之前选择SJ_OPT_MATERIALIZE_SCAN的POSITION::prefix_cost/prefix_rowcount设置为MaterializeScan的结果值,所以后续表的访问方式评估时已经是基于MaterializeScan计划的cardinality和代价,不需要重新评估。
-
否则,如果MaterializeScan并不是当前最优的semijoin策略,那么会在greedy search搜索到下一个新表时重复进行考虑,因为 MaterializeScan下前序的 cardinality不同,对于后续表的访问方式都可能产生影响。
MaterializeLookup
SET optimizer_switch='semijoin=on,materialization=on,loosescan=off,firstmatch=off,duplicateweedout=off';
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+-----------------------+------+----------+------------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+-----------------------+------+----------+------------------------------------------------------+| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where || 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) || 1 | SIMPLE | | NULL | eq_ref | | | 10 | test.ct1.a,test.ct2.b | 1 | 100.00 | NULL || 2 | MATERIALIZED | it1 | NULL | index | a | a | 5 | NULL | 16 | 100.00 | Using index || 2 | MATERIALIZED | it2 | NULL | index | b | b | 5 | NULL | 16 | 100.00 | Using index; Using join buffer (hash join) |+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+-----------------------+------+----------+------------------------------------------------------+
| -> Nested loop inner join (cost=1653 rows=16384) -> Inner hash join (no condition) (cost=7.7 rows=64) -> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.131 rows=8) -> Hash -> Filter: (ct1.a is not null) (cost=1.05 rows=8) -> Table scan on ct1 (cost=1.05 rows=8) -> Single-row index lookup on using (a=ct1.a, b=ct2.b) (cost=53.3..53.3 rows=1) -> Materialize with deduplication (cost=53.3..53.3 rows=256) -> Filter: ((it1.a is not null) and (it2.b is not null)) (cost=27.7 rows=256) -> Inner hash join (no condition) (cost=27.7 rows=256) -> Index scan on it2 using b (cost=0.116 rows=16) -> Hash -> Index scan on it1 using a (cost=1.85 rows=16) |
-
Optimize_table_order::advance_sj_state
考虑MaterializeLookup执行策略的条件为,(sj-nest) 的内表在 JOIN 前序紧密相连,且semijoin条件依赖的外表也都出现了,那么就可以考虑在物化表上使用eq_ref的JOIN方式。在semijoin_mat_lookup_access_paths函数中,基于前序最后一个外表的prefix_rowcount来计算物化表lookup的代价,加上物化表setup的代价作为这种执行方式的最终代价。
DuplicateWeedOut
DuplicateWeedout适用的范围更广,原外层表和内层表之间的JOIN ORDER可以更灵活,实现原理就是创建一个临时表起到对外表因为和内表JOIN之后产生的数据膨胀去重的作用。当外表和(sj-nest)内表JOIN之后,会将semijoin涉及的外表主键紧密连接到一起,形成字符串写入weedout-tmp临时表的rowids字段中,在这个字段上存在唯一索引。如果写入成功,说明当前行组合是第一次出现,继续往后JOIN;否则直接跳过该行。
SET optimizer_switch='semijoin=on,materialization=off,loosescan=off,firstmatch=off,duplicateweedout=on';
# 传统格式的 EXPLAIN 中比较明显的标识是 Start temporary/End temporary。EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where; Start temporary || 1 | SIMPLE | it1 | NULL | ref | a | a | 5 | test.ct1.a | 2 | 100.00 | Using index || 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) || 1 | SIMPLE | it2 | NULL | ref | b | b | 5 | test.ct2.b | 2 | 100.00 | Using index; End temporary |+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+
| -> Remove duplicate (ct1, ct2) rows using temporary table (weedout) (cost=89.8 rows=334) -> Nested loop inner join (cost=89.8 rows=334) -> Inner hash join (no condition) (cost=19.8 rows=146) -> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.0574 rows=8) -> Hash -> Nested loop inner join (cost=4.88 rows=18.3) -> Filter: (ct1.a is not null) (cost=1.05 rows=8) -> Table scan on ct1 (cost=1.05 rows=8) -> Covering index lookup on it1 using a (a=ct1.a) (cost=0.279 rows=2.29) -> Covering index lookup on it2 using b (b=ct2.b) (cost=1.32 rows=2.29) |
-
Optimize_table_order::advance_sj_state
考虑DuplicateWeedOut的条件很简单,就是sj-cond所有依赖的表(外表/内表)都已经出现在JOIN前缀时,就可以将JOIN的结果写入临时表进行去重了。POSITION::dupsweedout_tables记录了这些依赖表的组合;POSITION::first_dupsweedout_table记录的是(sj-nest)第一个内表出现的位置,之所以记录这个是方便计算inner_tables
的存在对JOIN序列 fanout 的影响。
在满足条件后,每加入一个新的表到JOIN前缀中,都会重新考虑 DuplicateWeedOut的代价
,因为这些JOIN前缀产生的cardinality不同,导致临时表读取和写入的代价也不一样。代价的考虑在semijoin_dupsweedout_access_paths中,这里并不会对表的访问方式做重新考虑,只是着重计算经过去重后的fanout和临时表写入/读取的代价。对fanout的计算也不是很准确,用表行数最大的fanout做了限制。调用Cost_model_server::tmptable_readwrite_cost对临时表读写代价进行估算,读的行数为内外表JOIN产生的cardinality行数,写入的行数
为估算最终外表JOIN产生的行数。
WeedoutIterator::Read |--m_source -> RowIterator::Read // 调用子算子完成前序 JOIN 过程 |--do_sj_dups_weedout |--对涉及到的外表主键使用 memcpy 进行紧密填充 |--handler::ha_write_row // 向临时表中写入 rowids 字段进行去重
FirstMatch
FirstMatch是在和 (sj-nest) 的内表JOIN到一条输出后,跳过全部inner_tables 接下来的数据行,直接跳到JOIN前序最后一个outer_table的位置,读取其下一行进行连接。FirstMatch的JOIN序列范围内最后一定是连续的全部inner_tables,不能穿插任何外表,假如是ct1, it1, ct2, it2序列,如果跳到ct2位置,那么会产生由于it1存在JOIN出的重复行;如果跳到ct1位置,那么会丢失ct1和ct2剩余数据可能JOIN出来的其他行。
SET optimizer_switch='semijoin=on,materialization=off,loosescan=off,firstmatch=on,duplicateweedout=off';
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where || 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) || 1 | SIMPLE | it1 | NULL | ref | a | a | 5 | test.ct1.a | 2 | 100.00 | Using index || 1 | SIMPLE | it2 | NULL | ref | b | b | 5 | test.ct2.b | 2 | 100.00 | Using index; FirstMatch(ct2) |+----+-------------+-------+------------+-------+---------------+------+---------+------------+------+----------+------------------------------------------------------+
| -> Nested loop semijoin (cost=57.2 rows=334) -> Inner hash join (no condition) (cost=7.7 rows=64) -> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.131 rows=8) -> Hash -> Filter: (ct1.a is not null) (cost=1.05 rows=8) -> Table scan on ct1 (cost=1.05 rows=8) -> Nested loop inner join (cost=37.4 rows=5.22) -> Covering index lookup on it1 using a (a=ct1.a) (cost=0.254 rows=2.29) -> Covering index lookup on it2 using b (b=ct2.b) (cost=1.32 rows=2.29) |
-
Optimize_table_order::advance_sj_state
当所有依赖的外表都已经在 JOIN 前序里,(sj-nest) 所有内表都连续出现,当前表为
最后一个内表时,考虑FirstMatch的执行策略。POSITION::first_firstmatch_table存放第一个内表的位置,最终执行时跳到的位置为其前一个外表,当出现不连续的内表时通过将该变量重置来避免FirstMatch的考虑。POSITION::dups_producing_tables为前序可能产生JOIN重复数据的内表,当这个值不为0时说明处于一个semijoin的中间,不能开
启一个新的semijoin执行策略考虑范围。
在Optimize_table_order::semijoin_firstmatch_loosescan_access_paths中计算FirstMatch的代价,考虑表的范围为inner_tables的第一个表到最后一个表,重新评估这些表的访问方式的原因是由于在JOIN出来第一行数据后,可以直接跳回最后一个外表的下一行数据,因此如果某些内表选择了JOIN BUFFER,缓存的数据就浪费了。所以仅对选择JOIN BUFFER的内表禁止JOIN BUFFER重新调用best_access_path决定计算访问方式和代价;如果只存在一个inner table,那么前面的外表是可以使用JOIN BU
FFER的。
对于代价的计算,由于快速跳回的执行机制存在,优化器认为平均每个内表只需要访问一次,所以将POSITION::read_cost累加起来,需要evaluate的records数为内/外表的fanout乘积,最终的cardinality为外表的fanout乘积。
在执行器中实现FirstMatch的能力比较简单,只需要在对应的JOIN iterator上设置JOIN类型为semijoin或者某些状态变量,让内层算子在JOIN到一行数据后,能够跳出内层的JOIN,直接读取外层表的下一行数据即可。举个例子:










