机器之心整理
演讲者:
Ian Goodfellow
参与:吴攀、李亚洲
面向开发者的世界上最大的人工智能主题在线演讲与对话大会 AI WITH THE BEST(AIWTB)于 2017 年 4 月 29-30 日在 AIWTB 官网上通过在线直播的方式举办。作为第三届 AI WITH THE BEST 华语社区独家合作伙伴,今年线上大会机器之心有免费赠门票资格。在此前的问题征集赠票活动中,我们从读者提问中选出了 1 个高质量问题并赠送了参会票。
在本文中,机器之心对这次对话大会上 Ian Goodfellow 的演讲和对话内容进行了梳理,文后还附带了 IProgrammer 在会前对 Ian Goodfellow 的关于该在线会议的采访内容。
Ian Goodfellow 是谷歌大脑的一位研究科学家,是生成对抗网络(GAN)的提出者,也是《Deep Learning》的作者之一。他此次的演讲主题为《机器学习的隐私与安全(Machine learning privacy and security)》。
演讲主题:随着机器学习算法得到越来越广泛的使用,确保它们能够提供隐私和安全保证是很重要的。在这个演讲中,Ian Goodfellow 概述了一些对手可以用来攻击机器学习模型的方法,以及一些我们可以用来进行防御的措施,比如对抗训练(adversarial training)和差分隐私(differential privacy)。此次大会,AI With the Best 也邀请了 Nicolas Papernot、Patrick McDanel 和 Dawn Song 来对其中一些主题进行详细解读。
演讲内容介绍
前面介绍了,AI With the Best 线上大会分为两部分内容:在线演讲、在线对话。在这一部分,我们对 Ian Goodfellow 演讲的内容进行了梳理。

Goodfellow 的演讲主题为《机器学习的隐私与安全(Machine learning privacy and security)》,其中重点介绍了对抗样本和差分隐私。在对抗样本部分,他重点解读了在训练时间和测试时间对模型的干扰。在差分隐私部分,他介绍了差分隐私的定义和当前这一领域最先进的算法 PATE-G。

斯坦福的研究者做了一个很有意思的研究:首先用一种对人类而言看起来像是噪声的信号(实际上是经过精心设计的)「污染」训练集的图片,比如上图左侧中狗的照片,得到上图右侧的照片,对我们人类而言看起来还是狗。用原始训练集训练模型后,模型识别下图有 97.8% 的概率是「狗」;而用被「污染」过的图片和标签训练模型之后,模型会把下图显然的狗标记为「鱼」,置信度为 69.7%。这个研究表明我们可以通过影响训练集来干扰测试结果。

除了在训练时间对模型进行干扰,我们也可以在测试时间干扰模型。对于实际投入应用的机器学习模型来说,这个阶段的攻击更值得关注。比如说左边的熊猫照片,如果我们给它加上一点看起来像是噪声的信号,然后得到右边的图像——看起来仍然是熊猫;但对一个计算机视觉系统来说,它看起来却像是一个长臂猿。
这个过程中到底发生了什么?当然实际上,那个看起来像是噪声的信号并不是噪声,真正的噪声信号对神经网络的结果的影响不会有这么大。实际上这是经过精心计算的信号,目标就是诱导机器学习系统犯错。

为什么这个问题很重要呢?自 2013 年以来,深度神经网络已经在目标和人脸识别、破解验证码和阅读地址等任务上达到或接近了人类的水平,并且也实现了很多应用。通过上面提到的方法,我们可以影响这些系统的表现,使对抗样本具有潜在危险性。比如,攻击者可能会用贴纸或者一幅画做一个对抗式「停止」交通标志,将攻击对象瞄准自动驾驶汽车,这样,车辆就可能将这一「标志」解释为「放弃」或其他标识,进而引发危险。研究《Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples》讨论过这个问题。

让不同的物体被识别为「飞机」

现代深度网络是非常分段线性的
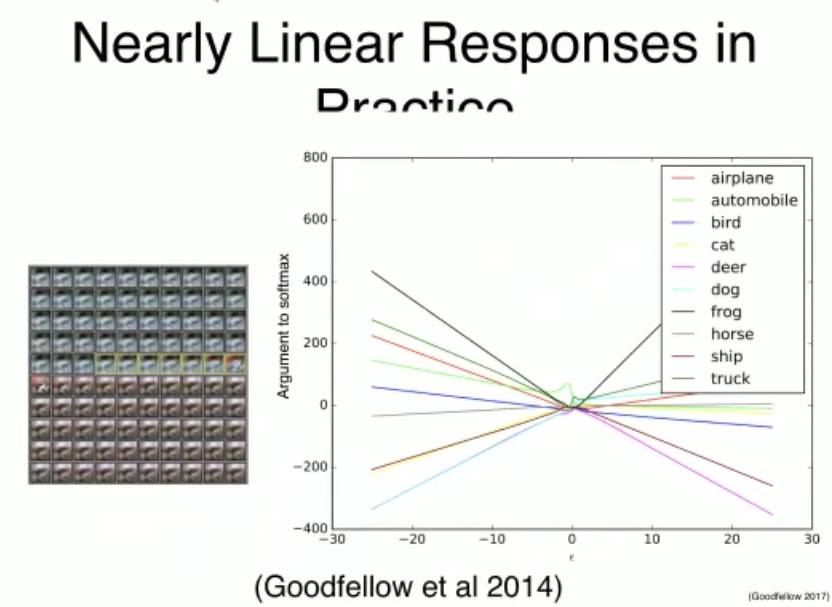
反应中的接近线性的响应
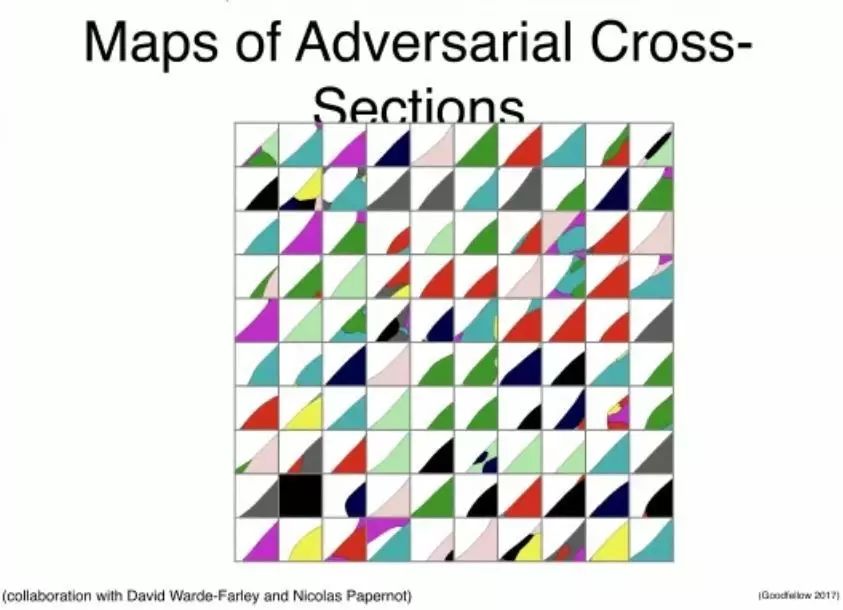
对抗样本不是噪声

让高斯噪声被识别为一架飞机

同样方向的干扰可以在许多输入上欺骗模型(后来被称为「通用对抗扰动」)

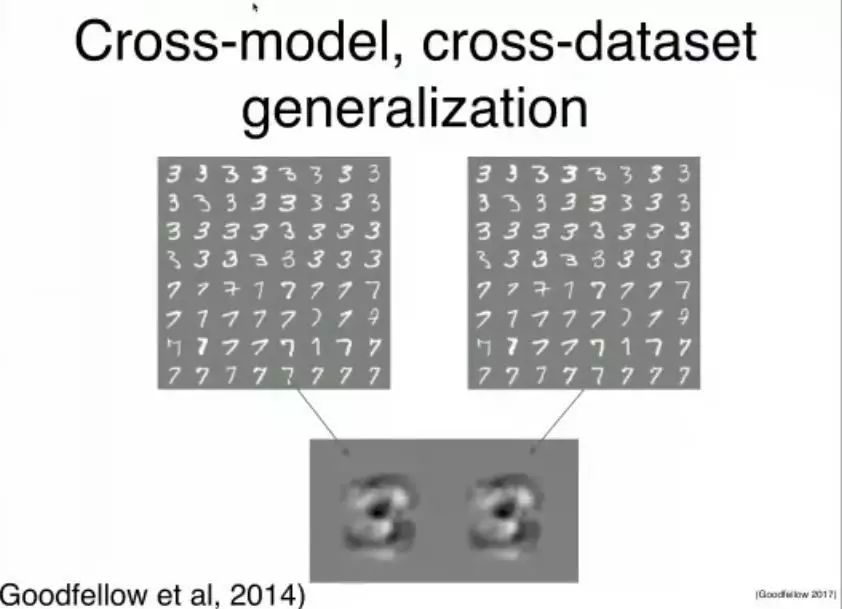
跨模型、跨数据集泛化
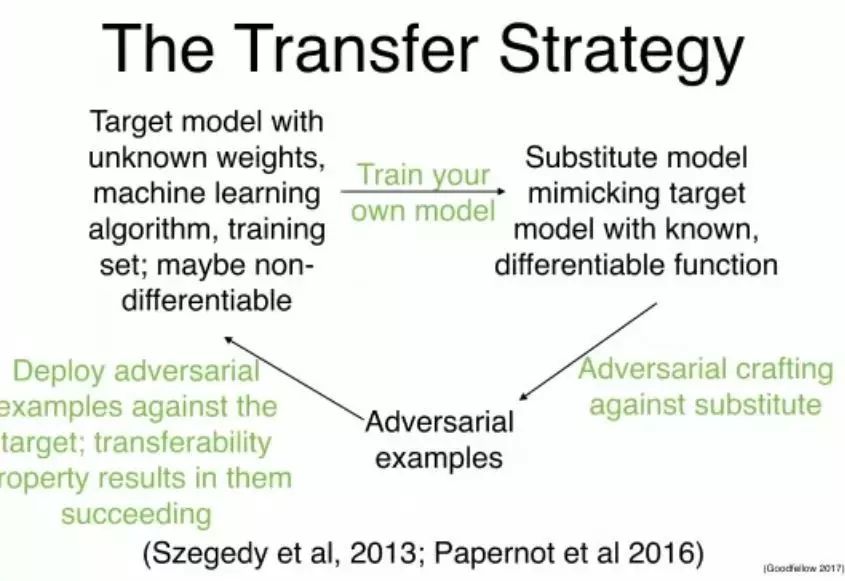
迁移策略
→带有未知权重的目标模型,机器学习算法、训练集;也许是不可微分的——(训练你自己的模型)→替代模型使用已知的可微分的函数来模拟目标模型——(对抗性的设计来对抗替代)→对抗样本——(部署对抗样本来对抗目标;迁移性导致它们的成功)→

对抗样本的实际应用
欺骗通过远程托管的 API(MetaMind、亚马逊、谷歌)训练的真实分类器
欺骗恶意软件检测器网络
在物理世界中展示对抗样本,通过一个相机欺骗机器学习系统相信它们

物理世界中的对抗样本

用于强化学习的对抗样本。伯克利、OpenAI 以及宾大联合发表的论文《Adversarial Attacks on Neural Network Policies》,内华达大学《Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks》等研究表明强化学习智能体也能被对抗样本操控。研究表明,广为采用的强化学习算法(比如,DQN、TRPO 以及 A3C)都经不起对抗样本的捉弄。这些对抗样本输入会降低系统性能,即使扰乱微妙地让人类也难以察觉,智能体会在应该往上移动的时候却将球拍向下移动,或者在 Seaquest 中识别敌人的能力受到干扰。

失败的防御方法,其中包括生成式预训练、使用自动编码器移除干扰、纠错代码、权重衰减、多种非线性单元等等








