从输入 URL 到页面加载完成的过程中都发生了什么事情?
来源:fexweb前端 http://wuduoyi.com
编辑:Gemini
背景
本文来自于之前我发的一篇微博:

不过写这篇文章并不是为了帮大家准备面试,而是想借这道题来介绍计算机和互联网的基础知识,让读者了解它们之间是如何关联起来的。
为了便于理解,我将整个过程分为了六个问题来展开。
第一个问题:从输入 URL 到浏览器接收的过程中发生了什么事情?
从触屏到 CPU
首先是「输入 URL」,大部分人的第一反应会是键盘,不过为了与时俱进,这里将介绍触摸屏设备的交互。
触摸屏一种传感器,目前大多是基于电容(Capacitive)来实现的,以前都是直接覆盖在显示屏上的,不过最近出现了 3 种嵌入到显示屏中的技术,第一种是 iPhone 5 的 In-cell,它能减小了 0.5 毫米的厚度,第二种是三星使用的 On-cell 技术,第三种是国内厂商喜欢用的 OGS 全贴合技术,具体细节可以阅读
这篇文章http://www.igao7.com/news/201406/in-cell-on-cell-ogs.html
。
当手指在这个传感器上触摸时,有些电子会传递到手上,从而导致该区域的电压变化,触摸屏控制器芯片根据这个变化就能计算出所触摸的位置,然后通过总线接口将信号传到 CPU 的引脚上。
以 Nexus 5 为例,它所使用的触屏控制器是
Synaptics S3350B
,总线接口为
I²C
,以下是 Synaptics 触摸屏和处理器连接的示例:
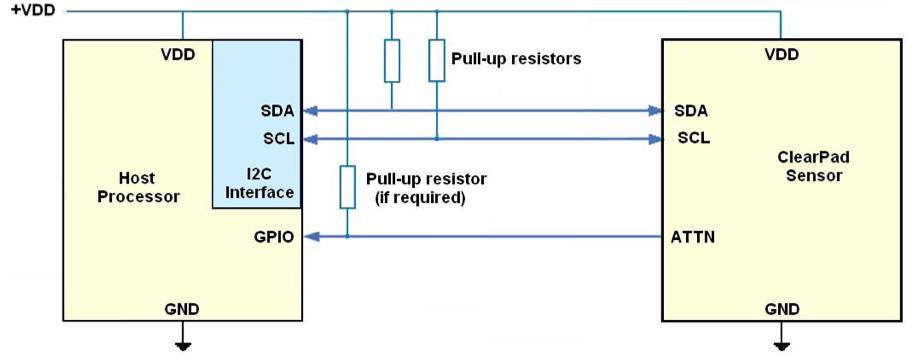
左边是处理器,右边是触摸屏控制器,中间的 SDA 和 SCL 连线就是 I²C 总线接口。
CPU 内部的处理
移动设备中的 CPU 并不是一个单独的芯片,而是和 GPU 等芯片集成在一起,被称为 SoC(片上系统)。
前面提到了触屏和 CPU 的连接,这个连接和大部分计算机内部的连接一样,都是通过电气信号来进行通信的,也就是电压高低的变化,如下面的时序图:

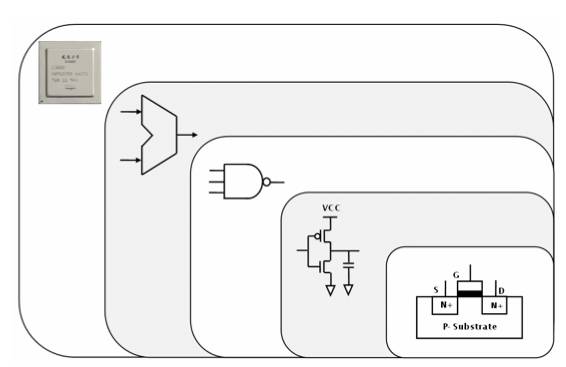
在时钟的控制下,这些电流会经过
MOSFET
晶体管,晶体管中包含 N 型半导体和 P 型半导体,通过电压就能控制线路开闭,然后这些 MOSFET 构成了
CMOS
,接着再由 CMOS 实现「与」「或」「非」等逻辑电路门,最后由逻辑电路门上就能实现加法、位移等计算,整体如下图所示(来自《计算机体系结构》):
除了计算,在 CPU 中还需要存储单元来加载和存储数据,这个存储单元一般通过触发器(Flip-flop)来实现,称为寄存器。
以上这些概念都比较抽象,推荐阅读「
How to Build an 8-Bit Computer http://www.instructables.com/id/How-to-Build-an-8-Bit-Computer/
」这篇文章,作者基于晶体管、二极管、电容等原件制作了一个 8 位的计算机,支持简单汇编指令和结果输出,虽然现代 CPU 的实现要比这个复杂得多,但基本原理还是一样的。
另外其实我也是刚开始学习 CPU 芯片的实现,所以就不在这误人子弟了,感兴趣的读者请阅读本节后面推荐的书籍。
从 CPU 到操作系统内核
前面说到触屏控制器将电气信号发送到 CPU 对应的引脚上,接着就会触发 CPU 的中断机制,以 Linux 为例,每个外部设备都有一标识符,称为中断请求(IRQ)号,可以通过
/proc/interrupts
文件来查看系统中所有设备的中断请求号,以下是 Nexus 7 (2013) 的部分结果:
shell@flo:/ $ cat /proc/interrupts
CPU0
17: 0 GIC dg_timer
294: 1973609 msmgpio elan-ktf3k
314: 679 msmgpio KEY_POWER
因为 Nexus 7 使用了 ELAN 的触屏控制器,所以结果中的 elan-ktf3k 就是触屏的中断请求信息,其中 294 是中断号,1973609 是触发的次数(手指单击时会产生两次中断,但滑动时会产生上百次中断)。
为了简化这里不考虑优先级问题,以 ARMv7 架构的处理器为例,当中断发生时,CPU 会停下当前运行的程序,保存当前执行状态(如 PC 值),进入 IRQ 状态),然后跳转到对应的中断处理程序执行,这个程序一般由第三方内核驱动来实现,比如前面提到的 Nexus 7 的驱动源码在这里
touchscreen/ektf3k.c
https://android.googlesource.com/kernel/tegra/+/android-tegra3-grouper-3.1-kitkat-mr1/drivers/input/touchscreen/ektf3k.c
。
这个驱动程序将读取 I²C 总线中传来的位置数据,然后通过内核的
input_report_abs
等方法记录触屏按下坐标等信息,最后由内核中的
input 子模块
将这些信息都写进
/dev/input/event0
这个设备文件中,比如下面展示了一次触摸事件所产生的信息:
130|shell@flo:/ $ getevent -lt /dev/input/event0
[ 414624.658986] EV_ABS ABS_MT_TRACKING_ID 0000835c
[ 414624.659017] EV_ABS ABS_MT_TOUCH_MAJOR 0000000b
[ 414624.659047] EV_ABS ABS_MT_PRESSURE 0000001d
[ 414624.659047] EV_ABS ABS_MT_POSITION_X 000003f0
[ 414624.659078] EV_ABS ABS_MT_POSITION_Y 00000588
[ 414624.659078] EV_SYN SYN_REPORT 00000000
[ 414624.699239] EV_ABS ABS_MT_TRACKING_ID ffffffff
[ 414624.699270] EV_SYN SYN_REPORT 00000000
从操作系统 GUI 到浏览器
前面提到 Linux 内核已经完成了对硬件的抽象,其它程序只需要通过监听
/dev/input/event0
文件的变化就能知道用户进行了哪些触摸操作,不过如果每个程序都这么做实在太麻烦了,所以在图像操作系统中都会包含 GUI 框架来方便应用程序开发,比如 Linux 下著名的
X
。
但 Android 并没有使用 X,而是自己实现了一套 GUI 框架,其中有个
EventHub
的服务会通过
epoll
方式监听
/dev/input/
目录下的文件,然后将这些信息传递到 Android 的窗口管理服务(
WindowManagerService
)中,它会根据位置信息来查找相应的 app,然后调用其中的监听函数(如 onTouch 等)。
就这样,我们解答了第一个问题,不过由于时间有限,这里省略了很多细节,想进一步学习的读者推荐阅读以下书籍。
扩展学习
第二个问题:浏览器如何向网卡发送数据?
从浏览器到浏览器内核
前面提到操作系统 GUI 将输入事件传递到了浏览器中,在这过程中,浏览器可能会做一些预处理,比如 Chrome 会根据历史统计来预估所输入字符对应的网站,比如输入了「ba」,根据之前的历史发现 90% 的概率会访问「www.baidu.com 」,因此就会在输入回车前就马上开始建立 TCP 链接甚至渲染了,这里面还有很多其它策略,感兴趣的读者推荐阅读
High Performance Networking in Chrome
http://aosabook.org/en/posa/high-performance-networking-in-chrome.html
。
接着是输入 URL 后的「回车」,这时浏览器会对 URL 进行检查,首先判断协议,如果是 http 就按照 Web 来处理,另外还会对这个 URL 进行安全检查,然后直接调用浏览器内核中的对应方法,比如
WebView
中的 loadUrl 方法。
在浏览器内核中会先查看缓存,然后设置 UA 等 HTTP 信息,接着调用不同平台下网络请求的方法。
需要注意浏览器和浏览器内核是不同的概念,浏览器指的是 Chrome、Firefox,而浏览器内核则是 Blink、Gecko,浏览器内核只负责渲染,GUI 及网络连接等跨平台工作则是浏览器实现的
HTTP 请求的发送
因为网络的底层实现是和内核相关的,所以这一部分需要针对不同平台进行处理,从应用层角度看主要做两件事情:通过 DNS 查询 IP、通过 Socket 发送数据,接下来就分别介绍这两方面的内容。
DNS 查询
应用程序可以直接调用 Libc 提供的
getaddrinfo()
方法来实现 DNS 查询。
DNS 查询其实是基于 UDP 来实现的,这里我们通过一个具体例子来了解它的查找过程,以下是使用
dig +trace fex.baidu.com
命令得到的结果(省略了一些):
; > DiG 9.8.3-P1 > +trace fex.baidu.com
;; global options: +cmd
. 11157 IN NS g.root-servers.net.
. 11157 IN NS i.root-servers.net.
. 11157 IN NS j.root-servers.net.
. 11157 IN NS a.root-servers.net.
. 11157 IN NS l.root-servers.net.
;; Received 228 bytes from 8.8.8.8#53(8.8.8.8) in 220 ms
com. 172800 IN NS a.gtld-servers.net.
com. 172800 IN NS c.gtld-servers.net.
com. 172800 IN NS m.gtld-servers.net.
com. 172800 IN NS h.gtld-servers.net.
com. 172800 IN NS e.gtld-servers.net.
;; Received 503 bytes from 192.36.148.17#53(192.36.148.17) in 185 ms
baidu.com. 172800 IN NS dns.baidu.com.
baidu.com. 172800 IN NS ns2.baidu.com.
baidu.com. 172800 IN NS ns3.baidu.com.
baidu.com. 172800 IN NS ns4.baidu.com.
baidu.com. 172800 IN NS ns7.baidu.com.
;; Received 201 bytes from 192.48.79.30#53(192.48.79.30) in 1237 ms
fex.baidu.com. 7200 IN CNAME fexteam.duapp.com.
fexteam.duapp.com. 300 IN CNAME duapp.n.shifen.com.
n.shifen.com. 86400 IN NS ns1.n.shifen.com.
n.shifen.com. 86400 IN NS ns4.n.shifen.com.
n.shifen.com. 86400 IN NS ns2.n.shifen.com.
n.shifen.com. 86400 IN NS ns5.n.shifen.com.
n.shifen.com. 86400 IN NS ns3.n.shifen.com.
;; Received 258 bytes from 61.135.165.235#53(61.135.165.235) in 2 ms
可以看到这是一个逐步缩小范围的查找过程,首先由本机所设置的 DNS 服务器(8.8.8.8)向 DNS 根节点查询负责 .com 区域的域务器,然后通过其中一个负责 .com 的服务器查询负责 baidu.com 的服务器,最后由其中一个 baidu.com 的域名服务器查询 fex.baidu.com 域名的地址。
可能你在查询某些域名的时会发现和上面不一样,最底将看到有个奇怪的服务器抢先返回结果。。。
这里为了方便描述,忽略了很多不同的情况,比如 127.0.0.1 其实走的是
loopback
,和网卡设备没关系;比如 Chrome 会在浏览器启动的时预先查询 10 个你有可能访问的域名;还有 Hosts 文件、缓存时间 TTL(Time to live)的影响等。
通过 Socket 发送数据
有了 IP 地址,就可以通过 Socket API 来发送数据了,这时可以选择 TCP 或 UDP 协议,具体使用方法这里就不介绍了,推荐阅读
Beej’s Guide to Network Programming
。
HTTP 常用的是 TCP 协议,由于 TCP 协议的具体细节到处都能看到,所以本文就不介绍了,这里谈一下 TCP 的 Head-of-line blocking 问题:假设客户端的发送了 3 个 TCP 片段(segments),编号分别是 1、2、3,如果编号为 1 的包传输时丢了,即便编号 2 和 3 已经到达也只能等待,因为 TCP 协议需要保证顺序,这个问题在 HTTP pipelining 下更严重,因为 HTTP pipelining 可以让多个 HTTP 请求通过一个 TCP 发送,比如发送两张图片,可能第二张图片的数据已经全收到了,但还得等第一张图片的数据传到。
为了解决 TCP 协议的性能问题,Chrome 团队去年提出了
QUIC
协议,它是基于 UDP 实现的可靠传输,比起 TCP,它能减少很多来回(round trip)时间,还有前向纠错码(Forward Error Correction)等功能。目前 Google Plus、 Gmail、Google Search、blogspot、Youtube 等几乎大部分 Google 产品都在使用 QUIC,可以通过
chrome://net-internals/#spdy
页面来发现。
虽然目前除了 Google 还没人用 QUIC,但我觉得挺有前景的,因为优化 TCP 需要升级系统内核(比如
Fast Open
)。
浏览器对同一个域名有连接数限制,
大部分是 6
,我以前认为将这个连接数改大后会提升性能,但实际上并不是这样的,Chrome 团队有做过实验,发现从 6 改成 10 后性能反而下降了,造成这个现象的因素有很多,如建立连接的开销、拥塞控制等问题,而像 SPDY、HTTP 2.0 协议尽管只使用一个 TCP 连接来传输数据,但性能反而更好,而且还能实现请求优先级。
另外,因为 HTTP 请求是纯文本格式的,所以在 TCP 的数据段中可以直接分析 HTTP 的文本,如果发现。。。
Socket 在内核中的实现
前面说到浏览器的跨平台库通过调用 Socket API 来发送数据,那么 Socket API 是如何实现的呢?
以 Linux 为例,它的实现在这里
socket.c
http://lxr.linux.no/linux+v3.14.4/net/socket.c
,目前我还不太了解,推荐读者看看
Linux kernel map
http://www.makelinux.net/kernel_map/
,它标注出了关键路径的函数,方便学习从协议栈到网卡驱动的实现。
底层网络协议的具体例子
接下来如果继续介绍 IP 协议和 MAC 协议可能很多读者会晕,所以本节将使用
Wireshark
来通过具体例子讲解,以下是我请求百度首页时抓取到的网络数据:
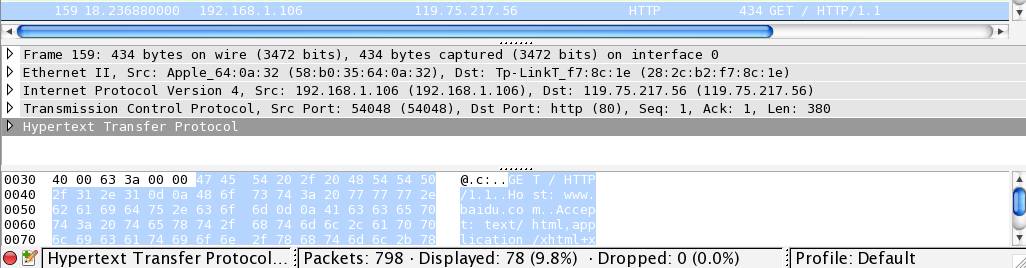
最底下是实际的二进制数据,中间是解析出来的各个字段值,可以看到其中最底部为 HTTP 协议(Hypertext Transfer Protocol),在 HTTP 之前有 54 字节(0x36),这就是底层网络协议所带来的开销,我们接下来对这些协议进行分析。
在 HTTP 之上是 TCP 协议(Transmission Control Protocol),它的具体内容如下图所示:

通过底部的二进制数据,可以看到 TCP 协议是加在 HTTP 文本前面的,它有 20 个字节,其中定义了本地端口(Source port)和目标端口(Destination port)、顺序序号(Sequence Number)、窗口长度等信息,以下是 TCP 协议各个部分数据的完整介绍:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|E|R|S|F| |
| Offset| Reserved |R|C|O|S|Y|I| Window |
| | |G|K|L|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
具体各个字段的作用这里就不介绍了,感兴趣的读者可以阅读
RFC 793
,并结合抓包分析来理解。
需要注意的是,在 TCP 协议中并没有 IP 地址信息,因为这是在上一层的 IP 协议中定义的,如下图所示:
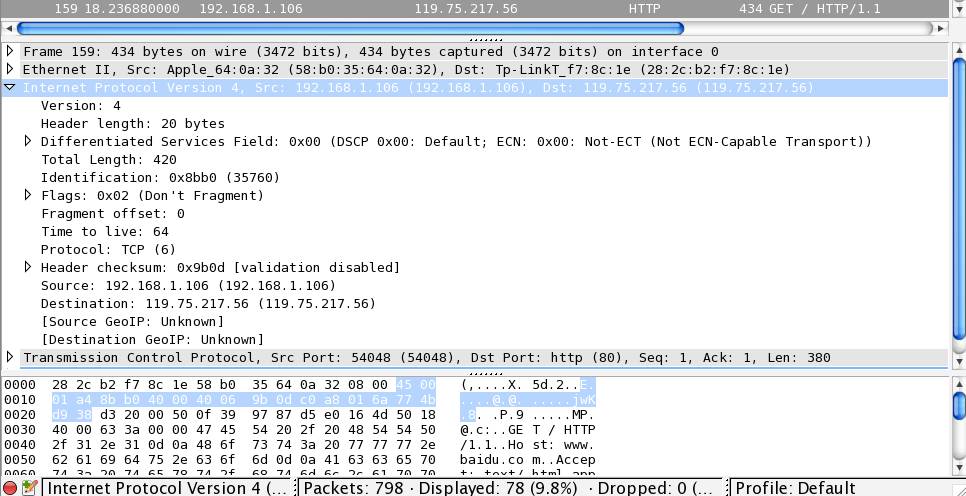
IP 协议同样是在 TCP 前面的,它也有 20 字节,在这里指明了版本号(Version)为 4,源(Source) IP 为
192.168.1.106
,目标(Destination) IP 为
119.75.217.56
,因此 IP 协议最重要的作用就是确定 IP 地址。
因为 IP 协议中可以查看到目标 IP 地址,所以如果发现某些特定的 IP 地址,某些路由器就会。。。
但是,光靠 IP 地址是无法进行通信的,因为 IP 地址并不和某台设备绑定,比如你的笔记本的 IP 在家中是
192.168.1.1
,但到公司就变成
172.22.22.22
了,所以在底层通信时需要使用一个固定的地址,这就是 MAC(media access control) 地址,每个网卡出厂时的 MAC 地址都是固定且唯一的。
因此再往上就是 MAC 协议,它有 14 字节,如下所示:

当一台电脑加入网络时,需要通过
ARP
协议告诉其它网络设备它的 IP 及对应的 MAC 地址是什么,这样其它设备就能通过 IP 地址来查找对应的设备了。
最顶上的 Frame 是代表 Wireshark 的抓包序号,并不是网络协议
就这样,我们解答了第二个问题,不过其实这里面还有很多很多细节没介绍,建议大家通过下面的书籍进一步学习。
扩展学习
第三个问题:数据如何从本机网卡发送到服务器?
从内核到网络适配器(Network Interface Card)
前面说到调用 Socket API 后内核会对数据进行底层协议栈的封装,接下来启动
DMA
控制器,它将从内存中读取数据写入网卡。
以 Nexus 5 为例,它使用的是博通
BCM4339
芯片通信,接口采用了 SD 卡一样的
SDIO
,但这个芯片的细节并没有公开资料,所以这里就不讨论了。
连接 Wi-Fi 路由
Wi-Fi 网卡需要通过 Wi-Fi 路由来与外部通信,原理是基于无线电,通过电流变化来产生无线电,这个过程也叫「调制」,而反过来无线电可以引起电磁场变化,从而产生电流变化,利用这个原理就能将无线电中的信息解读出来就叫「解调」,其中单位时间内变化的次数就称为频率,目前在 Wi-Fi 中所采用的频率分为 2.4 GHz 和 5 GHz 两种。
在同一个 Wi-Fi 路由下,因为采用的频率相同,同时使用时会发生冲突,为了解决这个问题,Wi-Fi 采用了被称为
CSMA/CA
的方法,简单来说就是在传输前先确认信道是否已被使用,没有才发送数据。
而同样基于无线电原理的 2G/3G/LTE 也会遇到类似的问题,但它并没有采用 Wi-Fi 那样的独占方案,而是通过频分(FDMA)、时分(TDMA)和码分(CDMA)来进行复用,具体细节这里就不展开了。
以小米路由为例,它使用的芯片是
BCM 4709
,这个芯片由 ARM Cortex-A9 处理器及流量(Flow)硬件加速组成,使用硬件芯片可以避免经过操作系统中断、上下文切换等操作,从而提升了性能。
路由器中的操作系统可以基于
OpenWrt
或
DD-WRT
来开发的,具体细节我不太了解,所以就不展开了。
因为内网设备的 IP 都是类似
192.168.1.x
这样的内网地址,外网无法直接向这个地址发送数据,所以网络数据在经过路由时,路由会修改相关地址和端口,这个操作称为
NAT
映射。
最后家庭路由一般会通过
双绞线
连接到运营商网络的。
运营商网络内的路由
数据过双绞线发送到运营商网络后,还会经过很多个中间路由转发,读者可以通过 traceroute 命令或者
在线可视化工具
来查看这些路由的 ip 和位置。
当数据传递到这些路由器后,路由器会取出包中目的地址的前缀,通过内部的转发表查找对应的输出链路,而这个转发表是如何得到的呢?这就是路由器中最重要的选路算法了,可选的有很多,我对这方面并不太了解,看起来
维基百科
上的词条列得很全。
主干网间的传输
对于长线的数据传输,通常使用光纤作为介质,光纤是基于光的全反射来实现的,使用光纤需要专门的发射器通过
电致发光
(比如 LED)将电信号转成光,比起前面介绍的无线电和双绞线,光纤信号的抗干扰性要强得多,而且能耗也小很多。
既然是基于光来传输数据,数据传输速度也就取决于光的速度,在真空中的光速接近于 30 万千米/秒,由于光纤包层(cladding)中的折射率(refractive index)为 1.52,所以实际光速是 20 万千米/秒左右,从首都机场飞往广州白云机场的距离是 1967 千米,按照这个距离来算需要花费 10 毫秒才能抵达。这意味着如果你在北京,服务器在广州,等你发出数据到服务器返回数据至少得等 20 毫秒,实际情况预计是 2- 3 倍,因为这其中还有各个节点路由处理的耗时,比如我测试了一个广州的 IP 发现平均延迟为 60 毫秒。
这个延迟是现有科技无法解决的(除非找到超过光速的方法),只能通过 CDN 来让传输距离变短,或尽量减少串行的来回请求(比如 TCP 建立连接所需的 3 次握手)。
IDC 内网
数据通过光纤最终会来到服务器所在的 IDC 机房,进入 IDC 内网,这时可以先通过
分光器
将流量镜像一份出来方便进行安全检查等分析,还能用来进行。。。
这里的带宽成本很高,是按照峰值来结算的,以每月每 Gbps(注意这里指的是 bit,而不是 Byte)为单位,北京这边价格在十万人民币以上,一般网站使用 1G 到 10G 不等。
接下来光纤中的数据将进入集群(Cluster)交换机,然后再转发到机架(Rack)顶部的交换机,最后通过这个交换机的端口将数据发往机架中的服务器,可以参考下图(来自 Open Compute):

上图左边是正面,右边是侧面,可以看到顶部为交换机所留的位置。
以前这些交换机的内部实现是封闭的,相关厂商(如思科、Juniper 等)会使用特定的处理器和操作系统,外界难以进行灵活控制,甚至有时候需要手工配置,但这几年随着
OpenFlow
技术的流行,也出现了开放交换机硬件(Open Switch Hardware),比如 Intel 的
网络平台
,推荐感兴趣的读者建议看看
它的视频
,比文字描述清晰多了。
需要注意的是,一般网络书中提到的交换机都只具备二层(MAC 协议)的功能,但在 IDC 中的交换器基本上都具备三层(IP 协议)的功能,所以不需要有专门的路由了。
最后,因为 CPU 处理的是电气信号,所以光纤中的光线需要先使用相关设备通过
光电效应
将光信号转成电信号,然后进入服务器网卡。
服务器 CPU
前面说到数据已经到达服务器网卡了,接着网卡会将数据拷贝到内存中(DMA),然后通过中断来通知 CPU,目前服务器端的 CPU 基本上都是
Intel Xeon
,不过这几年出现了一些新的架构,比如在存储领域,百度使用
ARM
架构来提升存储密度,因为 ARM 的功耗比 Xeon 低得多。而在高性能领域,Google 最近在尝试基于
POWER
架构的 CPU 来开发的服务器,最新的 POWER8 处理器可以并行执行 96 个线程,所以对高并发的应用应该很有帮助。
扩展学习
第四个问题:服务器接收到数据后会进行哪些处理?
为了避免重复,这里将不再介绍操作系统,而是直接进入后端服务进程,由于这方面有太多技术选型,所以我只挑几个常见的公共部分来介绍。
负载均衡
请求在进入到真正的应用服务器前,可能还会先经过负责负载均衡的机器,它的作用是将请求合理地分配到多个服务器上,同时具备具备防攻击等功能。
负载均衡具体实现有很多种,有直接基于硬件的 F5,有操作系统传输层(TCP)上的
LVS
,也有在应用层(HTTP)实现的反向代理(也叫七层代理),接下来将介绍 LVS 及反向代理。
负载均衡的策略也有很多,如果后面的多个服务器性能均衡,最简单的方法就是挨个循环一遍(Round-Robin),其它策略就不一一介绍了,可以参考 LVS 中的
算法
。
LVS
LVS 的作用是从对外看来只有一个 IP,而实际上这个 IP 后面对应是多台机器,因此也被成为 Virtual IP。
前面提到的 NAT 也是一种 LVS 中的工作模式,除此之外还有 DR 和 TUNNEL,具体细节这里就不展开了,它们的缺点是无法跨网段,所以百度自己开发了 BVS 系统。
反向代理
反向代理是工作在 HTTP 上的,具体实现可以基于 HAProxy 或 Nginx,因为反向代理能理解 HTTP 协议,所以能做非常多的事情,比如:
-
进行很多统一处理,比如防攻击策略、防抓取、SSL、gzip、自动性能优化等
-
应用层的分流策略都能在这里做,比如对 /xx 路径的请求分到 a 服务器,对 /yy 路径的请求分到 b 服务器,或者按照 cookie 进行小流量测试等
-
缓存,并在后端服务挂掉的时候显示友好的 404 页面
-
监控后端服务是否异常
-
⋯⋯
Nginx 的代码写得非常优秀,从中能学到很多,对高性能服务端开发感兴趣的读者一定要看看。
Web Server 中的处理
请求经过前面的负载均衡后,将进入到对应服务器上的 Web Server,比如 Apache、Tomcat、Node.JS 等。
以 Apache 为例,在接收到请求后会交给一个独立的进程来处理,我们可以通过编写 Apache 扩展来处理,但这样开发起来太麻烦了,所以一般会调用 PHP 等脚本语言来进行处理,比如在 CGI 下就是将 HTTP 中的参数放到环境变量中,然后启动 PHP 进程来执行,或者使用 FastCGI 来预先启动进程。
(等后续有空再单独介绍 Node.JS 中的处理)
进入后端语言
前面说到 Web Server 会调用后端语言进程来处理 HTTP 请求(这个说法不完全正确,有很多其它可能),那么接下来就是后端语言的处理了,目前大部分后端语言都是基于虚拟机的,如 PHP、Java、JavaScript、Python 等,但这个领域的话题非常大,难以讲清楚,对 PHP 感兴趣的读者可以阅读我之前写的
HHVM 介绍文章
,其中提到了很多虚拟机的基础知识。
Web 框架(Framework)
如果你的 PHP 只是用来做简单的个人主页「Personal Home Page」,倒没必要使用 Web 框架,但如果随着代码的增加会变得越来越难以管理,所以一般网站都会会基于某个 Web 框架来开发,因此在后端语言执行时首先进入 Web 框架的代码,然后由框架再去调用应用的实现代码。
可选的
Web 框架非常多
,这里就不一一介绍了。
读取数据
这部分不展开了,从简单的读写文件到数据中间层,这里面可选的方案实在太多。
扩展学习
第五个问题:服务器返回数据后浏览器如何处理?
前面说到服务端处理完请求后,结果将通过网络发回客户端的浏览器,从本节开始将介绍浏览器接收到数据后的处理,值得一提的是这方面之前有一篇不错的文章
How Browsers Work
,所以很多内容我不想再重复介绍,因此将重点放在那篇文章所忽略的部分。
从 01 到字符
HTTP 请求返回的 HTML 传递到浏览器后,如果有 gzip 会先解压,然后接下来最重要的问题是要知道它的编码是什么,比如同样一个「中」字,在 UTF-8 编码下它的内容其实是「11100100 10111000 10101101」也就是「E4 B8 AD」,而在 GBK 下则是「11010110 11010000」,也就是「D6 D0」,如何才能知道文件的编码?可以有很多判断方法:
-
用户设置,在浏览器中可以指定页面编码
-
HTTP 协议中
-
中的 charset 属性值
-
对于 JS 和 CSS
-
对于 iframe
如果在这些地方都没指明,浏览器就很难处理,在它看来就是一堆「0」和「1」,比如「中文」,它在 UTF-8 下有 6 个字节,如果按照 GBK 可以当成「涓枃」这 3 个汉字来解释,浏览器怎么知道到底是「中文」还是「涓枃」呢?
不过正常人一眼就能认出「涓枃」是错的,因为这 3 个字太不常见了,所以有人就想到通过判断常见字的方法来检测编码,典型的比如 Mozilla 的
UniversalCharsetDetection
,不过这东东误判率也很高,所以还是指明编码的好。
这样后续对文本的操作就是基于「字符」(Character)的了,一个汉字就是一个字符,不用再关心它究竟是 2 个字节还是 3 个字节。
外链资源的加载
(待补充,这里有调度策略)
JavaScript 的执行
(后续再单独介绍,推荐大家看 R 大去年整理的
这个帖子
,里面有非常多相关资料,另外我两年前曾讲过
JavaScript 引擎中的性能优化
,虽然有些内容不太正确了,但也可以看看)
从字符到图片
二维渲染中最复杂的要数文字显示了,虽然想想似乎很简单,不就是将某个文字对应的字形(glyph)找出来么?在中文和英文中这样做是没问题的,因为一个字符就对应一个字形(glyph),在字体文件中找到字形,然后画上去就可以了,但在阿拉伯语中是不行的,因为它有有连体形式。
(以后续再单独介绍,这里非常复杂)
跨平台 2D 绘制库
在不同操作系统中都提供了自己的图形绘制 API,比如 Mac OS X 下的 Quartz,Windows 下的 GDI 以及 Linux 下的 Xlib,但它们相互不兼容,所以为了方便支持跨平台绘图,在 Chrome 中使用了
Skia
库。
(以后再单独介绍,Skia 内部实现调用层级太多,直接讲代码可能不适合初学者)
GPU 合成
(以后续再单独介绍,虽然简单来说就是靠贴图,但还得介绍 OpenGL 以及 GPU 芯片,内容太长)
扩展学习
这节内容是我最熟悉,结果反而因为这样才想花更多时间写好,所以等到以后再发出来好了,大家先可以先看看以下几个站点:
第六个问题:浏览器如何将页面展现出来?
前面提到浏览器已经将页面渲染成一张图片了,接下来的问题就是如何将这张图片展示在屏幕上。
Framebuffer
以 Linux 为例,在应用中控制屏幕最直接的方法是将图像的 bitmap 写入
/dev/fb0
文件中,这个文件实际上一个内存区域的映射,这段内存区域称为 Framebuffer。
需要注意的是在硬件加速下,如 OpenGL 是不经过 Framebuffer 的。
从内存到 LCD
在手机的 SoC 中通常都会有一个 LCD 控制器,当 Framebuffer 准备好后,CPU 会通过
AMBA
内部总线通知 LCD 控制器,然后这个控制器读取 Framebuffer 中的数据,进行格式转换、伽马校正等操作,最终通过
DSI
、HDMI 等接口发往 LCD 显示器。
以
OMAP5432
为例,下图是它所支持的一种并行数据传输:
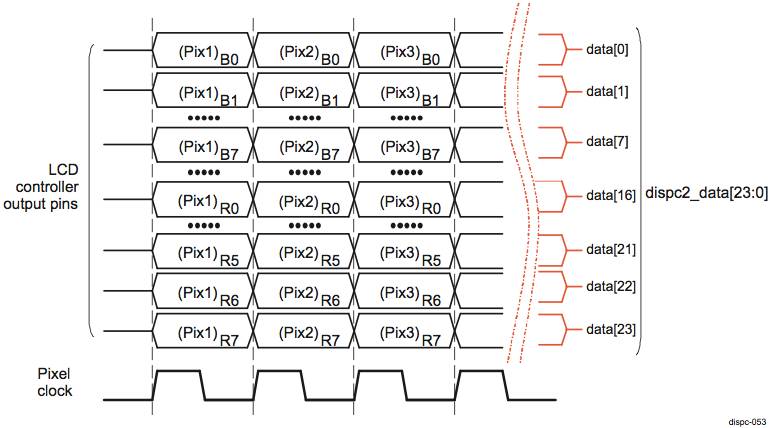
LCD 显示
最后简单介绍一下 LCD 的显示原理。
首先,要想让人眼能看见,就必须有光线进入,要么通过反射、要么有光源,比如 Kindle 所使用的 E-ink 屏幕本身是不发光的,所以必须在有光线的地方才能阅读,它的优点是省电,但限制太大,所以几乎所有 LCD 都会自带光源。
目前 LCD 中通常使用
LED
作为光源,LED 接上电源后,在电压的作用下,内部的正负电子结合会释放光子,从而产生光,这种物理现象叫电致发光(Electroluminescence),这在前面介绍光纤时也介绍过。
以下是 iPod Touch 2 拆开后的样子:(来自
Wikipedia
):

在上图中可以看到 6 盏 LED,这就是整个屏幕的光源,这些光源将通过反射的反射输出到屏幕中。
有了光源还得有色彩,在 LED 中通常做法是使用彩色滤光片(Color filter)来将 LED 光源转成不同颜色。
另外直接使用三种颜色的 LED 也是可行的,它能避免了滤光导致的光子浪费,降低耗电,很适用于智能手表这样的小屏幕,Apple 收购的 LuxVue 公司就采用的是这种方式,感兴趣的话可以去研究它的
专利










