
ECCV 2024: RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images
代码链接:
https://github.com/cuiziteng/ECCV_RAW_Adapter
文章链接:
https://arxiv.org/abs/2408.14802
1. 前言
目前已有的工作中,探索RAW-to-RGB的ISP,不管是传统ISP还是DL-based的ISP,都已经取得了不错的效果和泛化性能,也是各大手机厂商竞争的火热卖点,但是基于RAW图像的high-level vision tasks还探索寥寥,RAW图像优势在其尚未经过ISP的丰富的光照储存信息(higher bit depth),更广的色域范围(wider gamut range),规律的noise distribution(成像每一个阶段的噪声都有可解释性),让RAW在低光照场景和过曝光等不良光照场景存在着很大的优势。然而针对high-level vision tasks (如目标检测,语义分割的任务)其一大劣势在于目前并没有针对RAW的大规模数据集和pre-train models,因此如何更好的把RAW图像和sRGB pretrain权重结合成了一个有待探索的topic,本文针对这个motivation给出了初步探索,后续提升还需大家一起多多努力~
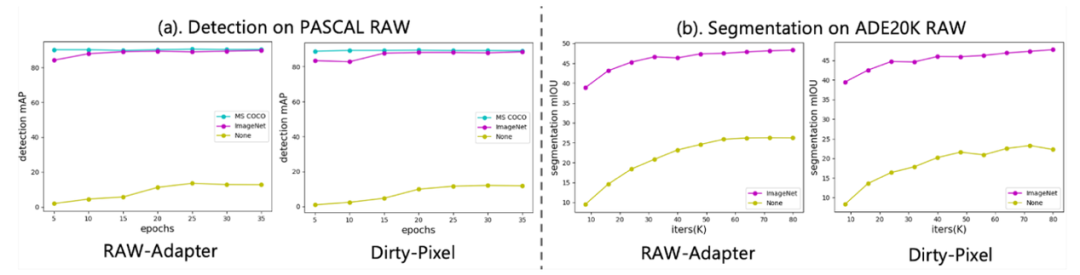
基于RAW图像的视觉任务,黄线是没有利用sRGB预训练权重,紫色和蓝色的线是利用sRGB预训练权重,可以看出sRGB预训练权重在基于RAW的视觉task中有着很重要的作用
2. 相关工作
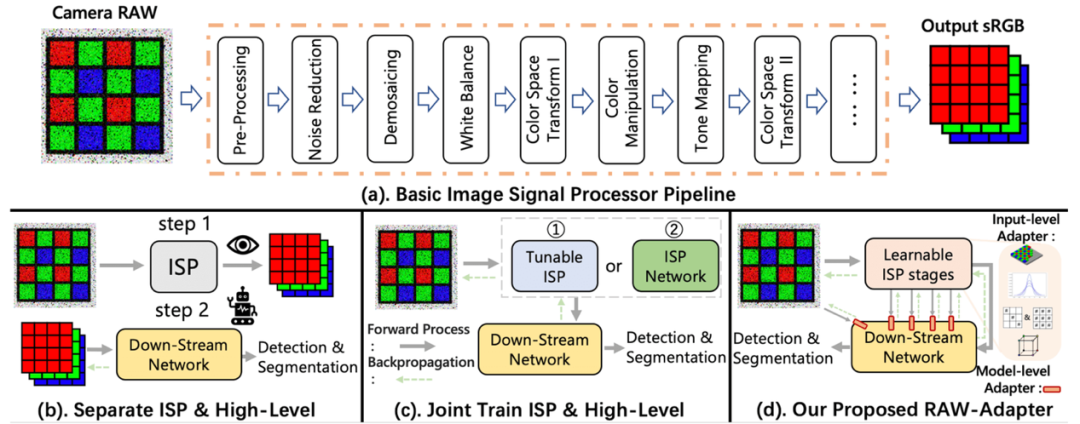 (a).ISP基本结构 (b). ISP与high-level分离 (c).串联链接RAW与ISP训练 (d). RAW-Adapter
(a).ISP基本结构 (b). ISP与high-level分离 (c).串联链接RAW与ISP训练 (d). RAW-Adapter
ISP是相机内部很复杂专业的流程,对这方面感兴趣的同学,建议阅读Micheal s Brown发在ECCV 2016的那篇经典之作 (ps. 这篇论文对小白收获价值很大,堪称入门必读,本人也是读了好几遍,而且基本每次写paper都会引用这篇工作,Brown教授也是我在这个领域非常喜欢与欣赏的一位学者),或者他在ICCV 2023上的tutorial,了解一下相机ISP的相关步骤和背景知识(Demosacing, Denosing, WB, CCM, gamma ...)。ISP本身的设计和design是为了满足人眼视觉更好的感知,传统的ISP算法每一个step往往都需要prior knowledge,比如白平衡前需要估计光源。每一家厂商的ISP也都有自己的特点,比如Sony和华为他们的自家ISP流程的CCM以及LUT参数肯定不同,同时每家的ISP基本都是黑盒,我们很难获取里面具体的step。ISP针对人眼设计的特性也导致了,这些ISP算法并不一定能很好的满足machine vision,尤其是在对于一些下游计算机视觉任务检测,分割的时候,针对人眼设计的ISP并不一定能够符合mAP,IOU等指标,这一表现在低光场景尤为明显。
这也就派生了一系列的工作,machine vision oriented ISP,设计ISP模型来更好的满足机器视觉性能,如检测分割等task,这一系列工作在普林斯顿的Felix Heide那边探索的比较多,他们的工作旨在于把一些ISP参数变得可以学习(Hardware-in the loop),或者通过一个UNet类型的网络(Dirty Pixel),还有一些其他组的工作比如通过NAS来选择合适的ISP参数,或者设计更新的网络来当成encoder,在这里就不一一论述了,感兴趣的可以看一下我们paper的related works部分。这里特别一提的是,利用网络搭建一个pre-encoder的工作,会大大加重网络负担,尤其在高分辨率输入场景尤为明显。
然而,此前的工作都缺乏对于sRGB pretain权重和RAW视觉任务的关系,在sRGB pretain权重愈发重要的今天,我们没有足够量的RAW data来做大规模预训练,因此如何利用好sRGB Pre-train权重的优势来设计轻量Adapters给RAW图像,成为了研究的关键。
3. 模型结构
我们的方法设计了两组Adapters,一组是用来把RAW图像处理到网络输入阶段的Input-level Adapter, 另一组是链接ISP阶段特征和后续网络的Model-level Adapter,更多细节请见原文。
整体的模型结构中,Input-level Adapter这里大致包括四个步骤: (1). 预处理 + denoise/ gain/ sharpen (2). 白平衡 (3). CCM矩阵以及(4) Implicit 3D LUT。每一个步骤的初心目的就是把ISP参数变成可学习的,动态参与到模型的反向传播过程,同时让这些ISP参数可以自适应的配合到不同图像&光照&数据集。
Model-level Adapter这里则是更多借鉴了ViT-Adapter的设计,希望能把ISP阶段的中间特征作为Guidance融合的后续的网络backbone中。
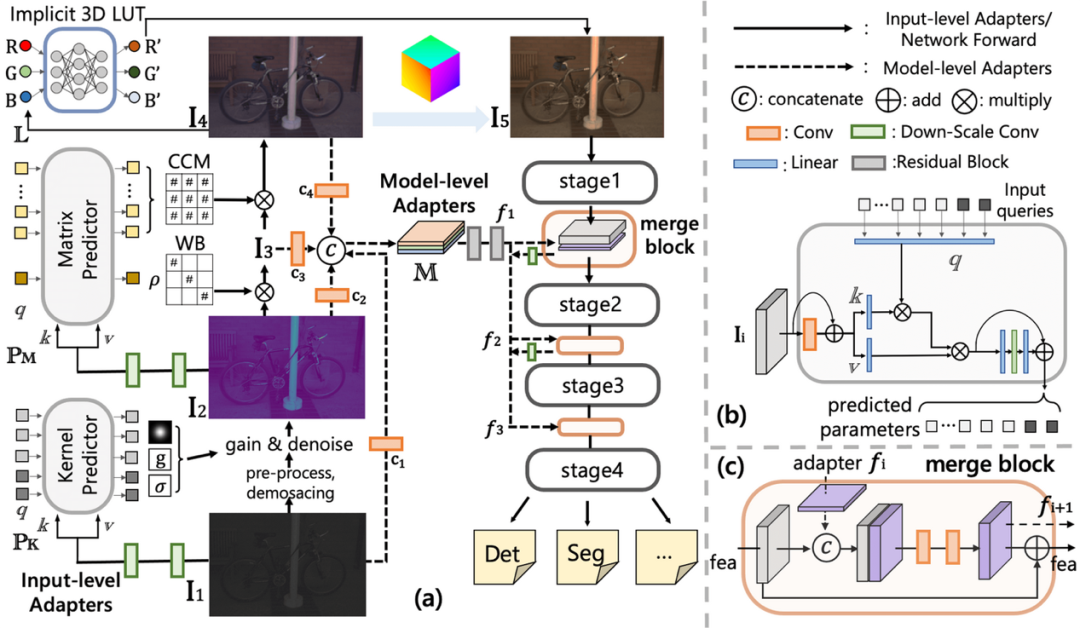 RAW-Adapter模型结构
RAW-Adapter模型结构
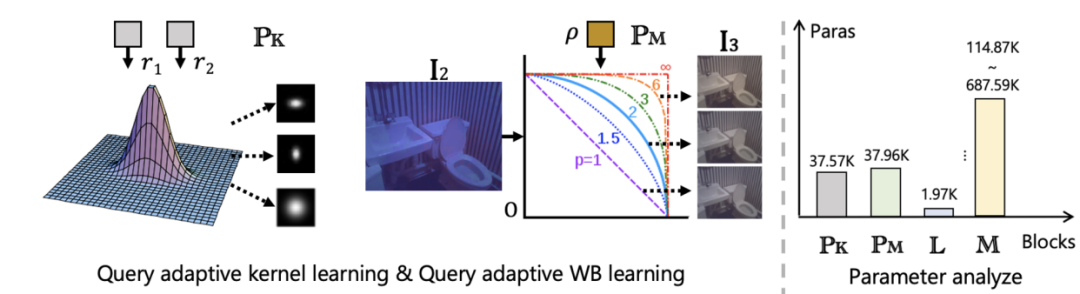 可以动态学习的Denoise Kernel以及白平衡参数
可以动态学习的Denoise Kernel以及白平衡参数
其中 Input-level Adapter的设计中,我们采用了利用Attention模块的方式来直接估计ISP参数,比如去噪模糊核,白平衡Parameters以及相机CCM矩阵,这部分是直接用我之前[BMVC 2022 IAT] 的attention动态学习参数来设计的 (ps, 终于让IAT这篇ECCV 2022的拒稿,登上了ECCV 2024的舞台),动态学习ISP参数的优势,在于可以更具具体的图像,具体的光照场景,来更好的自适应调节参数。更多的模型细节可以参考我们原文。
4. 实验设置
实验在检测分割任务中做了测试,包括检测的PASCAL RAW数据集,LOD数据集,分割的合成数据集ADE20K-RAW以及真实数据集iPhone XSmax。证明了我们方法相比于ISP算法和此前joint-training方法的有效性。其中我们在PASCAL RAW/ ADE20K-RAW上额外合成了低光照和过曝光的场景情况,发现RAW在异常光照下存在着独到优势,更多细节结论请见原文。

我们把PASCAL RAW数据集生成了三种光照情况,来更好的研究RAW图像对光照泛化性的优势
 ADE20K-RAW表现
ADE20K-RAW表现
 LOD以及PASCAL RAW表现
LOD以及PASCAL RAW表现
5. 未来方向
我个人对RAW-Adapter的定义还是一个初步的起步工作,相比已经卷成一片红海的RGB,未来基于RAW图像的high-level视觉任务还有很大的空间可以做,也是一个广大硕博们能发论文的宝藏方向。希望RAW-Adapter能够成为这个方向大家的垫脚石,让广大研究者在这个方向一步步探索走下去,在未来的direction上,一些个人见解是此前基于RGB的探索都可以结合RAW试一下,比如自监督,预训练,DA ...... 当然RAW-Adapter本身也存在着一定缺陷,比如kernel-based densoing过于简单,在一些复杂噪声情况也许无效,比如impilcit 3D LUT并不是image-adaptive的,这部分改成image-adaptive也许会更好,还有model-level adapter肯定还有更好的特征融合方式,每个部分探索空间都很大,希望与大家共勉,一起进步。

公众号后台回复“
数据集
”获取100+深度学习各方向资源整理










