
做运维也快4年多了,就像游戏打怪升级,升级后知识体系和运维体系也相对变化挺大,学习了很多新的知识点。
运维工程师 是从一个呆逼进化为苦逼再成长为牛逼的过程,前提在于你要能忍能干能拼,还要具有敏锐的嗅觉感知前方潮流变化。如:今年大数据,人工智能比较火。。。(相对表示就是 python 比较火)
前面也讲了运维基础篇,发现对很多人收益挺大,接下来也写下关于这4年多的运维实践经验,从事了2年多游戏运维,1年多安全运维,1年大数据运维,相关行业信息不能算非常精通吗,但是熟悉和熟练还是相对可以的。
详见: 详解Linux运维工程师入门级必备技能
拓扑详见:

从我后面面试经历和面试别人的经历。有些人认为,其实运维就是部署某个软件,设置些基础功能,就算会运维了。
举个例子:安装LAMP,LNMP,就感觉部署方法我都掌握了。其实网上大多数都有一键安装脚本啥的根本没有啥技术含量,在面试官眼里,这些都不是你的亮点。基本到了公司一般环境架构都是部署好的,很少需要你去变动环境架构。就算你安装好 LNMP 架构你熟悉里面的原理吗,熟悉 Nginx 优化吗,熟悉 MySQL 优化吗?
再举个例子:我面试遇到的问题,面试官问你既然熟悉 LNMP 架构,那么 Nginx 反向代理的作用。
你应该不是说出懂这个软件和配置,你尽可能的说怎么优化,怎么深入提高网站性能。
1、使用反向代理可以理解为7层应用层的负载均衡,使用负载均衡之后可以非常便捷的横向扩展服务器集群,实现集群整体并发能力、抗压能力的提高。
2、通常反向代理服务器会带有本地 Cache 功能,通过静态资源的 Cache,有效的减少后端服务器所承载的压力,从而提高性能。
下面说说运维在工作中需要掌握的核心技术
注意,这是在工作中掌握的,在学习中很难掌握。
查看剩余内存:

系统信息:

硬件信息:

日志管理常用命令:

优化可以说是运维最吃香的技能,基本会优化的运维普遍工资很高,而且优化是要承担风险的,并不是网上搜个文章改一下配置文件或者参数就叫优化了,这样很容易造成宕机。
优化是根据实际的现场环境硬件各个参数进行部分优化,提高软件性能和网站性能。这个我只能讲半知半解,当时优化mysql和tomcat参数也是根据网上文章和官网文档查找参数在虚拟机上测试然后查看性能。
成本优化,性能优化。这里我给出 tomcat 优化 jvm 参数(做过相应测试才放到现场环境的):(记住无监控不调优)
-标准参数,所有jvm都应该支持
-X 非标,每个jvm实现都不同
-XX 不稳定参数,下一版本可能会取消
serial collector 单线程 序列化
parallel collector 多线程
启动 jvisualvm.exe 监控 dump 内存溢出
-Xms:初始堆大小
-Xmx:最大堆大小
-Xss:线程栈大小
-XX:NewSize=n:设置年轻代大小
-XX:NewRatio=n:设置年轻代和年老代的比值,如3, 标示年轻代:年老代比值1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中的eden区与2个Survivor区的比值。
-XX:MaxPermSize=n:设置持久代大小
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-Xloggc:filename
tocmat 优化 确认有几个 jvm 虚拟机
set JAVA_OPTS=
-Xms4g
-Xmx4g
-Xss512k
-XX:+AggressiveOpts 进攻型的优化选项,所有优化项都加上
-XX:+UseBiasedLocking 优化锁,基本都要选上,偏执锁
-XX:permSize=64m 原始区大小,最大300m 类多就设置大一点
-XX:MaxPermSize=300m
-XX:+DisableExplicitGC //System.gc() 不显示调用gc
-XX:+UseConcMarkSweepGC 使用cms缩短相应时间,并发收集,低停顿
-XX:+UseParNewGC 并行收集新生代的垃圾
-XX:+CMSParallelRemarkEnabled 在使用UseParNewGC的情况下,尽量减少mark的时间
-XX:+UseCMSCompactAtFullCollection 使用并发收集器时,开启对年老代的压缩,使碎片减少
-XX:LargePageSizelnBytes=128m 内存分页大小对性能的提升
-XX:+UseFastAccessorMethods get/set方法转成本地代码
-Djava awt headless=true 修复linux下tomcat处理图标时可能产生的bug
内存调优:
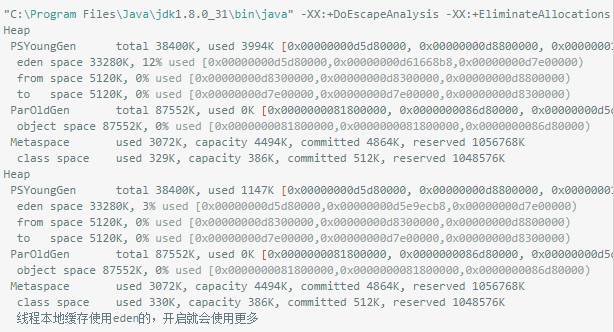
tomcat 前任何参数没参加大概每秒605 调优后大概每秒435 接近3倍的结果
优选 shell 和 python,现在 shell 无法满足你的需求或者效率很低,那么选择自动化 python 是最好的选择。现在普遍招聘需求要求,会写 shell 或者 python,perl 脚本,个人选择还是选 python。
python 这门语言上手比较快,容易理解。
python 在服务器管理工具上非常丰富,配置管理(saltstack) 批量执行( fabric, saltstack) 监控(Zenoss, nagios 插件) 虚拟化管理( python-libvirt) 进程管理 (supervisor) 云计算(openstack) ...... 还有大部分系统 C 库都有 python 绑定。
对于流程确定的事情,最终一定是纳入系统管理的体系,写成程序,成为系统的一部分。而不是无法复用游离与整体的各种脚本。
随着云计算时代的来临,中小型公司,不需要运维了。大型公司,没有工程开发能力的运维,是没有竞争力的。
最重要的学好 python 可以涨工资,可以涨工资,可以涨工资 。(重要的事情说三遍。)
目前本人也是在学 python,正在把以前 shell 脚本的实例转换成 python 脚本。
python笔记: python实例手册(一直在看)
下载链接: http://down.51cto.com/data/2329173
1) 安全意识:
运维人员的权限很大,所以一定要保证帐号/私钥的安全。
2) 磨刀意识:
关于任何操作配置,最好先搞明白操作或配置的原理,然后再去操作。应一句话叫做“磨刀不误砍柴功”,而且对于类似的操作可以举一反三。
3) 计划意识:
复杂的变更操作比如多台主机以及牵涉到san存储,最好先作 操作计划,写计划文档,详细致每条命令,然后请高手帮忙审核。 这样能最大程度使整个操作过程安全。如果是重要的客户业务系统,操作最好有回退方案,而一旦变更失败,客户可以在短时间内将业务回退。
4) 记录分享意识:
遇到自己认为较特殊的案例时,记得要写 案例过程及分析的文档。也方便自己以后翻看,或者和其他兄弟分享,作知识的传播以便于大家以后都能少走弯路。
5) 监控意识:
运维来说,监控是非常重要的,监控是发现系统各种异常的眼睛,所以运维应该和监控紧密配合。
6) 业务意识:
尽量了解维护的各主机上业务类型,以及各主机业务之间的关联性。因为任何维护工作都是为主机能提供业务服务的,当某业务中断,能最快的知道与此业务相关的主机群,从而缩小故障排查范围,最快定位故障。
附上运维思路拓扑图:

可以看看: 安全运维理念(半神半仙亦民工)
意识是很重要,并不是你技术很牛,学的技术很多很熟,就不代表你不需要运维意识,其实领导很看重运维意识的,例如有没有做好备份,权限分配问题,平台测试情况,故障响应时间等,这些都是意识,而不是你学了很多技术自认大牛了,平台发现故障你又没什么大不子,以为很简单的问题喜欢处理就处理,不需要向其它部门反馈等,领导不是看你的技术如何,而是看你的运维意识如何,你没运维意识,技术再牛也没用,只会让其它部门的人跟你不协调。
要知道做IT这行是苦B的,需要无尽的学习,不学习只会被淘汰,不想被年轻的淘汰,就只能不断增值自己,不然不是你工资无法提升,而是你无法再从事这行。
这个世界,在悄悄惩罚不改变的人...
作者:浩子
来源:http://chenhao6.blog.51cto.com/6228054/1949673
————广告时间————
《马哥Linux云计算及架构师》网络课程,由知名Linux布道师马哥创立,经历了8年的发展,联合阿里巴巴、唯品会、大众点评、腾讯、陆金所等大型互联网一线公司的马哥课程团队的工程师进行深度定制开发,课程采用 Centos7.2系统教学,加入了大量实战案例,授课案例均来自于一线的技术案例。
开课时间:随到随学
 课程咨询请长按即可咨询
课程咨询请长按即可咨询






