本文意图透过「XX已死」「XX永生」的烂俗句式背后,回顾2016全年容器技术的发展历程。容器圈惊喜不断的同时,也有些许问题亟待解决。如何理性地思考和解读,才是全年回顾的意指所在。
也说不上什么时候起,「XXX Is Dead. Long Live XXX」的句式突然成为了技术会议上演讲题目的一个标准套路。然而不管已经被引用的多么烂俗,用这套悖论来总结2016年容器技术圈子发生的凡事种种,却实在有种说不出来的恰到好处。
无需多言,稍微回顾一下2016年容器技术圈子的时间线,我们很容易就能回想起容器技术如何在这一年迅速登上云计算舞台的中心。这股热潮,从年初Docker公司闪电收购Unikernel Systems提前扼杀各种「被颠覆」的苗头,蔓延到Kubernetes,Mesos,Docker三家项目在年中掀起的「编排」之争,再到年末阿里云一举震撼国内创业市场。
「编排」,「fork docker」,「OCI runtime」, 「镜像标准」,一个又一个令人目不暇接的关键词带着背后的技术爆点填满了2016一整年的时间线。只不过,惊喜不断的同时,嘈杂的容器圈子也难免给我们带来了些许无所适从的挫败感。回顾这一年的容器技术发展历程,相信大家都有这样的疑惑:当这个圈子平复下来之后,我们该如何去理性地思考和解读呢?
在2016年,当我们再次说出这个关键词的时候,已经很难用一句话解释清楚我们到底在说的是什么。是Docker公司?是Docker容器?是Docker镜像?还是Docker集群?
在创业初期通过一连串极其成功的开源战略迅速蹿红之后,Docker项目几经重构,最终选择了「大一统」的战略模式,一系列普通认知中应该是独立项目的功能模块都被编译进了Docker项目的二进制文件中,这其中最引人注目的,当属SwarmKit项目。
2016年6月,Docker公司宣布将在接下来版本的Docker项目中将会提供内置的「编排」功能,这个功能的实现将主要由一个名叫「SwarmKit」的依赖库来负责。此新闻一出立刻成为容器圈子一时的舆论热点,尤其在国内。其中,看涨者不少,有言「生态闭环」、「Docker正统」,唱衰者也不缺,直呼「公然越界」、「野心昭然」。时至今日,该项目本身也日趋稳定,我们不妨再回头来重新解读一下曾经在风口浪尖上的SwarmKit。
SwarmKit的核心功能乃是「编排」,不过它对这个编排的定义还是比较模糊的,在初期主要指的是「多容器副本」和「副本负载均衡」两个核心能力,后面逐渐加入的是更多应用管理功能。说起这个项目发布的初衷,当时国内的诸多讨论之中,曾有一种误区是认为SwarmKit是Docker Swarm项目的继承、是Swarm项目的「内置版」(当然,这也要部分归功于Docker公司老辣的命名技巧)。但现在回头来看,这些“编排”能力在Docker Swarm项目中,一直都是不存在的,继承自然无从谈起。
SwarmKit唯一跟Docker Swarm项目重叠的功能乃是「调度」,但实际上SwarmKit的调度也是从头做起,它维护了一个NodeHeap(堆),然后通过堆算法配合过滤条件来筛选最符合要求的节点来运行任务。这套调度机制在Swarm中也是不存在的。
而在API层面,Docker Swarm项目提供的是一套简洁的单容器的API来让用户操作容器集群(这个能力非常受欢迎),而SwarmKit却从一开始就引入了Service,Task等一系列面向容器集群的、平台级别的概念,并且从底层实现上就不兼容Swarm风格的单容器API。两者的关系正如同「Java」和「JavaScript」一样风马牛不相及。
那么Docker公司内置“编排”能力并且起一个这样的有混淆意味的名字,到底意义何在呢?
答案很简单:「平台(Platform)」。或者说成是「应用/容器集群管理」,或者说成是「PaaS”甚至“CaaS」,都可以,一个意思。
这个改变的关键就在于,从今以后Docker项目就变成了一个「平台」项目而不再是一个单纯的“容器”项目了。它要站在Kubernetes,DC/OS,Cloud Foundry一样的位置上直面云的终端用户,而不是继续做这些平台背后的容器技术(甚至只是容器技术中的一种)。
这种平台级别的能力对于Docker公司来说是至关重要。容器的热度终究会冷却,用户很快就不会关心底层的容器技术为何物,他们只会记得Kubernetes API,Service, Replication Controller,DC/OS,顶多在编写Dockerfile的时候,才回忆起Docker公司的存在。很多人批评Docker公司野心太大,其实对于一家拒绝了微软40亿美金收购的后端技术创业公司来说,有怎样的进取心都不为过。Docker公司的目标是下一个VMware,下一个Intel,一个实实在在能盈利能上市的商业公司,在这个巨头如林的云计算行业里,这是令人钦佩的。
Docker公司在2016年在集群领域所做的努力离不开「平台」二字,不过国内曾经一度涌现出来的过分解读着实让这个项目背负了太多的压力。其实打开SwarmKit项目的代码看看,从编排到调度,模块设计,代码实现,跟其他项目并无二异,ipvs也是普通的NAT模式,Master节点一样维护着Apiserver, Scheduler, Orchestrator,同宿主机上的Agent通过gRPC交互,就连Agent也跟其他“第三方”项目一样也要通过client去调用Docker Engine的API。所谓的各种「颠覆性」、「大道至简」、「容器OS化」、「从下往上改变容器云形态」等观点,实在无从谈起。
还有一种可能性是Docker公司依靠Docker Swarm这样一个独立的、以单容器操作API为核心的项目来完成PaaS的使命(业界基于Swarm构建PaaS的用户不在少数)。但现实是,几乎同时发布的Google Kubernetes项目却出人意料地狙击了Swarm的发展势头。下图是自发布起,Swarm项目和Kubernetes项目GitHub Star数目的变化统计。
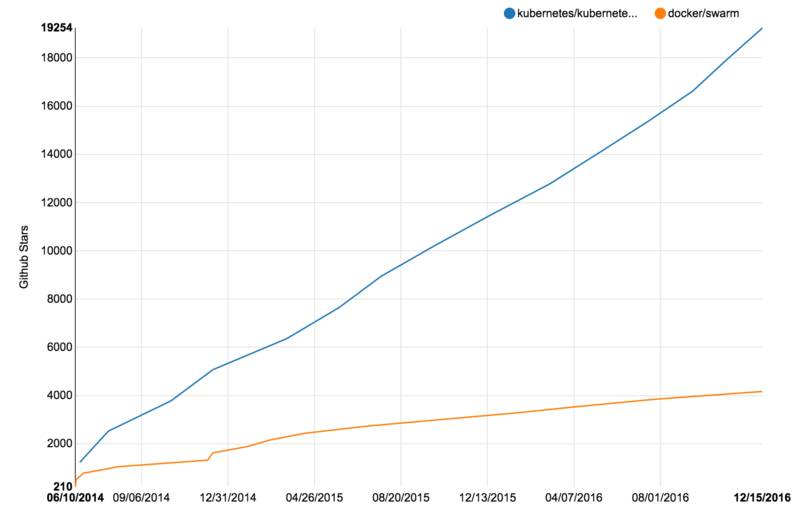
事实上,Docker Swarm项目「使用单容器API来操作集群」的理念是相当有吸引力的。但是这个能力在接下来Docker公司想要重点发展的企业私有云市场却陷入了窘境:单容器API纵然简单友好,但企业级用户却没办法直接用它来实现哪怕一个最简单的「容器集群负载均衡」的需求。所以很多企业私有云用户更倾向于把Docker Swarm项目作为容器云的一个环节,然后自己来实现各种平台级别功能(往往还要参考Kubernetes的各种理念和设计)。
照这个趋势发展,如果不推翻重来提供类似的面向集群的API,Docker公司的平台之梦恐怕就很难实现了。这也正是为什么我们前面简单一对比就不难发现,SwarmKit相比Swarm项目其实是翻天覆地的自我革命,而非继承或者内置,所谓向后兼容的问题自然也无从谈起。
其实,很多人可能已经忘记了早在Docker Swarm项目发布之前,Docker公司已经发布过一个集群管理的项目叫「libswarm」(访问该项目地址有彩蛋:
https://github.com/docker/libswarm
)
。这个项目的初衷非常单纯,就如同Docker项目最开始发布时一样「冰雪通透」:
libswarm项目的初衷是提供一套不依赖于现有分布式系统的集群管理API ,… … ,并使得其他项目可以使用它来方便的构建容器集群 … …
彼时的Docker公司,还希望Mesos,Fleet们使用libswarm来管理Docker容器云呢。
所谓:「Swarm已死,Swarm永生」,Docker项目又何尝不是呢。
在经历了OCI成立、贡献出了核心组件libcontainer之后,Docker公司坚定地走向了独立发展的道路。在巨头们的围剿之中,这是一家创业公司从默默无闻到炙手可热,再到痛定思痛之后的必然选择,SwarmKit,以及其他所有外界看来「野心太大」的项目和举措,都只是这个信念的间接产物而已。
在未来,Docker公司依然会不遗余力的构建自己的平台世界,网络,存储,Infra Layer,CI/CD,一个全功能平台级项目所欠缺的版块都会被一一补全,各种各样内置于Docker Daemon中的Kit库和收购还会层出不穷,Docker公司还会以此为基础重点推广可以盈利的Docker Cloud和Docker Datacenter。这样的选择很正确,并且唯一。
另一方面,在补全平台级别功能的过程中,Docker项目会依然选择将这些管理组件跟原先的Docker Daemon耦合在一起。从技术角度来看,这并不是个明智之选,过高的耦合度所带来的不稳定性、Data Race和维护的问题会愈加凸显。但从推广的角度来看,这个做法非常厉害:Docker项目需要努力争取现有用户和粉丝的青睐,引导他们放弃单容器API,转而接纳新的、平台级别的API。这个转变是站上「Platform」这个舞台在所难免的,也是从Swarm项目上所得来的经验教训。
2016年末,Docker项目将容器运行时相关的最后一个组件containerd也正式剥离,「Docker」这个名字离「容器」渐行渐远,离「PaaS」越来越近。可能有人会疑惑:像Kubernetes,DC/OS,或者未来的Docker项目,它们跟PaaS不是还有所不同吗?实际上,在这股正是由Docker掀起的容器浪潮下,PaaS的定义恐怕早已悄然变化。
正所谓「PaaS已死,PaaS永生」。
在容器集群管理和企业级需求的支持上,Docker公司还是个新生儿,但Docker项目成功的哲学乃是「simple but powerful」,它一直坚持提供尽量简单的命令行界面,并不惜为此选择更复杂的实现方式,这将是它在未来会继续火热的杀手锏之一:对于任何希望快速寻求一个“可用”的容器工具的开发者和运维者来说,这个吸引力是巨大的。
尽管Docker公司整整一年都在「平台」领域发力,Kubernetes依然是这个领域最瞩目的项目。这并非意外,在开源的世界里,一旦在某个领域树立了标杆,就很容易跟竞争对手拉开质的差距。Kubernetes幸运的成为了「容器集群管理」领域的开创者,其他的后进项目,无论是Marathon还是SwarmKit,都只能主动或者被动地follow开创者的提出的理念。这正如同如果让Google再做一个容器,它也会十有八九follow Docker一样。
如果大家只是再造一个Kubernetes,那有什么理由会比Kubernetes团队做的更好?
当然,含着千呼万唤始出来的Borg论文出生,又是Google公司在Big Data领域错失机会之后着重推出的平台级开源项目,Kubernetes本身自然有其过人之处。
Kubernetes的发布给整个容器圈子带来了一系列前所未闻的概念:Service,Replication Controller,Pod,Labels & Label Selector,DaemonSet, Cron Job等等等等。当时,不少用户还在评论Kubernetes的理念太超前了。而现在回头来看,这些特性不仅被用户所接受,而且很多还被其他平台项目比如Docker、Marathon、DC/OS所采纳,变成了它们的内置功能:正如同做容器不支持Docker就显得「落伍」一样,搞平台不谈「Service」、「Replica」,你的编排就不够fancy。
Kubernetes这种相对超前的技术视野与它背后原Google Borg和Omega团队成员的经验和努力密关系巨大。Borg/Omega系统在Google基础设施体系中的声誉和地位无需多言,而用户在Kubernetes中接触到的很多概念,其实在Borg/Omega系统中都有等价的特性。从这个角度来说,把Kubernetes项目描述为Borg系统在开源领域的重生并不为过。
在这一年里,Kubernetes不断地强化自己在容器集群管理领域的优势,密集发布了一系列让人称道的设计。不难预料,这些概念很快也会在其他项目中被借鉴和采纳。
就比如Secret,它允许用户将加密过的Credentials信息保存在Etcd中,然后在容器中通过环境变量或者挂载文件的方式访问它们,从而避免明文密码被随意写在环境变量、配置文件或者Dockerfile中的问题。
类似的还有ConfigMap,只不过保存在Etcd的内容,是应用所需的配置信息。
再比如Deployment,它使得用户可以直接编辑容器化任务的属性,然后直接触发Rolling Updae,还允许用户随意回滚任务到以前的版本。
再比如DaementSet,它允许用户一键部署运行在所有节点上的守护进程任务。
而最近推出的StatefulSet,则提供了原生支持有状态的应用的强大能力,并且既包括了拓扑结构状态,也包括了存储状态。
还有备受欢迎的ScheduledJob,它允许用户用标准的Cron Job格式来定义从镜像启动的定时任务,并保证这个任务执行的正确性和唯一性。
如此种种,都是Kubernetes在容器编排和管理领域树立标杆的手段,而这些设计背后的思想又十分朴素:如果在Borg里,或者在没有容器的传统环境下,我们能够通过脚本或者其他手段自动化地做某些事情,那么Kubernetes同样应该帮你做到。这个过程,正是Kubernetes所定义的(也是我们传统运维意义上的)「编排」,也是DevOps理念中所追求的「No OPs」的主要手段。










