Kubernetes集群已经配置好,“Hello world”程序已经能正常运行。那么,接下来呢?
环顾目前互联网上的内容,我们意识到有非常多很棒的Kubernetes案例发布在文档或者博客中,但这些内容被故意简单化,目的是为了更好地阐述各自的观点。不过,一旦你入了门,你会突然发现,几乎没有真实且可操作的案例或建议来学习。因此, 我们发布了github.com/bitnami/kube-manifests,它包含了我们内部用来管理Kubernetes集群的配置、工具、以及工作流程(workflow)。
Bitnami的全球分布式SRE团队负责3个内部Kubernetes集群,这3个集群都运行在私有的AWS基础设施上。
这些Kubernetes集群的创建和维护都使用的kops工具,并且我们会尽量同步更新Kubernetes的版本。这3个集群的使用目的有些略微区别,这导致AWS防火墙和Kubernetes RBAC规则也会相应变化,不过除了这方面有区别,在其它方面,如集群的基础架构都是广泛类似的。
管理这些服务的配置带来了一些高层次的挑战:
(服务和部署这两个词在Kubernetes中有特定的含义,因此我将使用“Service”(大写)来表示Kubernetes的Service资源,而“service”(小写)来表示常见的一般含义。)
关于集群功能的简单介绍
Git项目中包含的jsonnet配置是直接从我们当前的活跃代码仓库中直接拿出来的,当然,我们会对它们进行一些小小的清理。我们删除了RBAC规则,以及Bitnami产品软件的配置。查看文件,你会发现关于遗留系统以及正在进行的实验的注释。
很多的自动化工作流都是基于运行在集群上的Jenkins。
所有的容器日志都通过一个经典的elasticsearch stack来收集。
我们的Ingress资源通过nginx-ingress和内部的AWS ELBs实现。我们使用letsencrypt自动化产生SSL证书,并且在kube-cert-manager中选择了DNS challenges,这是因为我们的ELBs不能够接收外部请求。我们还拥有一个DNS wildcard *.k.dev.bitnami.net 指向Ingress ELBs。这些配置使得我们的开发者可以只创建一个合适的Ingress规则,接下来系统会为他们自动生成一个域名、SSL证书、以及HTTP到HTTPS的重定向。
我们的容器和遗留的VM service使用prometheus来监控,并且能够通过添加适当的注释和标签来获得自配置的功能。重要的是,之前提到的jenkins、elasticsearch以及nginx都已经配置好,能够输出prometheus的度量,因此service能够直接获得HTTP级别的请求/状态码等统计信息,而不需要做额外的工作。
根据以往的经验和教训,我们选择了一种基础架构即代码(Infrastructure as Code)的方式。这种方式会尽可能地通过版本控制系统(git)中的文件来描述集群的配置,然后使用我们熟悉的代码工作流,如评审和单元测试来管理我们的基础架构。
将我们理想的环境存编写在git中是非常棒的,因为我们的团队能够讨论基础架构的版本控制,并且在开发、评审、测试、更新、回滚这些过程中使用统一的版本。所有的这些好处降低了团队沟通的复杂度,从每个团队员工之间的交流O(!n)降低到了团队与中央仓库的交互O(n)。
Kubernets原生支持将所有信息写在Json(或者等同的YAML)中。
这里有一个YAML的例子。(没关系,我只是想表达一个高层次的观点,因此可以随意跳过这些细节):
apiVersion: v1
kind: Service
metadata:
labels:
name: proxy
name: proxy
namespace: webcache
spec:
ports:
- port: 80
targetPort: proxy
selector:
name: proxy
type: ClusterIP
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
name: proxy
name: proxy
namespace: webcache
spec:
minReadySeconds: 30
replicas: 1
revisionHistoryLimit: 10
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
name: proxy
spec:
containers:
- name: squid
# skipped, for clarity
Kubernets的资源定义拥有很多的重复性模板,一个相同的值重复出现在几乎相关的资源中。我们想要一个工具,能够表达出模式的继承功能,不仅支持Kubernetes资源定义,并且在我们自己的基础架构中的资源定义也能够使用。在调研多个不同选择后,我们选择了jsonnet,原因如下:
声明式的,无副作用(side-effect-free)语言在复杂的情况系统中能够减少意外的发生。
能够原生地生成JSON,而不仅仅是一个特定领域专用的语言,只能够将几个特殊的字符片段拼接起来。
支持多个输入文件,并且拥有一个强大的合并功能,它使得我们能够构建通用模板的库。
当我们在Google工作时,也遇到类似的问题,那时我们使用了一个类似的语言。
缺点:小众,并且没有被预安装在主流的linux发行版中。
为了演示效果,我们这里使用了kube.libsonnet库,之前提到的配置文件重新用jsonnet语法编写后,如下图所示。值得注意的是,无聊繁琐的工作已经被库自动处理了,开发者只需关注高层次的内容,如Service和Deployment之间的关系,以及任何关于基础模板的异常(比如要显示的设置namespace)。
{
namespace: "webcache",
squid_service: kube.Service("proxy") {
metadata+: { namespace: $.namespace },
target_pod: $.squid.spec.template,
port: 80,
},
squid: kube.Deployment("proxy") {
metadata+: { namespace: $.namespace },
spec+: {
template+: {
spec+: {
containers_+: {
squid: kube.Container("squid") {
// skipped, for clarity
},
},
},
},
},
}, // Kubernetes structures are deep :)
}
我不想在这里重新介绍jsonnet的语法,你可以直接参考jsonnet的教程。唯一我想要强调的就是,jsonnet拥有一个强大的合并功能,这个功能除了发生在其他表达式被展开之前外,其他方面很像python的dict.update。这个合并操作超级有用,它使用“+”标识,你可以在上面的配置文件中看到很多这个符号。
不过,例外情况总是存在的,每一个Kubernetes配置选项都对应了一个合法的用例场景。因此,我们选择传递整个Kubernetes资源对象(添加了一些可选的帮助选项使得它更接近原生的jsonnet)而不是一些简化过的中间结构。这意味着我们可以直接对接标准的Kubernetes文档,而不是自定义,并且它允许任何Kubernetes选项在模板栈(template stack)的任何一层被覆写。
表达相似性
我们的相似性主要指的是:
运行在多个集群的通用模块
横跨多个模块的通用部署模式
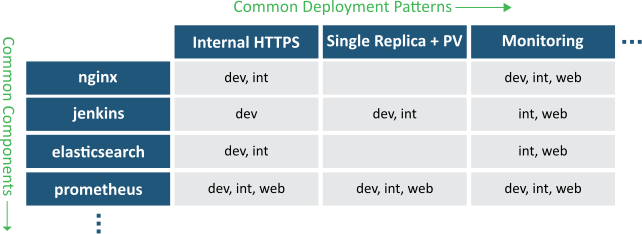
因此,大多数的模板有3层:基础层->特殊软件层->特殊部署层。我们的目录结构也符合这个分层结构:
补充一点,不像其他简单的工作流,我们使用了显式的Kubernetes命名空间声明。这是因为我们的团队管理了很多不同的软件栈,因此我们不能依赖某些神奇的外部环境来保证命名空间的正确性。
下面列举的工具是经过深思熟虑后的选择,这证明了当前Kubernetes架构的强大力量。当基础设施出现了问题,能够重新从第一步将它拼接回来是极好的。
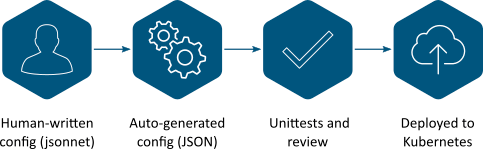
开发者在他们最喜欢的编辑器中编辑jsonnet文件。在实际场景中,为了测试,总是会有一个“编辑、运行jsonnnet、推送到dev集群,查看结果”的循环过程。Kubecfg.sh脚本使得这个过程变得简单。我们关于dev集群的宗旨就是“善待开发者,任何改动都能够被重新恢复到git中的任一个阶段”
Jsonnet文件被扩展成正常的json文件,这个过程使用了一个简单的jsonnet-in-docker脚本,它会被Makefile触发。我们发现JSON文件能够让作者和评审者清楚的知道改动会影响什么内容,尤其是当你修改了基础模板时。
不同的单元测试会对jsonnet和JSON文件进行测试。我们的jsonnet代码包含了许多的assert语句,这些都会在JSON生成的过程中被验证。我们还额外地检查了jsonnet代码风格的一致性,因此生成的JSON文件非常准确,符合Kubernetes的jsonschema,并且所有的资源都有一个显式的命名空间。重要的是,在任何时间这些检查都是安全的,因此我们可以在github pull请求的时候执行这些检查。
团队成员能够通过常规的github代码评审来查看改动。他们知道多个自动化测试已经通过了,因此他们能够专注于高层次的内容正确性而不是语法正确性。当觉得改动能够接受时,只需要点击同意,就能够完成合并了。
合并之后,jenkins自动对每个集群运行deplo.sh脚本来部署这些改动。已有的Deployment检查和首航(rollout)策略都能防止灾难性的改动被通过。此外,我们还有持续性的监控来报告任何错误的发生。重要的是,首航策略足够缓慢,因此监控系统能够给我们足够的时间来应对以及冻结这次崩溃的首航,这些可以通过常规的kubectl rollout pause和undo命令来完成。我们拥有过去的所有历史记录,因此我们能够通过回滚git中错误的改动来完成恢复。
这套系统运行地非常好,不过,Jsonnet是一个实实在在的编程语言(尽管很小),在你草率的选择它之前,我建议你通读一遍jsonnet的教程。
我们的基础模板目前直接表达出资源名字,这使得在同一个Kubernetes命名空间中,同一个栈很难拥有一个以上的实例。我们可以很简单地在jsonnet库中解决这个问题,但我们还没做这件事情。
总之,这是一个工具箱,一个流程,而不是一个打包好的产品。由此带来的好处就是你能够修改这些工具来适配你的真实场景;缺点就是你不能够通过两个简单的命令来获得这个功能。
好消息是在Kubernets sigapps组中大家进行了活跃的讨论,并且我们一直在积累经验。我对未来的工具和配置的提升感到非常激动。
本文为翻译文章,点击阅读原文链接可查看原文。







