本文介绍了来自清华大学智能产业研究院助理教授赵昊团队联合哈佛大学眼科AI实验室提出的Point-Image Diffusion眼底图像合成方案。该方案率先提出“先生成标签,再由标签生成图像”的两段式图像生成范式,旨在解决医学眼底图像分割中针对少数群体的偏见问题。实验结果表明,合成数据质量优于现有方法,并且在公平性和分割性能上实现了显著提升。
介绍赵昊团队提出的Point-Image Diffusion方案,该方案通过生成标签再合成图像的方式,改善了眼底图像的合成质量。
介绍实验数据集、评估指标、合成图像结果和公平性分割结果,证明提出的方案在公平性和分割性能上的优越性。
近日,来自清华大学智能产业研究院助理教授赵昊老师(
https://sites.google.com/view/fromandto
)的团队,联合哈佛大学眼科AI实验室,提出了一种名为 Point-Image Diffusion 的眼底图像合成方案。
该方案率先提出“先生成标签,再由标签生成图像”的两段式图像生成范式。point2mask 和 mask2image 的两阶段合成框架既能得到配对标签,又能改善对生成图像分割边界控制。实验结果表明,合成数据质量优于现有方法。面对医学眼底图像分割中针对少数群体的偏见问题,团队通过合成数据与真实数据相结合的方案,提升了医学图像分割模型的公平性。

论文题目:
FairDiff: Fair Segmentation with Point-Image Diffusion
论文链接:
https://arxiv.org/abs/2407.0625
0
代码链接:
https://github.com/wenyi-li/FairDiff
一、背景介绍
公平性
在医学影像分析中是一个重要课题,特别是在不同目标群体训练数据不平衡的情况下。为了解决这一问题,我们提出了一种基于混合数据的策略,通过引入少数群体的合成图像来增强数据公平性。
通过扫描激光眼底成像(SLO)来判断眼部的杯盘比(Cup-Disc Ratio),在诊断一系列眼部疾病中非常重要。然而,不同种族的眼底解剖结构存在差异。例如,黑人通常比其他种族有更大的杯盘比,而亚洲人比白人更容易患上角闭性青光眼。因此,当训练数据不平衡时,针对SLO图像的分割模型往往会带有对某一特定群体的偏见。但是,获取少数群体中患者的真实样本数据是一件十分费时费力的事情,因此,引入合成数据成为了一种解决方案。
然而,在生成合成图像方面,
以往的工作要么缺乏配对标签,要么无法精确控制合成图像的边界与标签对齐
。为解决这个问题,我们采用了一种联合优化的方法,通过优化三个网络以实现经验风险最小化和公平性最大化。具体实现上,我们创新地提出了一种
Point-Image Diffusion 架构
,利用 3D 点云通过 point-mask-image 合成框架
既能得到配对标签,又能改善边界控制
。实验证明,这种方法在扫描激光眼底成像(SLO)图像上的合成效果显著优于现有技术。通过在训练阶段将高质量合成数据与真实数据结合,我们的模型与目前最好的公平学习模型相比,实现了更高的公平分割性能。
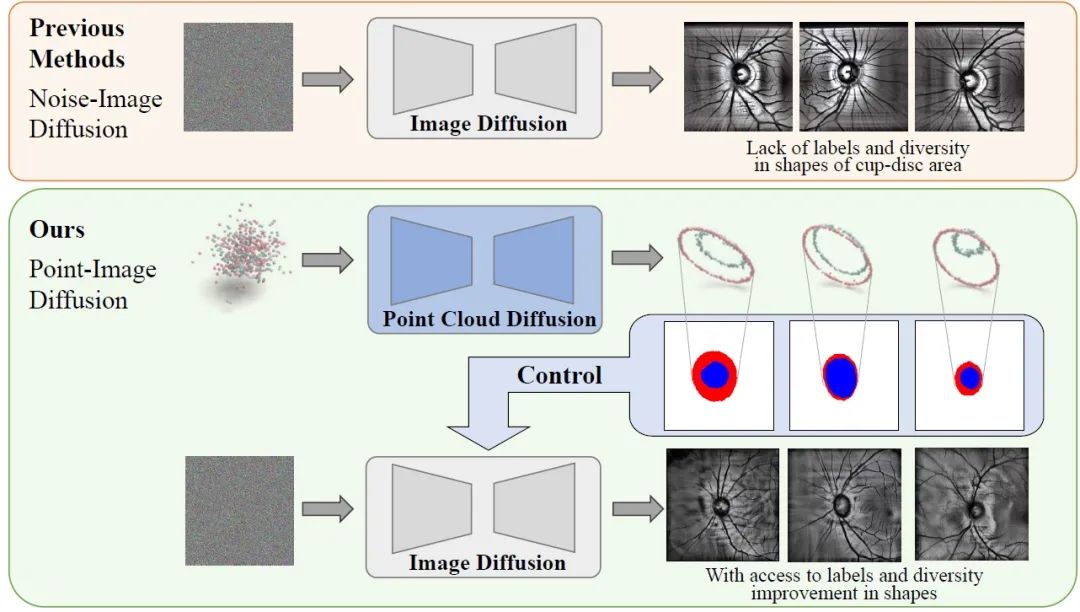
二、方法
2.1 概述
本文采用了一种全新的 Point-Image Diffusion 架构。首先,我们将图像的分割 mask 从 2D 转化为 3D,以更好的利用三维空间坐标。然后,通过点云扩散模型生成丰富的 3D 点云分布,增强分割 mask 的多样性。接下来,利用mask 作为 ControlNet 的控制条件,生成高质量的 SLO 图像。最后,将生成的合成数据与真实数据混合,以弥补少数群体样本的不足。训练时的目标是优化整个模型的公平性和分割性能。
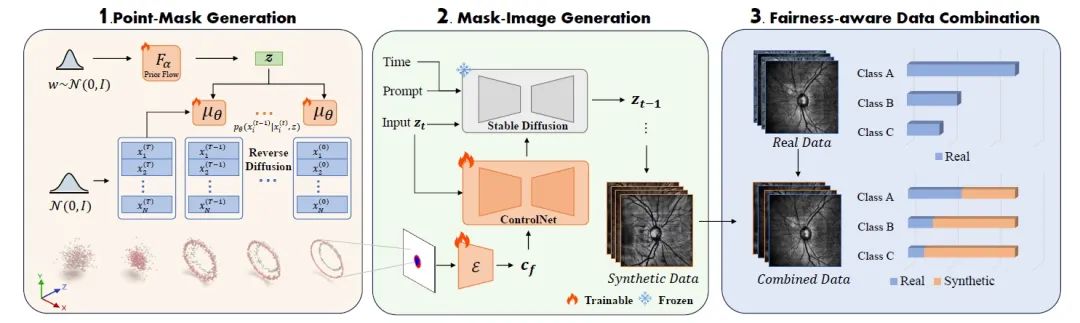
2.2 Point-Mask 生成
为了生成多样的眼底图像并获得精确的配对标签,我们首先使用真实数据的标签来增强分割 mask。具体来说,我们
将 2D mask 图像转换为 3D 点云
,以更好地捕捉分割边界的坐标。给定一个大小为
的 2D 掩模图像,
和
分别是图像的宽度和高度。函数
将
映射到 3D 点云
进行训练。
定义如下:
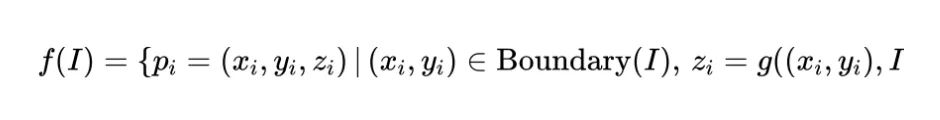
其中
是图像
中像素的坐标,
表示位于分割边界上的像素,
是一个基于像素位置分配
值的函数。
定义如下:
将现有的 2D 标签转换为 3D 点云后,我们采用点云扩散模型学习来学习这些点云的分布。这个模型的主要训练目标是模拟一个随机扩散过程的逆过程,学习从正态分布到真实点云的分布。在训练阶段,我们在点云中引入不同程度的随机噪声,并确保去噪模型预测的噪声与实际添加的噪声非常接近。对于敏感属性
的每个组
,我们训练一个点云扩散模型
。由于
能够有效捕捉不同人群的眼底杯盘轮廓特征,我们可以有选择地增强不同组的样本,特别是对于少数群体。通过这种方法,我们为后续的数据混合准备了标签集。
2.3 Mask-Image 生成
在生成了分割 mask 后,下一步是合成图像。我们使用了 ControlNet
,
将上一步的 mask 作为控制条件指导图像生成
。ControlNet 通过冻结原始的 Stable Diffusion 模块参数,并将其复制到一个可训练的副本中,通过额外的卷积层进行连接。在训练过程中,网络逐渐根据输入条件调整输出,从而实现对原始特征图的控制,生成高质量的图像。利用 ControlNet,我们不仅能生成与真实图像风格相似的眼底SLO图像,还能保证生成的图像与分割 mask 之间的一致性,从而得到配对的图像-标签。
具体来说, 上一步生成的标签
被编码成 token
,然后将这些 token 输入到 ControlNet 中。ControlNet 的输出
如下所示:
其中
是 ControlNet 块的输出,
表示零卷积层,
和
是两个零卷积层的参数。在训练开始时,由于零卷积层的权重和偏置初始化为零,
等于
,确保不会向网络的隐藏状态引入有害噪声。随着训练的进行,零卷积层根据输入条件 逐
渐调整输出,从而实现对原始特征图
的控制。
2.4 等规模数据组合
为了最终使得我们合成的数据能够提升整个医学图像分割任务中的公平性,我们提出了一种
简单而有效的数据组合方法,即等规模数据组合
。通过在所有敏感群体样本规模来确保公平性。
假设我们有来自真实数据分布和合成数据分布的样本点集合,如果某个群体的样本量不足,我们会生成额外的合成样本;如果样本量过多,则进行随机抽样。最终目标是让不同群体的样本数量一致。例如,由于医疗设备有限,黑人的眼底数据样本数远低于白人,我们可以通过数据的合成和采样的方式,增加黑人眼底数据的样本数量,达到与白人样本数量相同的规模。这种方法能够从数据角度解决不平衡问题,确保每个敏感群体在训练数据集中都有足够的样本量。
三、实验和结果
3.1 数据集
我们使用 Harvard-FairSeg 数据集作为真实的 SLO 眼底图像数据集,该数据集涵盖了六个关键属性:年龄、性别、种族、族裔、语言偏好和婚姻状况。测试上,无论是只使用真实数据,还是使用合成数据与真实数据的混合,所有模型都在 Harvard-FairSeg 的 2000 张真实的 SLO 眼底图像上进行测试。
3.2 合成图像结果
评估指标
为了评估生成质量,我们采用了几种度量指标,包括Fréchet Inception 距离(FID)、最小匹配距离(MMD)和覆盖率得分(COV)。
FID基于 Inception 网络的特征提取能力,评估生成图像的分布与真实图像分布之间的差异。
最小匹配距离(Minimum Matching Distance, MMD)得分用于衡量生成样本的保真度。它通过计算生成样本与真实样本之间的最小匹配距离的平均值来评估生成模型的质量。这里定义了图像
与图像
之间的距离
为:
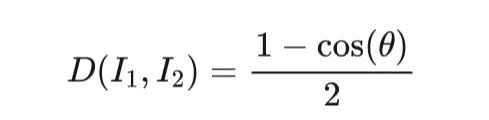
覆盖率得分(Coverage, COV)表示真实样本中至少与生成图像中的一幅图像匹配的比例。对于生成集
和参考的真实集
, COV 得分定义为:
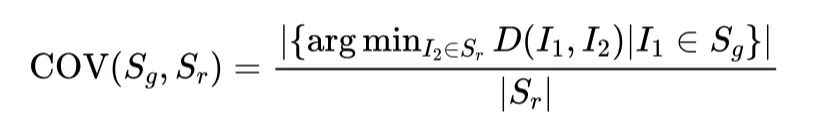
实验结果
我们将我们的 Point-Image 图像生成方法与几种最先进的方法进行了比较,包括 Stable Diffusion 1.5 , pix2pixHD, OASIS, SPADE 和ControlNet 。如表1所示,我们的方法在SLO眼底图像合成方面显著优于现有技术。值得注意的是,我们的方法获得了最低的FID得分,这表明与其它方法相比,我们生成的图像与实际图像更为相似。此外,MMD结果表明,我们的方法也能更准确地复制原始图像数据集的分布。
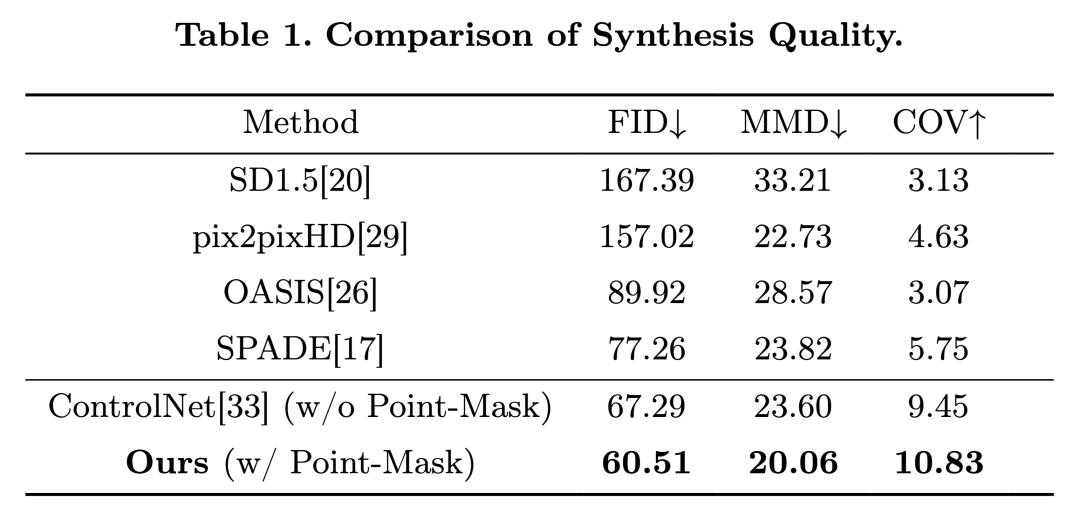
针对 two-stage 扩散模型的消融研究
与 ControlNet(one-stage的标签到图像生成模型)相比,我们的 two-stage 流程首先采样标签,然后合成图像,在生成多样化图像方面显示出了有效性。这一点反映在评估方法中
最高的覆盖率(COV)得分上
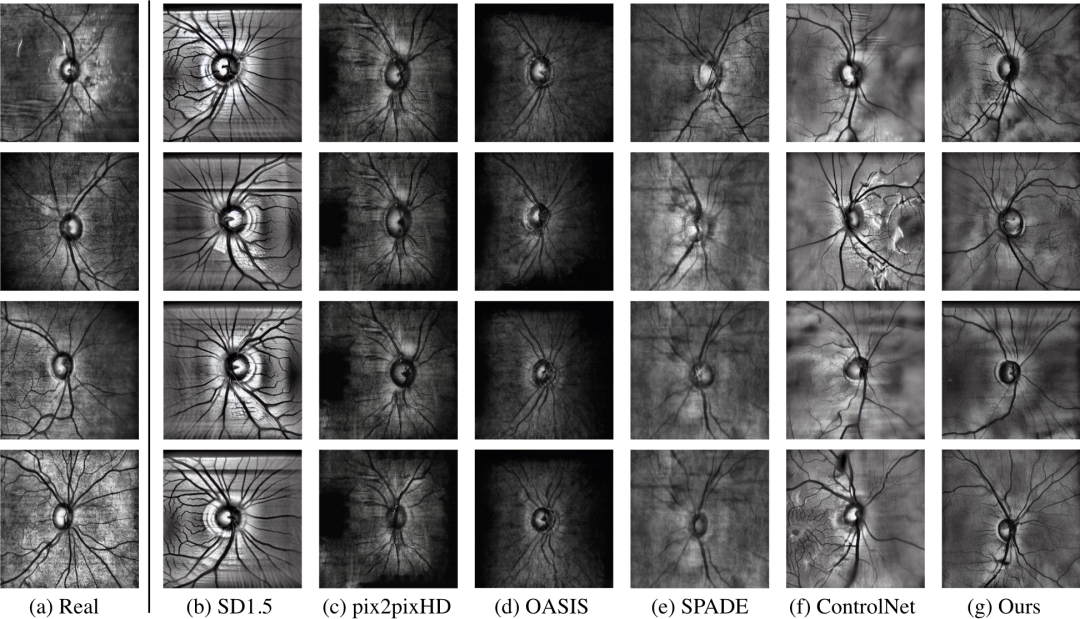
。图像质量和多样性的提升凸显了我们图像合成技术的有效性。下图展示了合成图像的结果。
3.3 公平性分割结果
为了验证我们的合成数据对分割和公平性的影响,我们选择了两种分割模型,包括一个较小的模型 TransUNet 和一个较大的模型 SAMed。
在分割模型的训练中,遵循 Harvard-FairSeg的实验设置,我们采用了交叉熵和 Dice 损失的组合作为训练损失。对于训练样本的数量,无论是使用全部真实数据还是真实与合成数据的混合,我们都控制在8000个样本。
按照之前的研究,我们使用
公平性分割性能(Equity-Scaled Segmentation Performance,ESSP
)
来衡量分割结果的公平性。ESSP 的定义为:











