本文从设计及服务可用性方面,详细解析了微博短视频高可用、高并发架构设计中的问题与解决方案。

今天与大家分享的是微博短视频业务的高并发架构,具体内容分为如下三个方面:
-
团队介绍
-
微博视频业务场景
-
“微博故事”业务场景架构设计
团队介绍
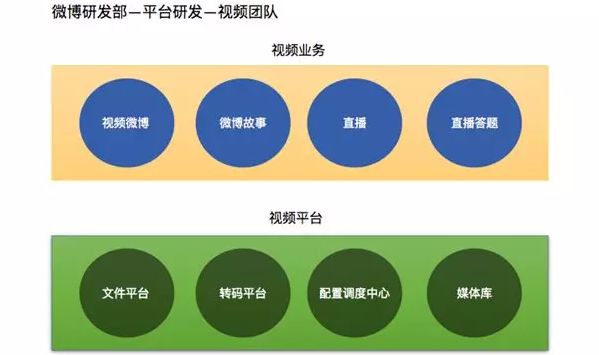
我们是隶属于微博研发部视频平台研发部门的技术团队。平台研发是微博的核心部门之一,包括大家熟知的微博视频在内的微博所有核心业务的基础平台架构、用户关系体系等都依赖微博平台研发部门的技术支持。
我们的团队主要负责与视频相关的上层业务也就是视频微博、“微博故事”以及短视频和直播,其中直播包括常规的直播与直播答题等新玩法。
同时我们还负责底层视频平台的架构搭建,包括文件平台、转码平台、配置调度中心与媒体库。
我们致力于用技术帮助微博从容应对每天百万级的视频增量与其背后多项业务的多种定制化需求。
微博视频业务场景

我们的业务场景主要是应对热门事件的流量暴涨,例如明星绯闻、爆炸性新闻等势必会让流量在短时间内急剧增长的事件。
如何从架构上保证流量暴涨时整体平台的稳定性?
如果只是简单地通过调整服务器规模解决,流量较小时过多的服务器冗余带来成本的浪费,流量暴涨时过少的服务器又令平台服务处于崩溃的边缘。
比较特别的是,我们面临的问题与诸如“双十一”这种在某一确定时间段内流量的可预见式高并发有着本质的不同,我们面临的流量暴涨是不可预见的。
因此通过哪些技术手段来妥善解决以上问题,将是接下探讨的重点。
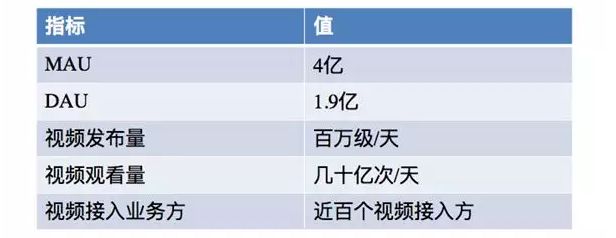
以上是基于微博的过去已经公开数据量级,非近期内部数据。微博视频是一个多业务接入的综合平台,你可以在微博上看见现在市面上的各种玩法。
这就导致我们即将面临的并不是某个垂直业务领域的命题,而是一个构建在庞大体量下的综合性命题,这就导致现有的通用技术框架无法妥善解决我们所面临的难题。
因为一些开源方案无法顺利通过技术压测,所以我们只能在开源方案的基础上进行自研与优化才能得到符合微博应用场景需求的技术解决方案。
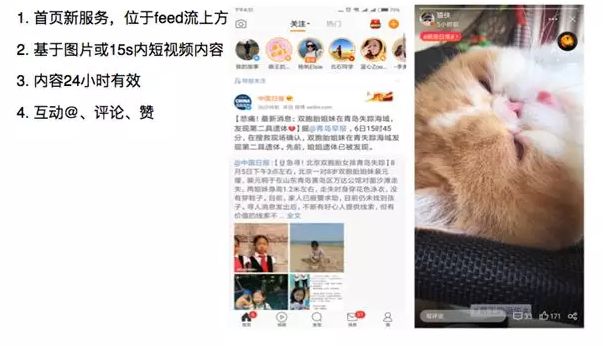
微博的短视频业务被称为“微博故事”,上图展示的是“微博故事”的展现形态。这是一个布置在微博首页一级入口上的模块,主要展示的是用户关注的人所上传的 15 秒内的短视频。
我们希望强调其“即时互动”的属性,视频只有 24 小时的有效展示时间。不同用户的视频按照时间轴在上方排序,多个视频可依次观看、评论、点赞等。
“微博故事”业务场景架构设计
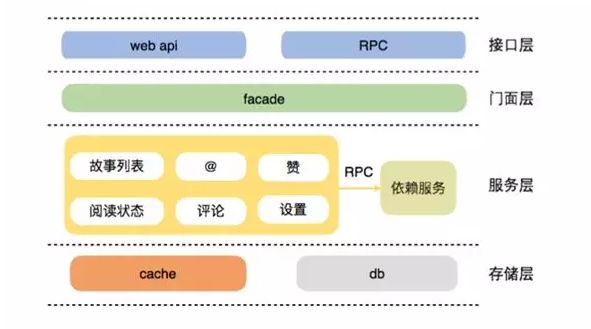
上图展示的是这项业务的微服务架构:在接口层我们混布了 Web API 与内部的 RPC 请求。
在这里我们并未集成具有实际意义的门面层,而接下来的服务层集成了许多微服务,每个微服务集中在一个垂直功能上并可对外提供接口,这里的门面层主要作用是聚合一些微服务并对外提供综合性接口。
除此之外还有一些依赖服务例如用户关注、也需要依赖于其他部门的 RPC 服务;最后的存储层则是集成了 Cache 与 db 的标准方案。
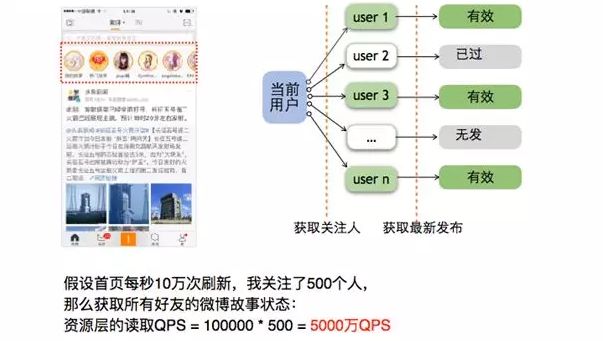
有人曾问到:微博短视频业务的高并发有多高?
假设我关注了 500 名好友,如果有好友发布一个视频就会在“微博故事”头像列表上显示一个彩圈用以提示我去观看。
如果我想知道自己所有关注的 500 个人所发的视频内容,假设首页每秒刷新十万次,那么需要每秒钟五千万的 QPS。
除此之外我们还需要确定视频是否过期、视频发送顺序等,实际的资源层读取量将远远高于五千万。

在构建解决方案时我们思考:可以借鉴微博之前的 Feed 解决方案,我们不会进行无意义的重复性工作与思考。
即使短视频与 Feed 都具有首页刷新与关注人发布消息聚合的特点,但以用户列表为形式,强调进度续播与即时互动的短视频和以内容列表为形式,强调无阅读状态与永久保存的微博具有本质的区别。
面对一般的 Feed 应用场景可以使用以下两种模型:
①Feed 推模型
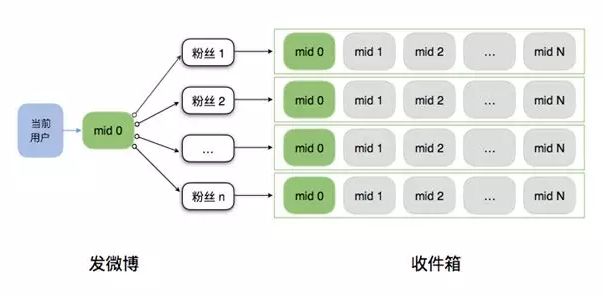
Feed 推模型是指将用户上传发布的内容推送至每一位粉丝,这种方案具有很大的弊端。由于用户尚未达成一定规模,早期的微博以 Feed 推模型为主导。
而现在一个大 V 用户的粉丝数量普遍都是千万级别,如果依旧使用 Feed 推模型则意味着千万量级的内容推送,在难以保证千万份推送一致性的情况下,势必会为服务器带来巨大压力。
微博的业务强调的就是强时效性下的内容一致性,我们需要确保热点事件推送的瞬时与一致。
除了从技术层面很难确保千万级别内容推送的时效性与一致性,由于用户上线状态的不统一,为离线的用户推送强时效性的内容无疑是对服务器等资源的巨大浪费,为了避免以上麻烦我们必须改变思路。
②Feed 拉模型
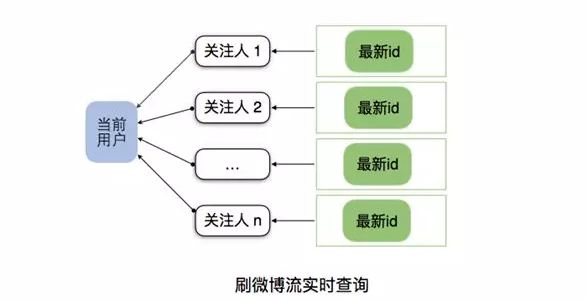
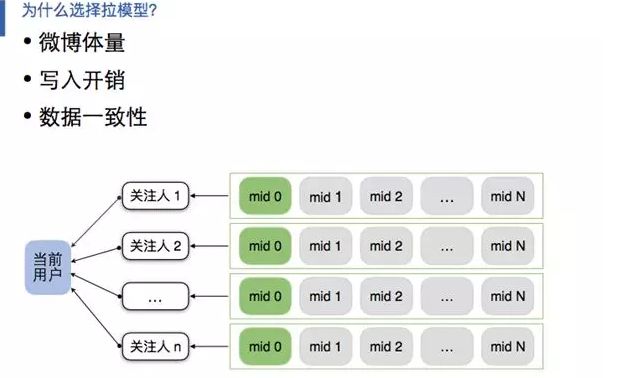
Feed 拉模型:
拉取关注的人并实时查询状态及内容。综合微博的庞大用户体量、数据写入开销与确保一致性三方面,我们决定选择 Feed 拉模型。
如何通过 Feed 拉模型应对如此规模庞大的 QPS?
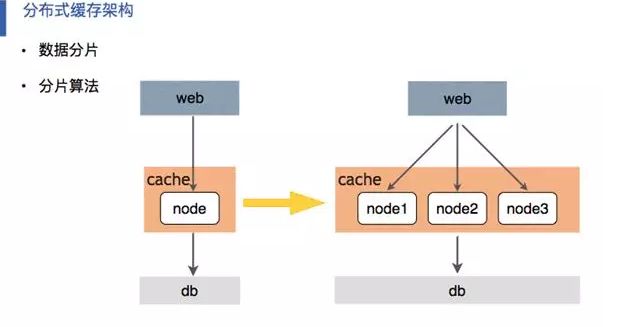
首先我们采用了分布式缓存架构,在缓存层集成了数据分片并将缓存通过哈希算法合理分片,之后再把缓存去切片化并进行存取。
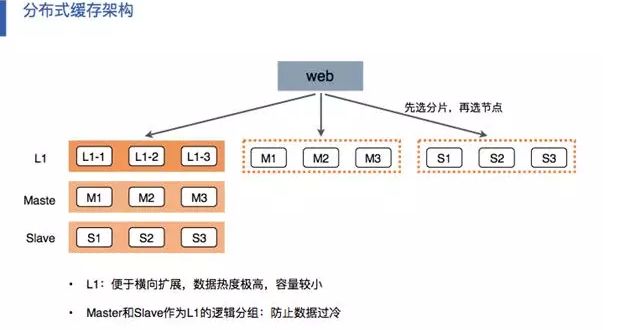
其次我们使用了独有的多级缓存方案也就是 L1、 Master 、Slave 三层缓存方案。
L1 是一个热度极高容量极小的缓存,我们称其为“极热缓存”,其特点是便于横向扩展。
假设 L1 只有 200MB 缓存,我们使用 LRU 算法通过热度分析把访问最热的数据存储在 L1 中;之后的 Master 与 Slave 的缓存空间则是 4GB、6GB,比 L1 大很多倍。
因为微博的流量比较集中于热点事件中某几位明星或某个新闻,小容量的 L1 可进行快速扩容;在发生热门事件时利用云的弹性自动扩容从而分担热点事件短时间激增的流量压力。
由于自动扩容时 L1 仅占用每台缓存中很小的空间,扩容的速度就会非常快,通过这种手动或自动的瞬间弹性扩容来确保服务器稳定承受热点事件背后的数据激增量。
第二层的 Master 与 Slave 具有比 L1 大好多倍的缓存空间,主要用于防止数据冷穿。
虽然 L1 主要承担的是热点数据,但却无法确保一些短时间内不热但在某个时间段热度突然高涨所带来的流量短时间爆发时服务器的稳定性。
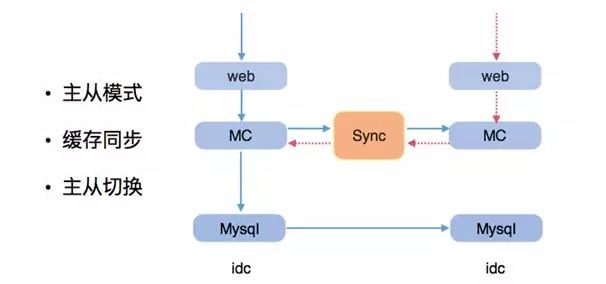
而 Master 与 Slave 作为 L1 的逻辑分组可有效防止数据过冷,在这里我们采用的是 HA 多机房部署。
例如图中的的两台 IDC,我们称左边为 IDC-A,右边为 IDC-B。缓存层的 Master 与 Slave 是主从同步的关系,双机房的缓存互相主从同步。
这里的“互相主从同步”是指 IDC-A 的 MC 与 IDC-B 的 MC 之间进行双向同步互为主从。
因为在进行双机房部署时需要均衡两个机房的流量负载,在缓存层需要使用 LRU 算法进行热度分析。
如果我们将流量分为两份并传输至两个机房,通过每个机房的 IRU 算法得到的热度信息有一定失真。
如果我们在缓存层做相互同步后每个机房的 MC 都是一个全量的热度算法,那么两个机房的 L1 基本可实现同步计算得出的热度信息一定是准确的,只有保证热度信息的准确无误才能从容应对流量激增与整个系统的高可用性。
在这里需要强调的是,实际上我们在选型上使用的是 MC 而未使用 Redis。








