
简介
几乎所有人都喜欢与家人、朋友一起观看电影度过闲暇时光。大家可能都有过这样的体验:本想在接下来的两个小时里看一个电影,却坐在沙发上坐了20分钟不知道看什么,选择困难症又犯了,结果好心情也变得沮丧。所以,我们很需要一个电脑代理,在做挑选电影的时候提供推荐。
现在,电影智能推荐系统已经成为日常生活中的一部分。
Data Science Central 曾表示:
“虽然硬数据很难获得,但知情人士估计,对亚马逊和Netflix这样的大型电商平台,推荐系统为它们带来高达10%至25%的收入增长”。
在这个项目中,
我研究了一些针对电影推荐的基本算法,并尝试将深度学习融入到电影推荐系统中。
把娱乐与视觉艺术相结合,电影是一个很好的例子。电影海报可以直接、快速地把电影信息传达给观众。Design Mantic表示:“不论上映前后,电影海报都是创造噱头的主要因素。多半的人(目标观众)都根据海报来决定买不买票,看不看电影。”我们甚至可以仅仅根据海报字体,来推测这个电影的情绪。
这听起来有点像魔术——但看一眼海报就预测出电影的类型,的确是可能的。就拿我来说,瞟一眼海报就知道我想不想看这个电影了。举个例子,我不是卡通迷,一看到有卡通主题海报,就知道不是我的菜。这个决策的过程很直接,并不需要阅读电影评论(不确定谁真的有时间读那些评论)。因此,除了标准的电影推荐算法,我还用了深度学习来处理海报,并将相似的电影推荐给用户。最终目标是模仿人类视觉,并仅仅通过观察海报,就能用深度学习创建一个直观的电影推荐系统。该项目是受到Ethan Rosenthal博客启发。我对他博客里的代码进行了修改,以适应这个项目的算法。
我们用的是从 MovieLens 下载的电影数据集。他包含9066个电影和671名用户,分成了100000个打分和1300个标签。这个数据集最后更新于10/2016.
协同过滤
粗略地说,有三种类型的推荐系统(不包括简单的评级方法)
“基于内容的推荐”是一个回归问题,我们把电影内容作为特征,对用户对电影的评分做预测。
而在“协同过滤”推荐系统中,一般无法提前获得内容特征。是通过用户之间的相似度(用户们给了用一个电影相同的评级)和电影之间的相似度(有相似用户评级的电影),来学习潜在特征,同时预测用户对电影的评分。此外,学习了电影的特征之后,我们便可以衡量电影之间的相似度,并根据用户历史观影信息,向他/她推荐最相似的电影。
“基于内容的推荐”和“协同过滤”是10多年前最先进的技术。很显然,现在有很多模型和算法可以提高预测效果。比如,针对事先缺乏用户电影评分信息的情况,可以使用隐式矩阵分解,用偏好和置信度取代用户电影打分——比如用户对电影推荐有多少次点击,以此进行协同过滤。另外,我们还可以将“内容推荐”与“协同过滤”的方法结合起来,将内容作为侧面信息来提高预测精度。这种混合方法,可以用“学习进行排序”("Learning to Rank" )算法来实现。
该项目中,我会聚焦于“协同过滤”方法。首先,我将讨论如何
不使用回归,
而是
电影(用户)相似度来预测评分
,并基于相似度做电影推荐。然后,我将讨论如何
使用回归同时学习潜在特征、做电影推荐
。最后会谈谈
如何在推荐系统中使用深度学习
。
电影相似性
对于基于协作过滤的推荐系统,首先要建立评分矩阵。其中,每一行表示一个用户,每一列对应其对某一电影的打分。建立的评分矩阵如下:
df = pd.read_csv('ratings.csv', sep=',')
df_id = pd.read_csv('links.csv', sep=',')
df = pd.merge(df, df_id, on=['movieId'])
rating_matrix = np.zeros((df.userId.unique().shape[0], max(df.movieId)))
for row in df.itertuples():
rating_matrix[row[1]-1, row[2]-1] = row[3]
rating_matrix = rating_matrix[:,:9000]
这里“ratings.csv”包含用户id,电影id, 评级,和时间信息;"link.csv"包括电影id, IMDB id,和TMDB id。每一个电影利用 API 从 Movie Databasewebsite 获得海报,都需要 IMDB id——因此,我们将两个表格结合到一起。我们检验了评分矩阵的稀疏性,如下:
sparsity = float(len(ratings.nonzero()[0]))
sparsity /= (ratings.shape[0] * ratings.shape[1])
sparsity *= 100
当非零项(entry)只有1.40%的时候评级矩阵是稀疏的。现在,为了训练和测试,我们将评分矩阵分解成两个较小的矩阵。我们从评分矩阵中删除了10个评分,把它们放入测试集。
train_matrix = rating_matrix.copy()
test_matrix = np.zeros(ratings_matrix.shape)
for i in xrange(rating_matrix.shape[0]):
rating_idx = np.random.choice(
rating_matrix[i, :].nonzero()[0],
size=10,
replace=True)
train_matrix[i, rating_idx] = 0.0
test_matrix[i, rating_idx] = rating_matrix[i, rating_idx]
根据以下公式计算用户/电影中的(余弦Cosine) 相似性
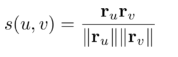
这里s(u,v)是用户u和v之间的余弦相似度。
similarity_user = train_matrix.dot(train_matrix.T) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_user))])
similarity_user = ( similarity_user / (norms * norms.T) )
similarity_movie = train_matrix.T.dot(train_matrix) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_movie))])
similarity_movie = ( similarity_movie / (norms * norms.T) )
利用用户之间的相似性,我们能预测每个用户对电影的评级,并计算出相应的MSE。该预测基于相似用户的评分。特别地,可以根据以下公式进行打分预测:
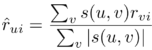
用户u对电影i的预测,是用户v对电影的评分的(标准化的)加权和。权重为用户u和v的相似度。
from sklearn.metrics import mean_squared_error
prediction = similarity_user.dot(train_matrix) / np.array([np.abs(similarity_user).sum(axis=1)]).T
prediction = prediction[test_matrix.nonzero()].flatten()
test_vector = test_matrix[test_matrix.nonzero()].flatten()
mse = mean_squared_error(prediction, test_vector)
print 'MSE = ' + str(mse)
预测的MSE为9.8252。这个数字意味着什么?这个推荐系统是好是坏?仅仅看着MSE结果来评估预测效果不是很符合直觉。因此,我们直接检查电影推荐来评估。我们将搜索一个感兴趣的电影,并让电脑代理来推荐几部电影。首先要得到相应的电影海报,这样就能看到都有什么电影被推荐。我们使用IMDB id,使用它的API从Movie Database 网站获取海报。
import requests
import json
from IPython.display import Image
from IPython.display import display
from IPython.display import HTML
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
idx_to_movie
k = 6
idx = 0
movies = [ idx_to_movie[x] for x in np.argsort(similarity_movie[idx,:])[:-k-1:-1] ]
movies = filter(lambda imdb: len(str(imdb)) == 6, movies)
n_display = 5
URL = [0]*n_display
IMDB = [0]*n_display
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
i += 1
images = ''
for i in range(n_display):
images += "
![]() float: left; border: 1px solid black;" src="%s"/>" \
float: left; border: 1px solid black;" src="%s"/>" \
% URL[i]
display(HTML(images))
好玩的来了!让我们来搜索一个电影并看看四个最相似的推荐。让我们试着搜索《盗火线》,在左手边第一个,后面是四部推荐的电影。

《盗火线》是1995年上映的一部美国犯罪电影,由罗伯特·德·尼罗、阿尔·帕西诺主演。搜索结果看起来不错。但《离开拉斯维加斯》可能不是一个好的建议,我猜原因是因为电影《勇闯夺命岛》里有尼古拉斯·凯奇,《The Rock》,以及对喜欢 《盗火线》的观众而言,它是一个不错的推荐。这可能是相似性矩阵和协同过滤的缺点之一。让我们试试更多的例子。

这个看起还好。《玩具总动员2》绝对是应该推荐给喜欢《玩具总动员》的观众。但是《阿甘正传》在我看来不合适。显然,因为汤姆·汉克斯的声音出现在《玩具总动员》里,所以《阿甘正传》也被推荐了。值得注意的是,我们可以只看一眼海报就分辨出《玩具总动员》与 《阿甘正传》的区别,比如电影类型、情绪等。假设每一个小孩都喜欢《玩具总动员》,他们可能会忽略《阿甘正传》。
交替随机梯度下降
在前面的讨论中,我们简单地计算了用户和电影的余弦相似度,并以此来预测用户对电影的评分,还根据某电影推荐其它电影。现在,我们可以把问题做为一个回归问题;对所有的电影加入潜在特征y,对所有用户加入权重向量x。目标是将评分预测的(在 2-norm 的正则化条件下)MSE最小化。
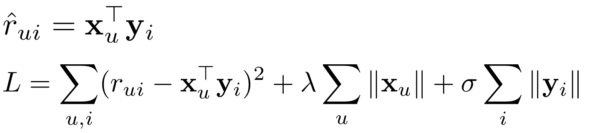
AI科技评论提醒:权重向量和特征向量都是决策变量。显然,这不是一个凸函数问题,现在也不需要过分担心I这个非凸函数的收敛性。有很多方法能解决非凸函数的优化问题。方法之一就是以交替方式()解决权重向量(对用户)和特征向量(对电影)。处理权重向量时,假设特征向量是常向量;处理特征向量时,假设权重向量是常向量。解决这个回归问题的另一种方法,是将权重向量与特征向量的更新结合起来,在同一个迭代中更新它们。另外,还可以借助随机梯度下降来加速计算。这里,我用随机梯度下降来解决这个回归问题,我们的MSE预测如下:
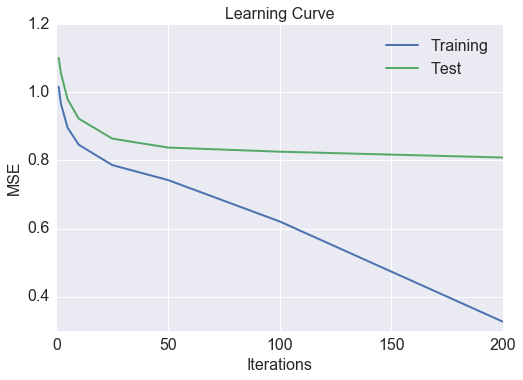
这个MSE比用相似性矩阵得到的,要小得多。当然,我们也可以使用网格搜索和交叉验证对模型、算法调参。再看看电影搜索的推荐:
 看起来并不是很好。我觉得这四部电影不应该通过搜索《盗火线》推荐给我,他们看起来与《盗火线》完全不相关,这四个电影是浪漫、戏剧类。如果我找的是一部有大明星的美国犯罪电影,我凭什么会想要看戏剧电影? 这让我很困惑——一个好的MSE的结果可能会给我们一个风马牛不相及的推荐。
看起来并不是很好。我觉得这四部电影不应该通过搜索《盗火线》推荐给我,他们看起来与《盗火线》完全不相关,这四个电影是浪漫、戏剧类。如果我找的是一部有大明星的美国犯罪电影,我凭什么会想要看戏剧电影? 这让我很困惑——一个好的MSE的结果可能会给我们一个风马牛不相及的推荐。
因此,我们讨论一下基于协同过滤的推荐系统的弱点。
接下来,我们将考虑采用另一种方法来处理协同过滤问题——用深度学习推荐电影。
深度学习
我们将在Keras中用VGG16来训练神经网络。我们的数据集中没有目标,只是将倒数第四层作为一个特征向量。我们用这个特征向量,来描述数据集中的每一个电影。
AI科技评论
提醒,在训练神经网络之前,还需要做一些预处理,训练过程如下。
df_id = pd.read_csv('links.csv', sep=',')
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
total_movies = 9000
movies = [0]*total_movies
for i in range(len(movies)):
if i in idx_to_movie.keys() and len(str(idx_to_movie[i])) == 6:
movies[i] = (idx_to_movie[i])
movies = filter(lambda imdb: imdb != 0, movies)
total_movies = len(movies)
URL = [0]*total_movies
IMDB = [0]*total_movies
URL_IMDB = {"url":[],"imdb":[]}
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
if URL[i] != base_url+"":
URL_IMDB["url"].append(URL[i])
URL_IMDB["imdb"].append(IMDB[i])
i += 1
# URL = filter(lambda url: url != base_url+"", URL)
df = pd.DataFrame(data=URL_IMDB)
total_movies = len(df)
import urllib
poster_path = "/Users/wannjiun/Desktop/nycdsa/project_5_recommender/posters/"
for i in range(total_movies):
urllib.urlretrieve(df.url[i], poster_path + str(i) + ".jpg")
from keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image as kimage
image = [0]*total_movies
x = [0]*total_movies
for i in range(total_movies):
image[i] = kimage.load_img(poster_path + str(i) + ".jpg", target_size=(224, 224))
x[i] = kimage.img_to_array(image[i])
x[i] = np.expand_dims(x[i], axis=0)
x[i] = preprocess_input(x[i])
model = VGG16(include_top=False, weights='imagenet')
prediction = [0]*total_movies
matrix_res = np.zeros([total_movies,25088])
for i in range(total_movies):
prediction[i] = model.predict(x[i]).ravel()
matrix_res[i,:] = prediction[i]
similarity_deep = matrix_res.dot(matrix_res.T)
norms = np.array([np.sqrt(np.diagonal(similarity_deep))])
similarity_deep = similarity_deep / norms / norms.T
在代码中,我们首先使用API和IMDB id,从TMDB网站获取电影海报。然后向VGG16提供海报来训练神经网络。最后,用VGG16学习的特征来计算余弦相似性。获得电影相似性之后,我们可以推荐相似度最高的电影。VGG16总共有25088个学来的特征,我们使用这些特征来描述数据集中的每个电影。
来看看使用深度学习的电影推荐系统。

《导火线》不再和爱情戏剧一起出现了!这些电影海报有一些相同的特点:深蓝色的、上面还有人物等等。让我们再来试试《玩具总动员》。

《阿甘正传》不会再被推荐了!结果看起来不错,朕心甚慰,再来试试别的!

注意,这些海报里都有一或两个人,并有冷色系的主题风格。

这些海报想让观众知道相应电影的氛围欢乐、紧张,并有很多动作镜头,所以海报的颜色也很强烈。

不同于上一组,这些海报想告诉观众:这些电影讲述的是一个单身汉。

我们找到的与《功夫熊猫》类似的电影。

这一组很有趣。一群相似的怪兽以及汤姆·克鲁斯!

所有这些海报里都有姿势类似的女士。等等,那个是奥尼尔!?

成功找到了蜘蛛侠!

这些海报的排版设计很接近。
结论
在推荐系统中有几种使用深度学习的方法:
-
无监督学习
-
从协同过滤中预测潜在特征
-
将深度学习生成的特征作为辅助信息
电影海报具有创造噱头和兴趣的视觉元素。这个项目中,我们使用了无监督深度学习,通过海报来学习电影的相似性。显然,这只是在推荐系统中使用深度学习的第一步,我们还可以尝试很多东西。例如,我们可以用深度学习来预测协同过滤生成的潜在特征。Spotify的音乐推荐也使用了类似的方法,区别于图像处理,他们通过处理歌曲的声音,来用深度学习来预测协同过滤中的潜在特征。还有一个可能的方向。是把深度学习学到的特征作为辅助信息,来提高预测的准确性。
AI科技评论
编译
“TensorFlow & 神经网络算法高级应用班”开课啦!

从初级到高级,理论+实战,一站式深度了解 TensorFlow!
本课程面向深度学习开发者,讲授如何利用 TensorFlow 解决图像识别、文本分析等具体问题。课程跨度为 10 周,将从 TensorFlow 的原理与基础实战技巧开始,一步步教授学员如何在 TensorFlow 上搭建 CNN、自编码、RNN、GAN 等模型,并最终掌握一整套基于 TensorFlow 做深度学习开发的专业技能。
两名授课老师佟达、白发川身为 ThoughtWorks 的资深技术专家,具有丰富的大数据平台搭建、深度学习系统开发项目经验。
时间:每周二、四晚 20:00-21:00
开课时长:总学时 20 小时,分 10 周完成,每周2次,每次 1 小时
线上授课地址:http://www.leiphone.com/special/custom/mooc04.html
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界、业界、开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就可以一起来记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*理工科或新闻相关专业优先,好钻研
*对人工智能有一定的兴趣或了解
* 态度好,学习能力强
简历投递:
深圳:[email protected]






