
该系列文章的目录(不完整版),本文为 Lecture 1 的内容。
深度前馈网络
我们从统计学出发,先很自然地定义一个函数 f,而数据样本由⟨Xi,f(Xi)⟩给出,其中 Xi 为典型的高维向量,f(Xi) 可取值为 {0,1} 或一个实数。我们的目标是找到一个最接近于描述给定数据的函数 f∗(不过拟合的情况下),因此其才能进行精准地预测。
在深度学习之中,总体上来说就是参数统计的一个子集,即有一族函数 f(X;θ),其中 X 为输入数据,θ为参数(典型的高阶矩阵)。而目标则是寻找一组最优参数θ∗,使得 f(X;θ∗) 最合适于描述给定的数据。
在前馈神经网络中,θ就是神经网络,而该网络由 d 个函数组成:
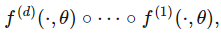
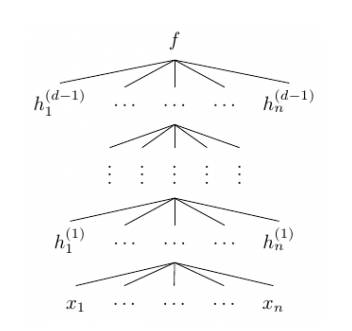
大部分神经网络都是高维的,因此其也可以通过以下结构图表达:
其中
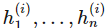 是向量值函数 f^(i) 的分量,即第 i 层神经网络的分量,每一个
是向量值函数 f^(i) 的分量,即第 i 层神经网络的分量,每一个
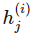 是
是
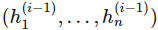 的函数。在上面的结构图中,每一层函数 f^(i) 的分量数也称为层级 i 的宽度,层级间的宽度可能是不一样的。我们称神经网络的层级数 d 为网络的深度。重要的是,第 d 层的神经网络和前面的网络是不一样的,其为输出层,在上面的结构图中,输出层的宽度为 1,即 f=f(d) 为一个标量值。通常统计学家最喜欢的是线性函数,但如果我们规定神经网络中的函数 f^(i) 为一个线性函数,那么总体的组合函数 f 也只能是一个线性函数,这样就完全不能拟合高维复杂数据。因此我们通常
使用非线性函数来
激活函数。
的函数。在上面的结构图中,每一层函数 f^(i) 的分量数也称为层级 i 的宽度,层级间的宽度可能是不一样的。我们称神经网络的层级数 d 为网络的深度。重要的是,第 d 层的神经网络和前面的网络是不一样的,其为输出层,在上面的结构图中,输出层的宽度为 1,即 f=f(d) 为一个标量值。通常统计学家最喜欢的是线性函数,但如果我们规定神经网络中的函数 f^(i) 为一个线性函数,那么总体的组合函数 f 也只能是一个线性函数,这样就完全不能拟合高维复杂数据。因此我们通常
使用非线性函数来
激活函数。
最常用的激活函数来自神经科学模型的启发,即每一个细胞接收到多种信号,但神经突触基于输入只能选择激活或不激活一个特定的电位。因为输入可以表征为
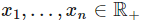 。
。
对于一些非线性函数 g,由样本激励的函数可以定义为:
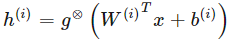
其中 g⊗ 定义了以线性函数为自变量的一个非线性函数。
通常我们希望函数 g 为非线性函数,并且还需要它能很方便地求导。因此我们一般使用 ReLU(线性整流单元)函数 g(z)=max(0,z)。其它类型的激活函数 g 还包括 logistic 函数:
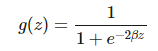 和双曲正切函数:
和双曲正切函数:
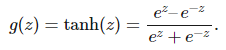 。
。
这两种激活函数相对 ReLU 的优点,即它们都是有界函数。
正如前面所说的,最后的输出层和前面的层级都不一样。首先它通常是标量值,其次它通常会有一些统计学解释:
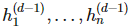 。
。
通常可以看作经典统计学模型的参数,且 d-1 层的输出构成了输出层激活函数的输入。输出层激活函数可以使用线性函数
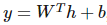 。
。
该线性函数将输出作为高斯分布的条件均值。其它也可以使用 σ(wTh+b),其中σ代表 Sigmoid 函数,即
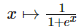
该 Sigmoid 函数将输出视为 P(y)为 exp(yz) 的伯努利试验,其中
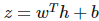 。
。
更广义的 soft-max 函数可以给定为:
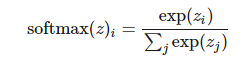
其中
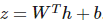 。
。
现在,z 的分量和可能的输出值相对应,softmax(z)i 代表输出值 i 的概率。例如输入图像到神经网络,而输出(softmax(z)1,softmax(z)2,softmax(z)1)则可以解释为不同类别(如猫、狗、狼)的概率。
卷积网络
卷积网络是一种带有线性算符的神经网络,即采用一些隐藏的几何矩阵作为局部卷积算符。例如,第 k 层神经网络可以用 m*m 阶矩阵表达:
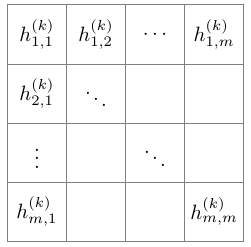
我们定义 k+1 层的函数
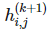 可以由 2*2 矩阵在前一层神经网络执行卷积而得出,然后再应用非线性函数 g:
可以由 2*2 矩阵在前一层神经网络执行卷积而得出,然后再应用非线性函数 g:
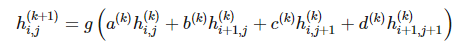
参数 a(k)、b(k)、c(k) 和 d(k) 只取决于不同层级滤波器的设定,而不取决于特定的元素 i,j。虽然该约束条件在广义定义下并不必要,但在一些如机器视觉之类的应用上还是很合理的。除了有利于参数的共享,这种类型的网络因为函数 h 的定义而自然呈现出一种稀疏的优良特征。
卷积神经网络中的另一个通用的部分是池化操作。在执行完卷积并在矩阵索引函数
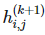 上应用了 g 之后,我们可以用周围函数的均值或最大值替代当前的函数。即设定:
上应用了 g 之后,我们可以用周围函数的均值或最大值替代当前的函数。即设定:
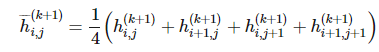
这一技术同时可以应用到降维操作中。
模型和优化
下面我们需要了解如何求得神经网络参数,即到底我们该采取什么样的 θ 和怎么样评估θ。对此,我们通常使用概率建模的方法。即神经网络的参数θ决定了一个概率分布 P(θ),而我们希望求得 θ 而使条件概率 Pθ(y|x) 达到极大值。即等价于极小化函数:
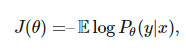
其中可以用期望取代对数似然函数。例如,如果我们将 y 拟合为一个高斯分布,其均值为 f(x;θ),且带有单位协方差矩阵。然后我们就能最小化平均误差:
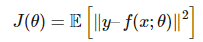
那么现在我们该怎样最优化损失函数 J 以取得最优秀的性能。首先我们要知道最优化的困难主要有四个方面:
-
过高的数据和特征维度
-
数据集太大
-
损失函数 J 是非凸函数
-
参数的数量太多(过拟合)
面对这些挑战,自然的方案是采用梯度下降。而对于我们的深度神经网络,比较好的方法是采用基于链式求导法则的反向传播方法,该方法动态规划地求偏导数以降误差反向传播来更新权重。
另外还有一个十分重要的技术,即正则化。正则化能解决模型过拟合的问题,即通常我们对每一个特征采取一个罚项而防止模型过拟合。卷积神经网络通过参数共享提供了一个方案以解决过拟合问题。而正则化提供了另一个解决方案,我们不再最优化 J(θ),而是最优化 J(θ)=J(θ)+Ω(θ)。
其中Ω是「复杂度度量」。本质上Ω对「复杂特征」或「巨量参数」引入了罚项。一些Ω正则项可以使用 L2 或 L1,也可以使用为凸函数的 L0。在深度学习中,还有其他一些方法解决过拟合问题。其一是数据增强,即利用现有的数据生成更多的数据。例如给定一张相片,我们可以对这张相片进行剪裁、变形和旋转等操作生成更多的数据。另外就是噪声,即对数据或参数添加一些噪声而生成新的数据。
生成模型:深度玻尔兹曼机
深度学习应用了许多概率模型。我们第一个描述的是一种图模型。图模型是一种用加权的图表示概率分布的模型,每条边用概率度量结点间的相关性或因果性。因为这种深度网络是在每条边加权了概率的图,所以我们很自然地表达为图模型。深度玻尔兹曼机是一种联合分布用指数函数表达的图模型:
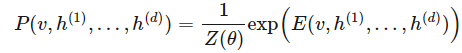
其中配置的能量 E 由以下表达式给出:

一般来说,中间层级为实数值向量,而顶部和底部层级为离散值或实数值。
波尔兹曼机的图模型是典型的二分图,对应于每一层的顶点只直接连接在其顶部和底部的层级。
这种马尔可夫性质意味着在 h1 条件下,v 分量的分布是和 h2,…,hd 还有 v 的其他分量相互独立的。如果 v 是离散的:
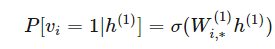
其他条件概率也是相同的道理。
不幸的是,我们并不知道如何在图模型中抽样或优化,这也就极大地限制了玻尔兹曼机在深度学习中的应用。
深度信念网络
深度信念网络在计算上更为简洁,尽管它的定义比较复杂。这些「混合」的网络在本质上是一个具有 d 层的有向图模型,但是它的前两层是无向的:P(h(d−1),h(d)) 定义为
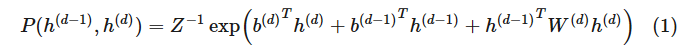
对于其它层

注意到这里与之前的方向相反。但是,该隐变量满足以下条件:如果

由公式(1)定义,则它们也满足公式(2)。
我们知道怎样通过上面的公式直接对基于其它条件层的底层进行抽样;但是要进行推断,我们还需要给定输入下输出的条件分布。
最后,我们强调,尽管深度玻尔兹曼机的第 k 层取决于 k+1 层和 k-1 层,在深度信念网络,如果我们只条件基于 k+1 层,我们可以准确地生成第 k 层(不需要条件基于其它层)。
课程计划
在本课程中,我们主要的讨论主题为:
第一个主题强调神经网络的表现力:可以被网络近似的函数类型有哪些?我们计划讨论的论文有:
-
Cybenko 的「迭加激活函数的近似」(89)。
-
Hornik 的「多层前馈网络的近似能力」(91)。
-
Telgarsky 的「深度向前网络的表征优势」(15)。
-
Safran 和 Shamir 的「Relu 网络的深度分离」(16)。
-
Cohen、Or 和 Shashua 的「关于深度学习的表现力:张量分析」(15)。
前两篇论文(我们将在后面的课程中详细阐述)证明了「你可以仅用单一层表达任何事物」的思想。但是,后面几篇论文表明此单一层必须非常宽,我们将在后面侧面展示这种论点。
关于第二个主题,我们在本课程中讨论的关于复杂度结果的内容可能包括:
-
Livni、Shalev Schwartz 和 Shamir 的「关于训练神经网络的计算效率」(14)。
-
Danieli 和 Shalev-Schwartz 的「学习 DNF 的复杂度理论限制」(16)。
-
Shamir 的「特定分布的学习神经网络复杂度」(16)。
在算法方面:
最后,我们将阅读的关于生成模型的论文包括:
今天我们将开始研究关于第一个主题的前两篇论文:Cybenko 和 Hornik 的论文。
Cybenko 和 Hornik 的理论
在 1989 年的论文中,Cybenko 证明了以下结论:
[Cybenko (89)] 令 σ 为一个连续函数,且极限 limt→–∞σ(t)=0 和 limt→+∞σ(t)=1。(例如,σ 可以为激活函数且 σ(t)=1/(1+e−t)),然后,f(x)=∑αjσ(wTjx+bj) 形式的函数族在 Cn([0,1]) 中是稠密的。
其中,Cn([0,1])=C([0,1]n) 是从 [0,1]n 到 [0,1] 的连续函数空间,它有 d(f,g)=sup|f(x)−g(x)|。
Hornik 证明了下面的 Cybenko 的衍生结论:
[Hornik (91)] 考虑上面定理定义的函数族,但是 σ 没有条件限制。
如果 σ 有界且非连续,那么函数族在 Lp(μ) 空间是稠密的,其中 μ 是任意在 Rk 上的有限测度。










