Udacity 无人驾驶车工程师纳米学位(Nanodegree)系列计划第三个项目
项目地址:https://github.com/upul/behavioral_cloning
行为克隆:模拟(人类)驾驶汽车
概述
本项目的目标是使用一个深度神经网络来模拟人类的驾驶行为。为了达成这个目标,我们会使用一个简单的汽车模拟器。在训练阶段,我们使用键盘在模拟器内对我们的车进行导航。当我们驾驶汽车时,模拟器会记录训练图像和相应的转向角度。然后我们使用这些记录的数据来训练我们的神经网络。训练模型会在两个轨道上进行测试,即训练轨道和验证轨道。
依赖包
此项目需要安装 Python 3.5 和以下 Python 库:
Keras:https://keras.io/
NumPy:http://www.numpy.org/
SciPy:https://www.scipy.org/
TensorFlow:http://tensorflow.org/
Pandas:http://pandas.pydata.org/
OpenCV:http://opencv.org/
Matplotlib (可选):http://matplotlib.org/
Jupyter (可选):http://jupyter.org/
在终端提示符处运行此命令安装 OpenCV。适用于图像处理:
conda install -c https://conda.anaconda.org/menpo opencv3
如何运行模型
此资源库包含了已经进行训练好的模型,你可以使用以下命令直接测试。
python drive.py model.json
实现
获取数据
在训练期间,模拟器以 10Hz 的频率来获取数据。此外,在给定的时间间隔内,它将依次记录左、中和右部的摄像机拍摄的三个图像。下图显示了我在训练期间收集的示例。
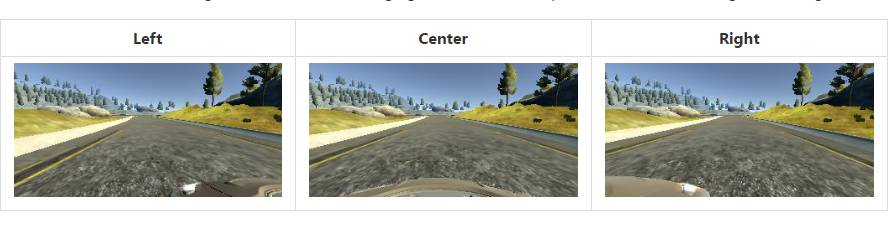
收集到的数据在传送给深度神经网络之前会被预处理,相应的预处理步骤将在本文的后半部分描述。
数据集统计
该数据集包含 24108 张图像(每个方向的摄像机拍摄了 8036 张图像)。训练轨道包含许多缓弯和直线路段。因此,记录中的大多数转向角都是零。所以,对图像和相应的转向角度进行预处理非常必要的,以便将此训练模型推广到那些未经训练的路线(例如我们的验证轨道)。
接下来,我们将解释我们的数据处理流程(data processing pipeline)。
数据处理流程
下图显示了我们的数据预处理流程。
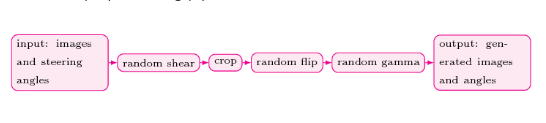
当处于流程中的第一个阶段时,我们会应用随机剪切操作。然而,我们只选择了 90% 的图像来进行随机剪切过程,保留了 10% 的原始图像和转向角,以帮助汽车在训练轨道中导航。下图显示了样本图像剪切操作的结果。

模拟器捕获的图像有很多细节,它们对于模型构建过程没有直接的帮助。这些细节除了会占用的额外空间还需要额外的处理资源。因此,我们从保留的那 10% 的图像的起始处开始删除了 35% 的原始图像。这个过程在修剪阶段(crop stage)完成。下图显示了图像的裁剪操作的结果。

数据处理流程的下一阶段被称为随机反转阶段(random flip stage)。在这个阶段,我们会随机(概率设定为 0.5)翻转图像。这样做的原因是因为是训练轨道中的左弯曲比右弯曲更普遍。因此,为了增加我们的模型的泛化性,我们采取了翻转图像和相应的转向角的方案。下图显示图像的翻转操作的结果。

在流程的最后阶段,为了减少训练的时间,我们将图像大小调整为 64×64。样本调整大小的图像如下图所示。进行调整过后的图像传送给神经网络。下图显示了图像的调整大小操作的结果。

接下来我们将讨论我们的神经网络架构。
网络架构
我们设计卷积神经网络架构的灵感来自于 NVIDIA 的论文《用于自动驾驶汽车的端到端学习(End to End Learning for Self-Driving Cars)》。我们的模型和 NVIDIA 的模型的主要区别是我们在每个卷积层之后又使用了最大池化(MaxPooling)层来减少训练时间。有关我们的网络架构的更多详细信息,请参见下图。
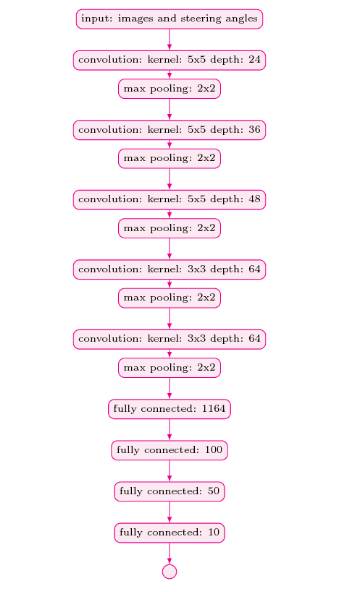
训练
即使在对训练图像进行裁剪和调整(所有图像都进行了增强)之后,训练数据集还是非常大,所以不能将它们完全存于主存。因此,我们使用 Keras 库的 fit_generator API 来训练我们的模型。
我们创建了两个生成器(generator),即:
train_gen 和 validation_gen 的批量规模是 64。我们在每个训练阶段使用 20032 张图像。应当注意,我们现在所说的图像是经过上文中所提及数据处理管道处理后生成的。除此之外,我们还使用 6400 张图片(同样也是数据处理管道处理过后的)进行验证。我们使用 Adam 优化器和 1e-4 的学习速率。最后,当涉及到选择训练代数(training epoch)值的时候,我们尝试了几种不同的数据,如 5、8、10、25 和 50。然而,我们发现 8 在训练和验证轨道上的效果都很好。
结果
在项目的初始阶段,我使用了我自己生成的数据集。该数据集很小,并且是使用笔记本电脑键盘在导航汽车时记录的。然而,使用该数据集构建的模型不足以在模拟器中自主导航汽车。后来我使用了 Udacity 发布的数据集。使用该数据集开发的模型(在增强数据的帮助下)在两个轨道上的工作情况都很好,如以下视频所示。
训练轨道
验证轨道
总结和未来的方向
在这个项目中,我们对自动驾驶汽车上下文中的回归问题进行了研究。在初始阶段,我们主要致力于寻找合适的网络架构,并使用我们自己的数据集训练模型。根据均方误差(MSE)显示,我们的模型运行良好。然而,当我们使用模拟器测试模型时,它没有像预期的那样执行。因此,这清楚地表明了,MSE 不是一个评估该项目的性能的优质的指标。
在项目的下一阶段中,我们开始使用一个新的数据集(实际上,它是由 Udacity 发布的数据集)。同时,在构建我们的最终模型时,我们没有完全依赖于 MSE。此外,我们使用相对较少的训练代数(即 8 个阶段)。数据扩增和新的数据集的工作效果令人惊讶,我们的最终模型在了两个轨道上都表现出了出色的性能。
当谈到一些延伸的事情和未来的方向时,我想强调以下几点:
在真实的道路条件下训练模型。为此,我们可能需要找到一个新的模拟器。
尝试其他可能的数据增强技术(data augmentation technique)。
当我们驾驶汽车时,我们的一系列行为比如改变方向盘的角度和踩刹车不仅仅基于即时的驾驶决策。事实上,驾驶决策是基于当前的交通/道路状况在短暂的几秒钟发生的。因此,使用循环神经网络(RNN)模型(如 LSTM 和 GRU)来执行这个问题会非常有趣。
最后,训练(深度)强化代理(reinforcement agent)也将是一个有趣的附加项目。
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









