
数据挖掘入门与实战 公众号: datadw
这次主要总结搜过语料库的获取,因为老师要求20万数据,而我自己只爬了2万多,所以用到了搜狗的语料库.
回复公众号“搜狗”获取下载链接。

在这个页面中,我选择的是一个月的数据,别小看一个月,我从里面只用了24万,这24万可能在这一个月里都不算什么........做个实验还是很够用的。
下载下来是这个样子......
其中每个txt文本是这个样子.....
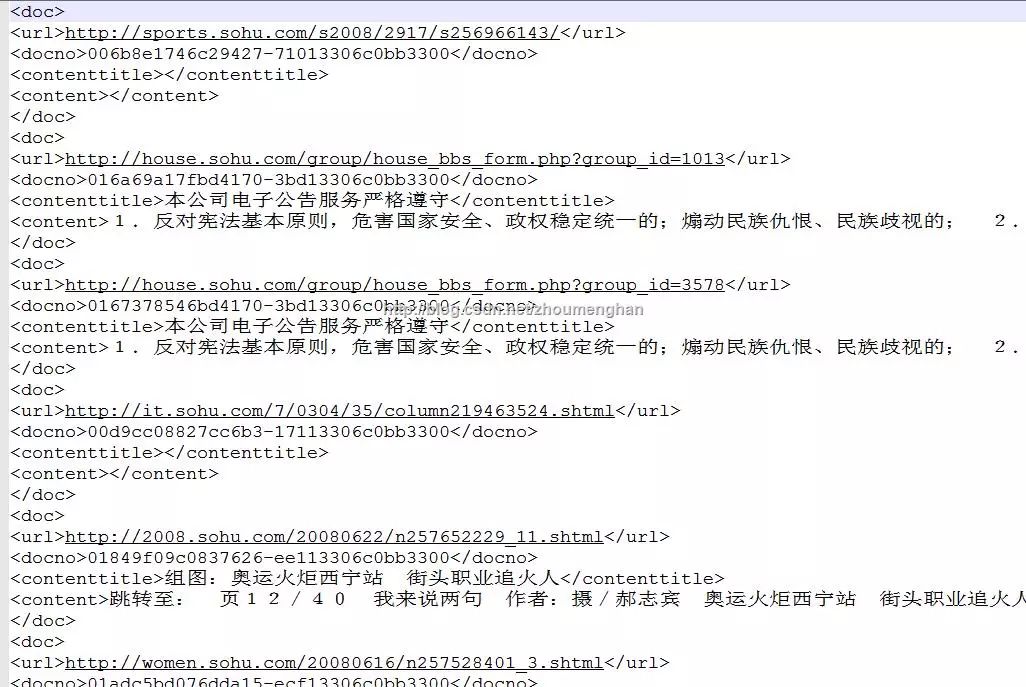
很明显,是xml格式,但是这一个txt里就包含了很多doc文档的内容,怎样把这些文档一篇篇提取出来,并且分到不同的类别去呢??这就需要接下来的处理。
首先,我们知道,像上文这样的txt的xml格式是无法解析的,因为不完整,缺啥?
但是!我们不可能一个txt一个txt的手工加吧(有128个txt),还是需要遍历一下用程序加的。Python用提供了一个解析xml很好用的minidom.parse函数,这个函数的用法比较简单,可以通过root.getElementsByTagName()来获取xml中需要的部分(可以查下这个函数的用法,比较好理解),这里我获取的是url和content,获取url的目的是为了获取域名,这样就可以根据域名来判断这篇文章属于什么类别里啦~对了,忘
了说一点,这样做运行时会出现bug,问题是因为有的url中出现了无法解析的&,所以在给每个txt加的同时,别忘了把出现的&替换成&;这样就能正常解析了。
程序如下:
[python]
import os
from xml.dom import minidom
from urlparse import urlparse
import codecs
def file_fill(file_dir):
for root, dirs, files in os.walk(file_dir):
for f in files:
tmp_dir = '.\sougou_after2' + '\\' + f
text_init_dir = file_dir + '\\' + f
file_source = open(text_init_dir, 'r')
ok_file = open(tmp_dir, 'a+')
start = '\n'
end = ''
line_content = file_source.readlines()
ok_file.write(start)
for lines in line_content:
text = lines.replace('&', '&')
ok_file.write(text)
ok_file.write(end)
file_source.close()
ok_file.close()
def file_read(file_dir):
for root, dirs, files in os.walk(file_dir):
for f in files:
print f
doc = minidom.parse(file_dir + "\\" + f)
root = doc.documentElement
claimtext = root.getElementsByTagName("content")
claimurl = root.getElementsByTagName("url")
for index in range(0, len(claimurl)):
if (claimtext[index].firstChild == None):
continue
url = urlparse(claimurl[index].firstChild.data)
if dicurl.has_key(url.hostname):
if not os.path.exists(path + dicurl[url.hostname]):
os.makedirs(path + dicurl[url.hostname])
fp_in = file(path + dicurl[url.hostname] + "\%d.txt" % (len(os.listdir(path + dicurl[url.hostname])) + 1),"w")
fp_in.write((claimtext[index].firstChild.data).encode('utf8'))
if __name__=="__main__":
path = ".\sougou_all\\"
dicurl = {'auto.sohu.com':'qiche','it.sohu.com':'hulianwang','health.sohu.com':'jiankang',\
'sports.sohu.com':'tiyu','travel.sohu.com':'lvyou','learning.sohu.com':'jiaoyu',\
'career.sohu.com':'zhaopin','cul.sohu.com':'wenhua','mil.news.sohu.com':'junshi',\
'house.sohu.com':'fangchan','yule.sohu.com':'yule','women.sohu.com':'shishang',\
'media.sohu.com':'chuanmei','gongyi.sohu.com':'gongyi','2008.sohu.com':'aoyun', \
'business.sohu.com': 'shangye'}
file_read(".\sougou_after2")
说明一下几个目录:
sougou_before2:存放原始的txt
sougou_after2:存放加上且处理了&的txt
sougou_all:存放分好类的文档们
sougou_all的目录结构如下:这样就得到了文本分类所需要的数据集
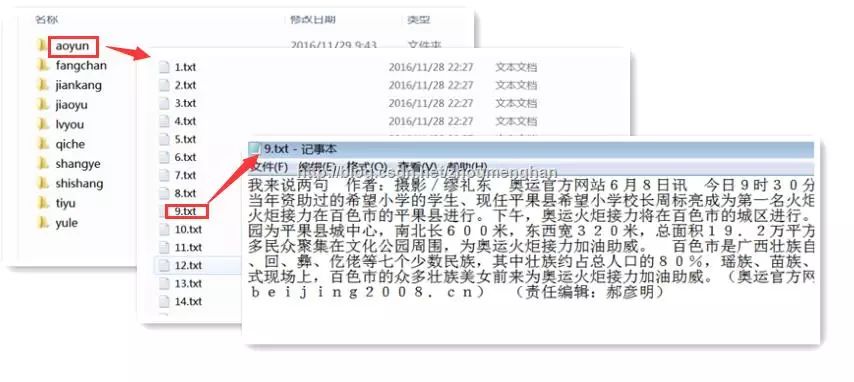
这样,我得到了10个分类,供24万多篇文章。(其实我只用到了96个txt,如果用整个的128个txt的话,感觉会有将近50万篇文章吧)
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注









