公众号ID
|
计算机视觉研究院
学习群
|
扫码在主页获取加入方式
源码下载
| 回复“
FT
”获取源码
论文:
https://arxiv.org/pdf/2103.14803.pdf
Column of Computer Vision Institute
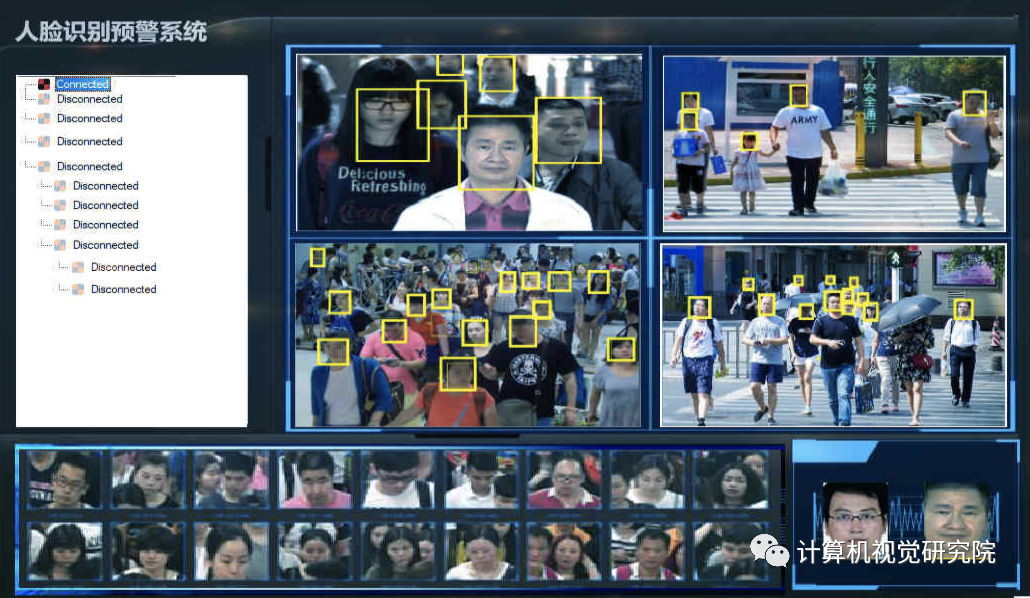
现阶段的人脸检测识别技术已经特别成熟,不管在什么领域都有特别成熟的应用,比如:无人超市、车站检测、犯人抓捕以及行迹追踪等应用。但是,
大多数应用都是基于大量数据的基础
,成本还是非常昂贵。所以人脸识别的精度还是需要进一步提升,那就要继续优化更好的人脸识别框架。
相比于卷积,Transformer有什么区别,优势在哪?
-
卷积有很强的归纳偏见(例如局部连接性和平移不变性),虽然对于一些比较小的训练集来说,这毫无疑问是有效的,但是当我们有了非常充足的数据集时,这些会限制模型的表达能力。与CNN相比,Transformer的归纳偏见更少,这使得他们能够表达的范围更广,从而更加适用于非常大的数据集;
-
卷积核是专门设计用来捕捉局部的时空信息,它们不能够对感受野之外的依赖性进行建模。虽然将卷积进行堆叠,加深网络会扩大感受野,但是这些策略通过聚集很短范围内的信息的方式,仍然会限制长期以来的建模。与之相反,自注意力机制通过直接比较在所有时空位置上的特征,可以被用来捕捉局部和全局的长范围内的依赖;
-
当应用于高清的长视频时,训练深度CNN网络非常耗费计算资源。目前有研究发现,在静止图像的领域中,Transformer训练和推导要比CNN更快。使得能够使用相同的计算资源来训练拟合能力更强的网络。
最近,人们不仅对
Transformer
的NLP,而且对计算机视觉也越来越感兴趣。我们想知道
Transformer
是否可以用于人脸识别,以及它是否比cnns更好。
因此,有研究者研究了
Transformer
模型在人脸识别中的性能。考虑到原始
Transformer
可能忽略inter-patch信息,研究者修改了patch生成过程,使相互重叠的滑动块成为标识。这些模型在CASIA-WebFace和MSSeleb-1M数据库上进行训练,并在几个主流基准上进行评估,包括LFW、SLLFW、CALFW、CPLFW、TALFW、CFP-FP、AGEDB和IJB-C数据库。研究者证明了在大规模数据库MS-Celeb-1M上训练的人脸
Transformer
模型实现了与CNN具有参数和MACs相似数量的CNN相似的性能。
二、FACE TRANSFORMER
2.1 网络框架爱
人脸Transformer模型采用ViT[
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai,
T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al.,
“An image is worth 16x16 words: Transformers for image recognition
at scale,” arXiv preprint arXiv:2010.11929
]体系结构,采用原
Transformer
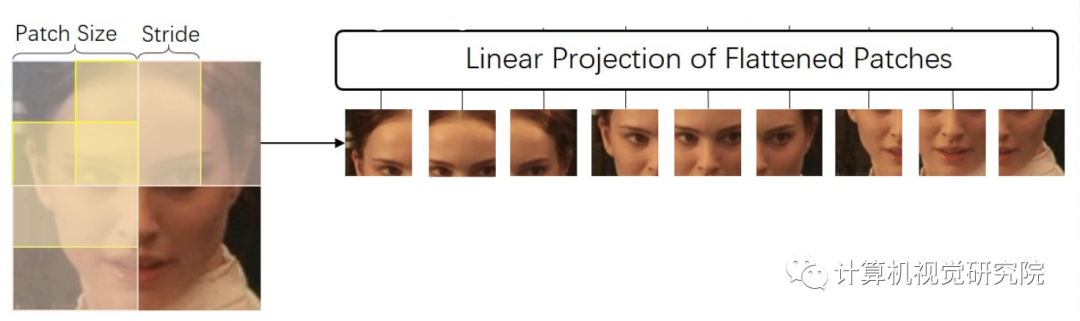
。唯一的区别是,研究者修改了ViT的标记生成方法,以生成具有滑动块的标记,即使图像块重叠,以便更好地描述块间信息,如下图所示。
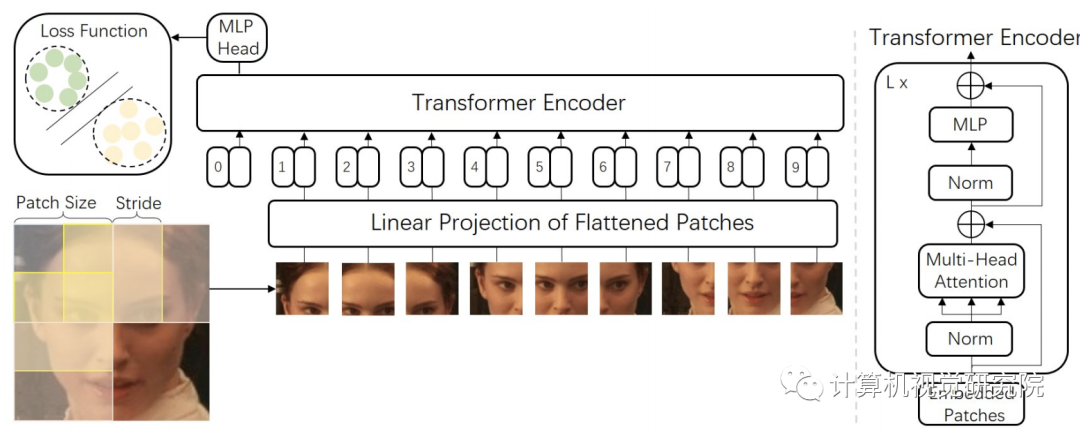
具体地说,从图像𝑿中提取滑动块,块大小为𝑃和步幅𝑆(输入两侧隐式为零),最后得到一系列扁平的二维块𝑿𝒑。(𝑊,𝑊)是原始图像的分辨率,而(𝑃,𝑃)是每个图像块的分辨率。
正如ViT所做的那样,可训练的线性投影将扁平块𝑿𝒑映射到model dimension D,并输出块嵌入𝑿𝒑𝑬。类标记,即一个可学习的嵌入(𝑿𝑐𝑙𝑎𝑠𝑠=𝒛)连接到块嵌入上,它在
Transformer
编码器(𝒛)输出处的状态是最终的人脸图像嵌入,如下方程式。
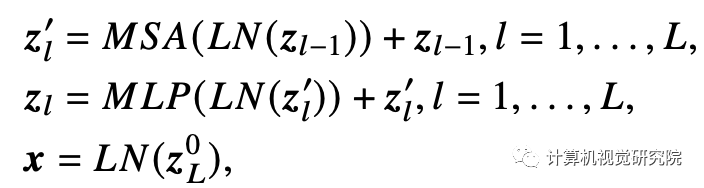
然后,将位置嵌入添加到块嵌入中,以保留位置信息。
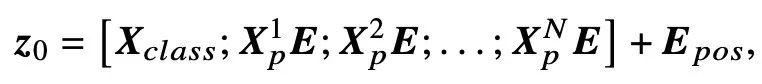
Trans
former
的关键模块MSA由𝑘并行自检(self-attention,SA)组成:
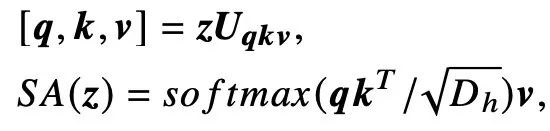
MSA的输出是𝑘注意头输出的连接
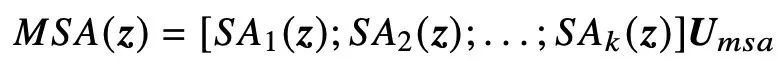
2.2 Loss Function
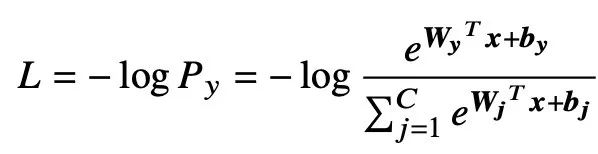
基于Softmax的损失函数消除了偏置项,并转换了𝑾𝒙=𝑠cos𝜃𝑗,并在cos𝜃𝑦𝑖项,[
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular
margin loss for deep face recognition,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
]中加入了large margin。因此,基于Softmax的损失函数可以表示为:
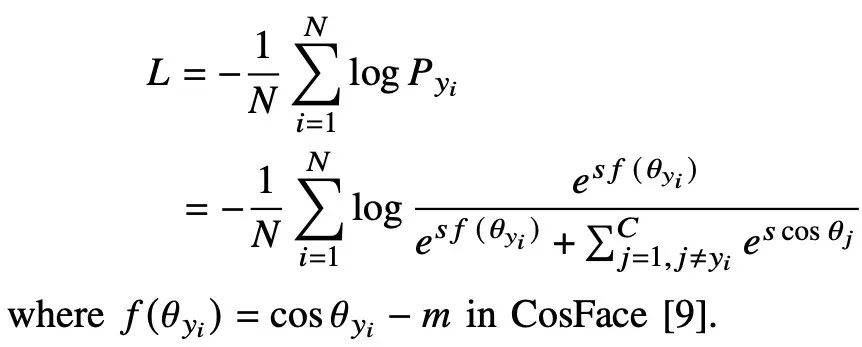
[9]
H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and
W. Liu, “Cosface: Large margin cosine loss for deep face recognition,”
in Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition
三、实验及可视化
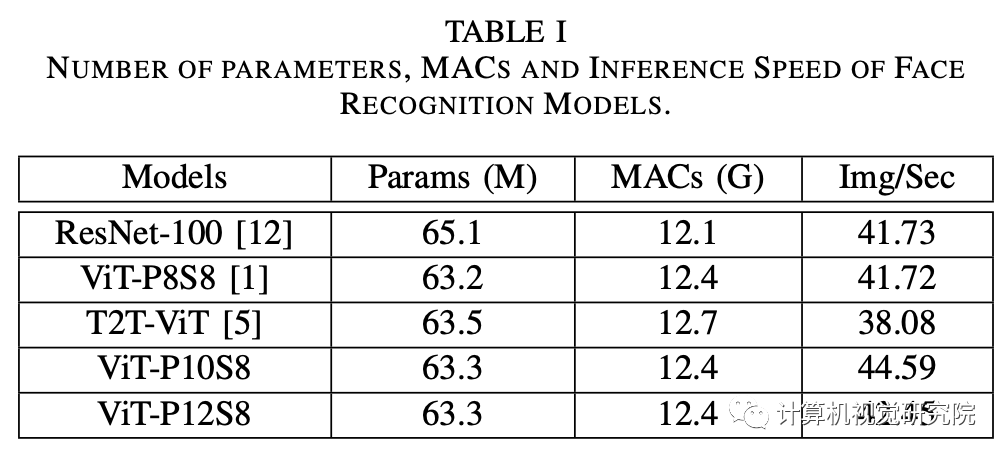
对于ViT
模型,层数是20个,头数是8个,
hidden大小为512,MLP大小为2048。
从
T2T-ViT模型
中一部分——Token-to-Token
,深度为2,
hidden
为64,
MLP大小为512;
而对于主干网络,层数
是24,头数为8
,
hidden
大小为512,MLP大小
是2048。
请注意,“ViT-P10S8”代表ViT模型
具有10×10patch尺寸,步幅𝑆=8和“ViT-P8S8”
表示标记之间没有重叠。

在Attention Rollout技术的帮助下,研究者分析了
Trans
fo
rmer
模型(MS-Celeb-1M,ViT-P12S8)如何专注于人脸图像,并发现人脸
Trans
fo
rmer
模型如何像预期的那样关注人脸区域。
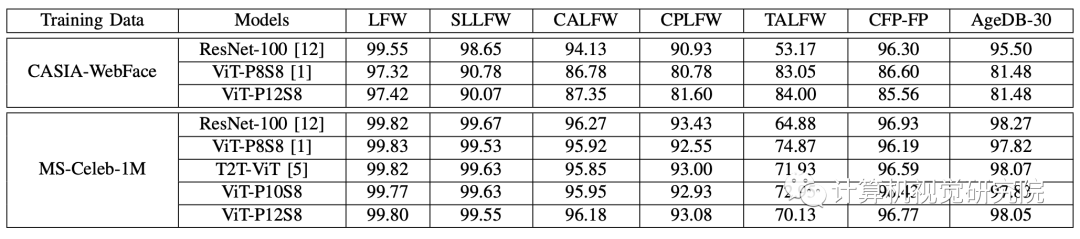
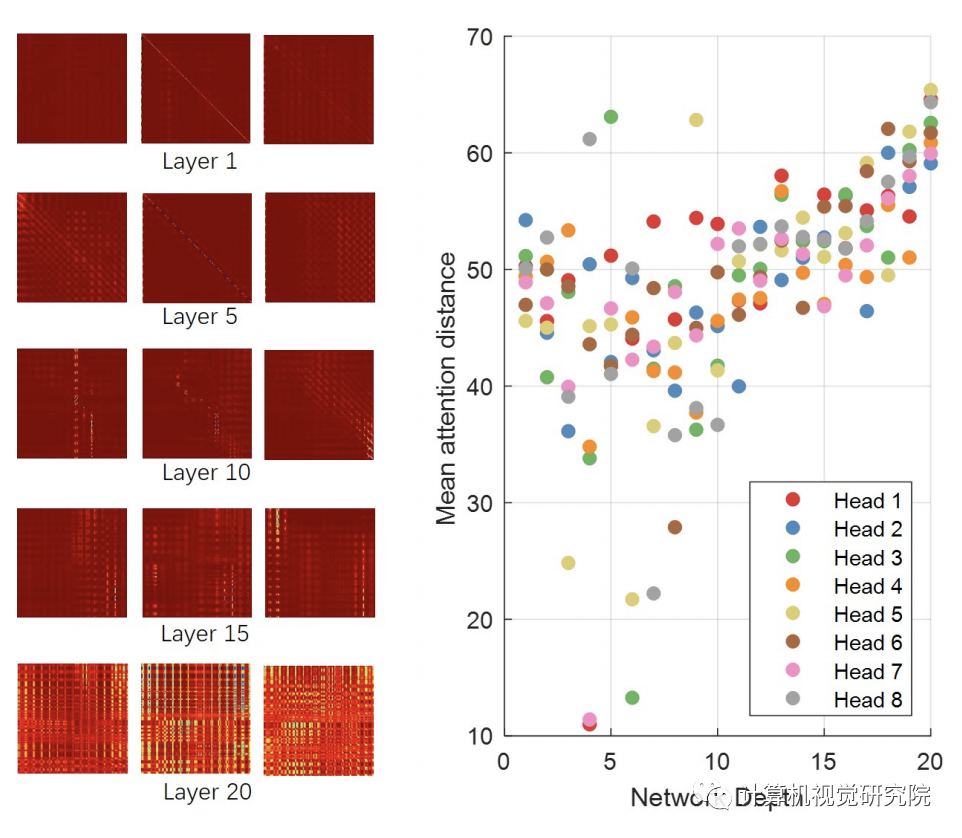
(1)不同层次的注意矩阵的可视化。(2)是指基于头部和网络深度的参与区域的注意距离。
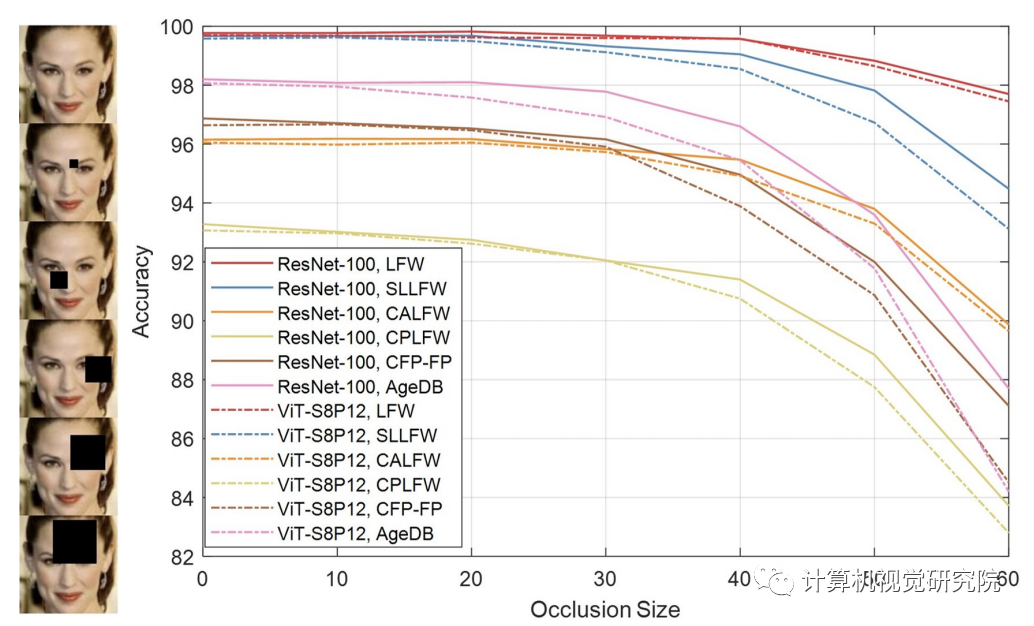
随着
遮挡面积的增加
,人脸
Transformer
模型和ResNet100的识别性能得到了提高。
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!











