2016 年 8 月,香港浸会大学褚晓文团队的研究者发表了一篇论文,对业界主流深度学习工具进行了基准评测 ,之前机器之心也报道了
该论文的第六版更新
(把 MXNet 加入了评估对象内)。近日,该论文又放出了第七版更新,此次更新修正了 MXNet 中的 ResNet-50 配置;增加了在 TensorFlow 中多 GPU 更快速的实现 ResNet-56。读者可点击阅读原文下载此论文。
摘要
深度学习已被证明是一种可成功用于许多任务的机器学习方法,而且它的广泛流行也将很多开源的深度学习软件工具开放给了公众。训练一个深度网络往往是一个非常耗时的过程。为了解决深度学习中巨大的计算难题,许多工具利用了多核 CPU 和超多核 GPU 这样的硬件特性来缩短训练时间。但是,在不同的硬件平台上训练不同类型的深度网络时,不同的工具会有不同的特性和运行性能,这让终端用户难以选择出合适的软件和硬件搭配。在这篇论文中,我们的目标是对当前最先进的 GPU 加速的深度学习软件工具(包括:Caffe、CNTK、MXNet、TensorFlow 和 Torch)进行比较研究。我们在两种 CPU 平台和三种 GPU 平台上使用三种流行的神经网络来评测了这些工具的运行性能。我们做出了两方面的贡献。第一,对于深度学习终端用户,我们的基准评测结果可用于指导合适的软件工具和硬件平台的选择。第二,对于深度学习软件开发者,我们的深度分析为进一步优化训练的性能指出了可能的方向。
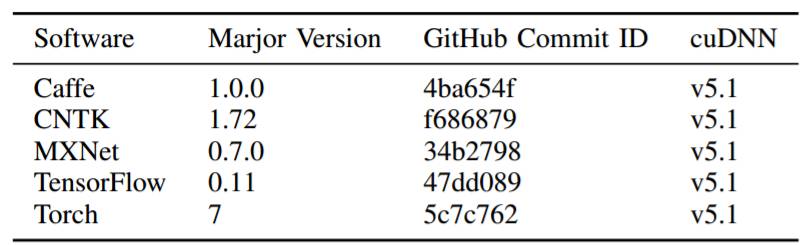
1 评测软件版本
2 评测中的神经网络设置

-
全连接网络
-
卷积神经网络: AlexNet、ResNet
-
循环神经网络
3 评测硬件配置

评测硬件配置——并行数据

4 实验概览及结果
下表给出了不同的网络、框架和硬件组合下进行的实验:
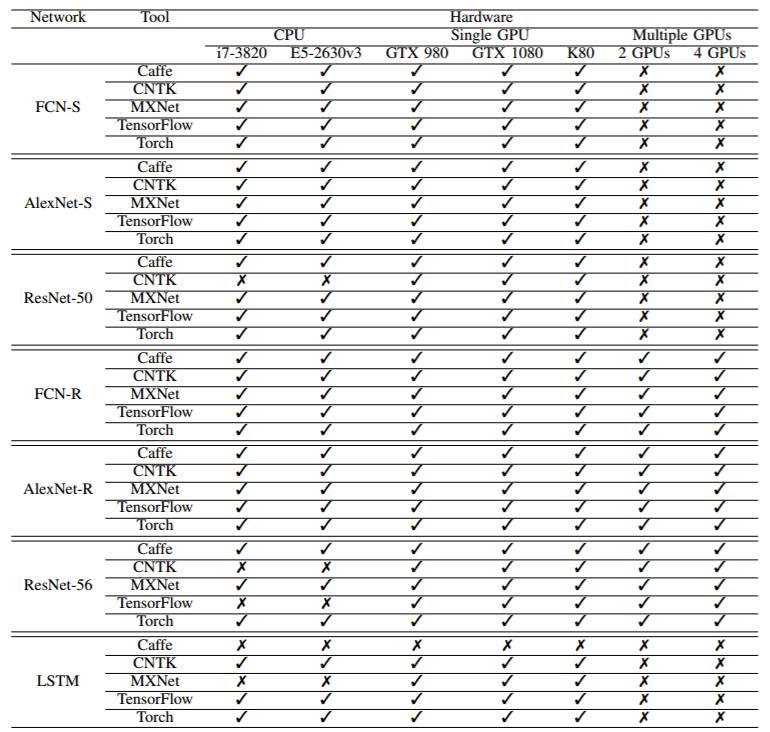
实验结果概览
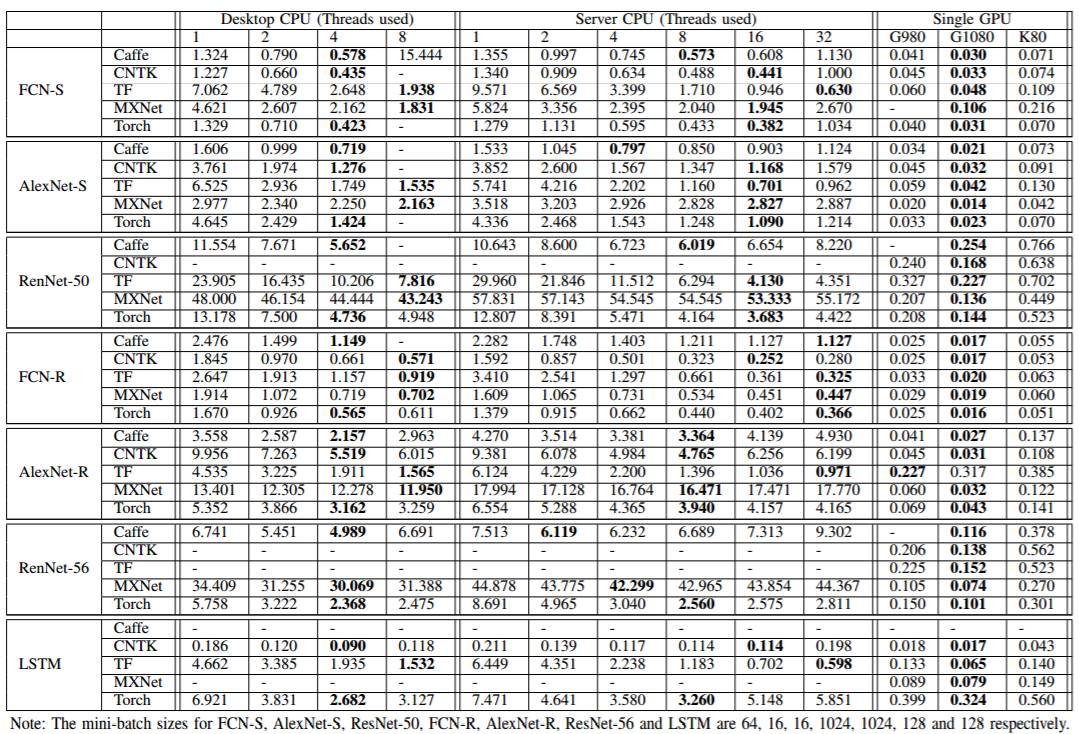
下表给出了实验结果比较数据,更清晰的结果可在上文给出的地址查看。这里给出的数据是实验的速度比较,比较了每个 mini-batch 处理所需的时间(单位:秒):
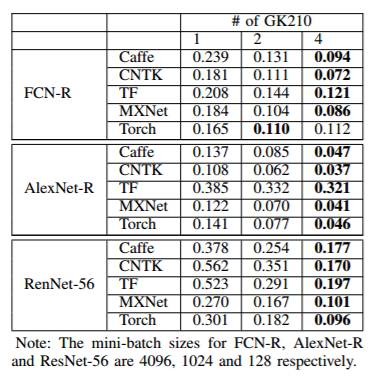
下表给出了在单个 GPU 和多个 GPU 上的实验比较数据,比较了每个 mini-batch 处理所需的时间(单位:秒):
4.1. CPU 评测结果
根据我们之前的研究 [31],在 CPU 平台上测试特定的 mini-batch 大小 d 的实验能够获得最好的运行时间表现。不同网络使用的 mini-batch 的大小在表 9 中有展示:
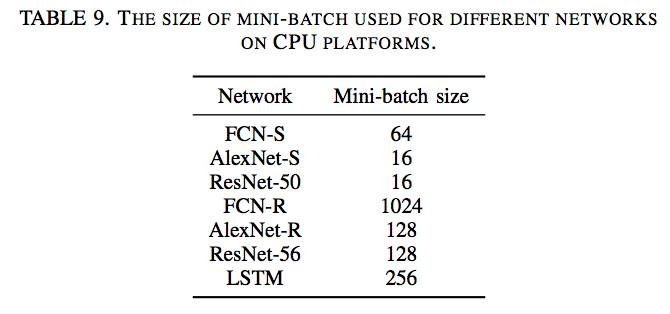
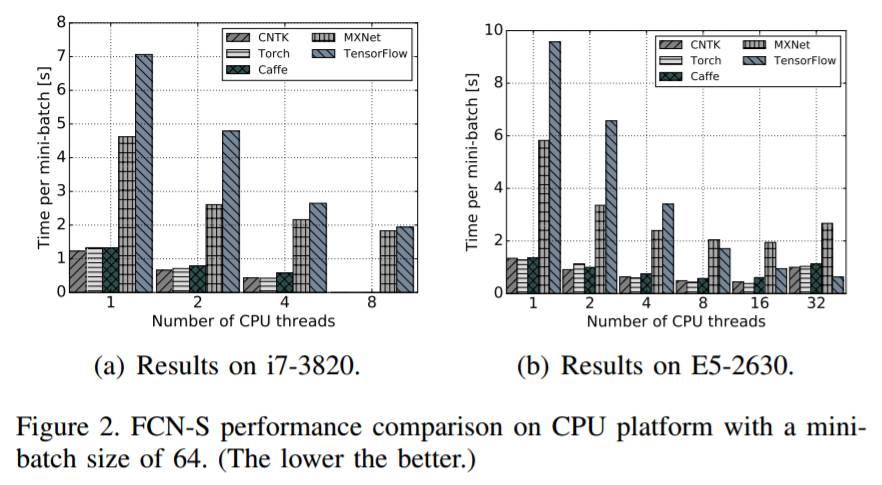
图 2:FCN-S 在 mini-batch 大小为 64 时在 CPU 平台上的表现的比较(越低越好)
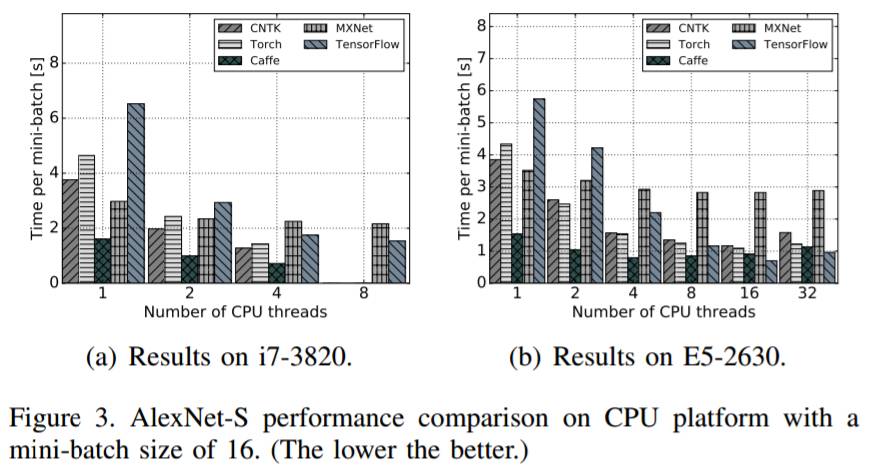
图 3:AlexNet-S 在 mini-batch 大小为 16 时在 CPU 平台上的表现的比较(越低越好)

图 4:ResNet-50 在 mini-batch 大小为 16 时在 CPU 平台上的表现的比较(越低越好)
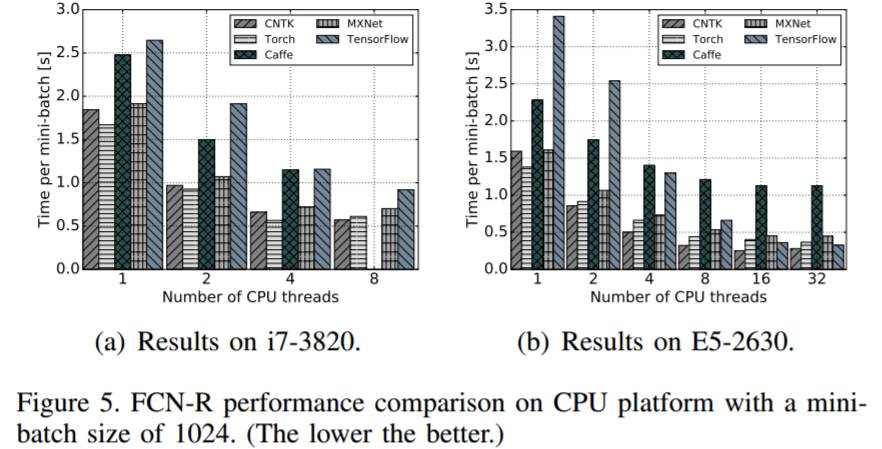
图 5:FCN-R 在 mini-batch 大小为 1024 时在 CPU 平台上的表现的比较(越低越好)

图 6:AlexNet-R 在 mini-batch 大小为 1024 时在 CPU 平台上的表现的比较(越低越好)
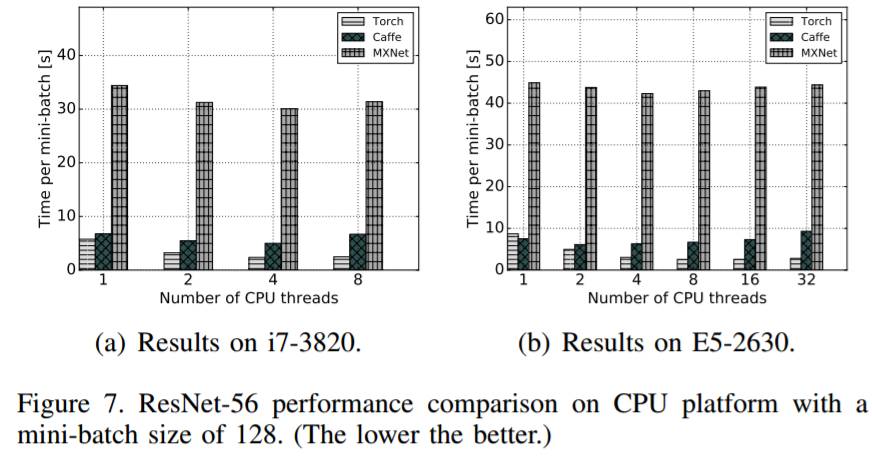
图 7:ResNet-R 在 mini-batch 大小为 128 时在 CPU 平台上的表现的比较(越低越好)

图 8:LSTM 在 mini-batch 大小为 256 时在 CPU 平台上的表现的比较(越低越好)
4.2. 单 GPU 卡评测结果
在单 GPU 卡的对比上,我们也展示了不同 mini-batch 大小的结果,从而演示 mini-batch 大小对表现的影响。
4.2.1. 合成数据(Synthetic Data)

图 9:在不同 GPU 平台运行 FCN-S 时,不同框架的表现对比

图 10 :在不同 GPU 平台运行 AlexNet-S 时,不同框架的表现对比
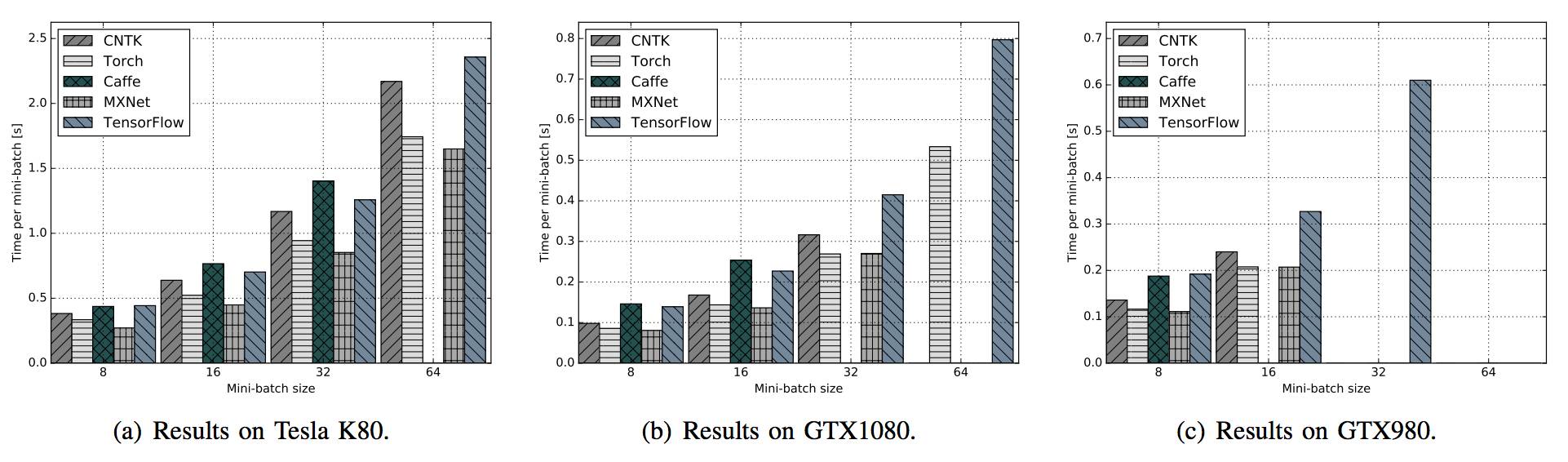
图 11:在不同 GPU 平台运行 ResNet-50 时,不同框架的表现对比
4.2.2. 真实数据(Real Data)
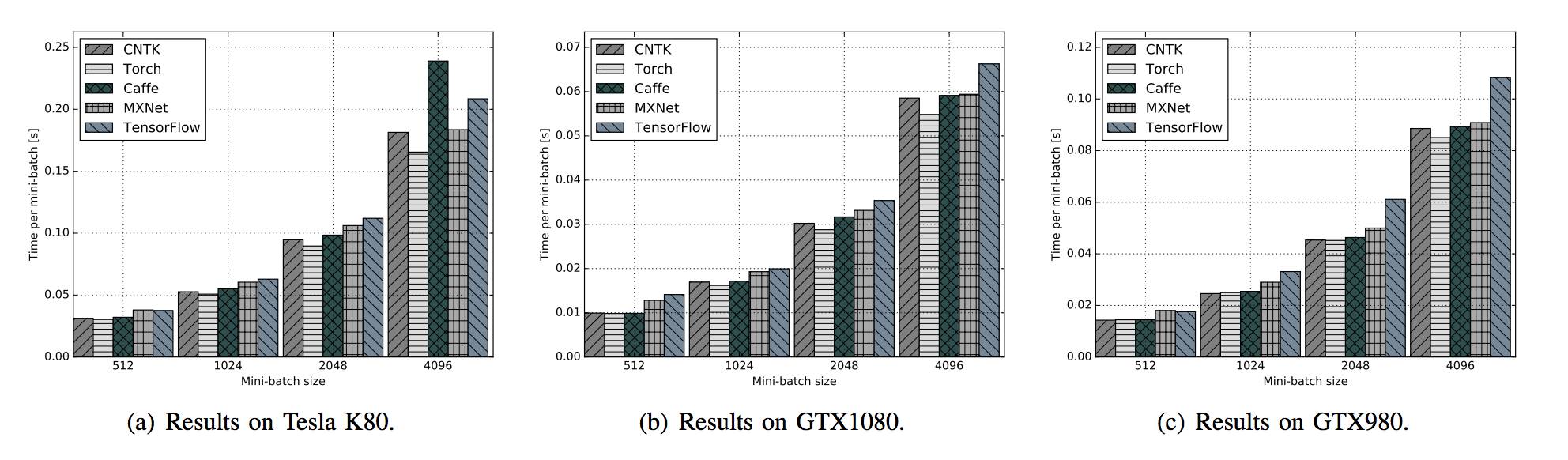
图 12:在不同 GPU 平台运行 FCN-R 时,不同框架的表现对比
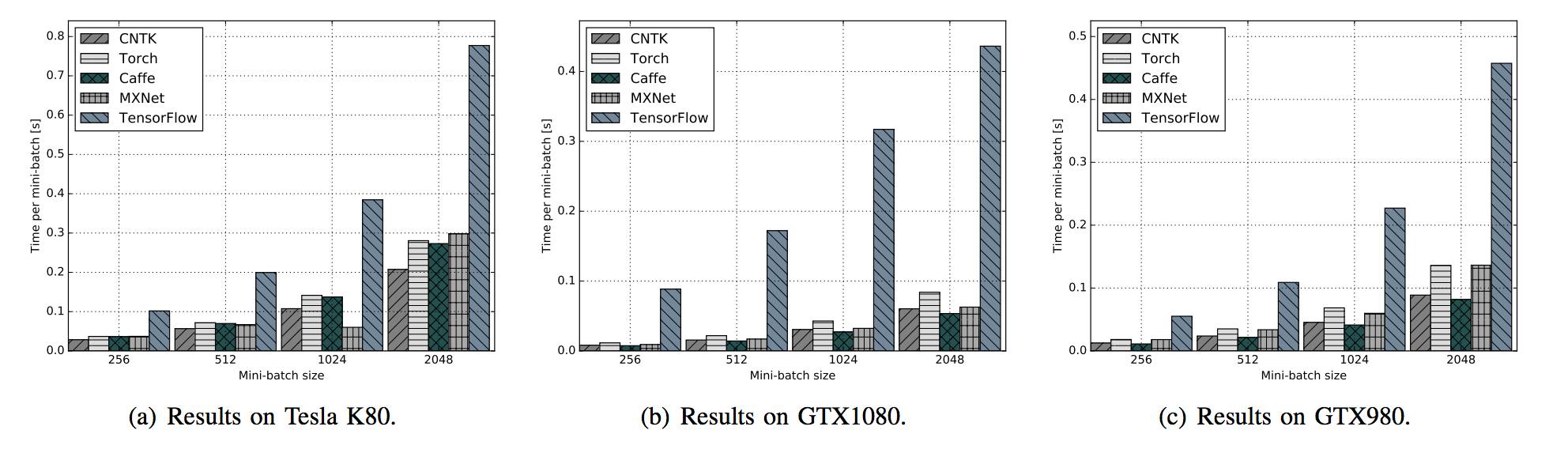
图 13:在不同 GPU 平台运行 AlexNet-R 时,不同框架的表现对比
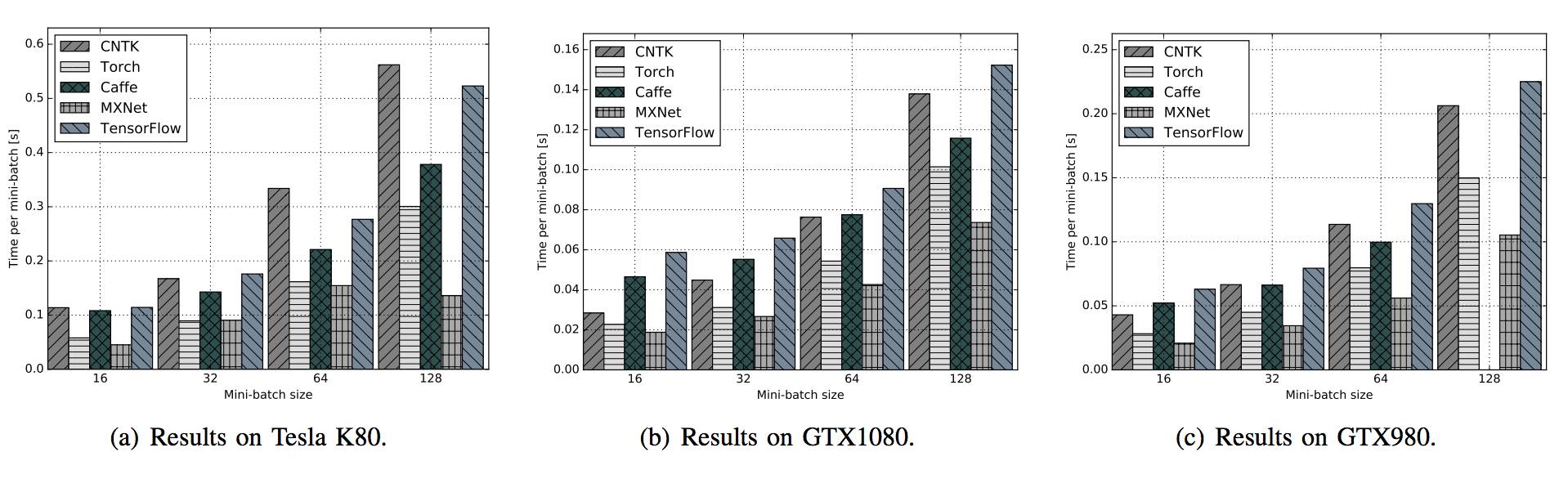
图 14:在不同 GPU 平台运行 ResNet-56 时,不同框架的表现对比
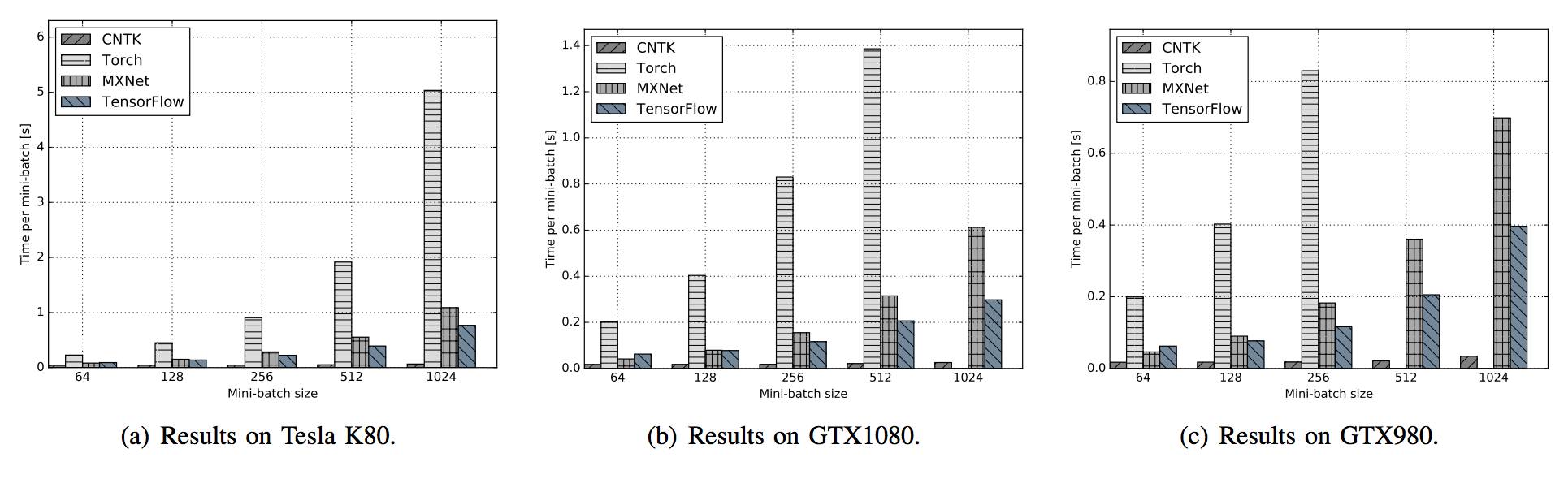
图 15:在不同 GPU 平台运行 LSTM 时,不同框架的表现对比
4.3. 多 GPU 卡评测结果










