本文作者:CSDN优秀博主 专栏作者 「不会停的蜗牛」
TensorBoard 是 TensorFlow 上一个非常酷的功能,我们都知道神经网络很多时候就像是个黑盒子,里面到底是什么样,是什么样的结构,是怎么训练的,可能很难搞清楚。而 TensorBoard 的作用就是可以把复杂的神经网络训练过程给可视化,可以更好地理解,调试并优化程序。
我们在建立神经网络模型解决问题时,例如想要用一个简单的 CNN 进行数字识别时,最想知道的就是什么样的模型,即 weights 和 bias 是多少的时候,可以使得 accuracy 达到较优,而这些变量都可以在 Tensorboard 中以一个可视化的方式看到,
-
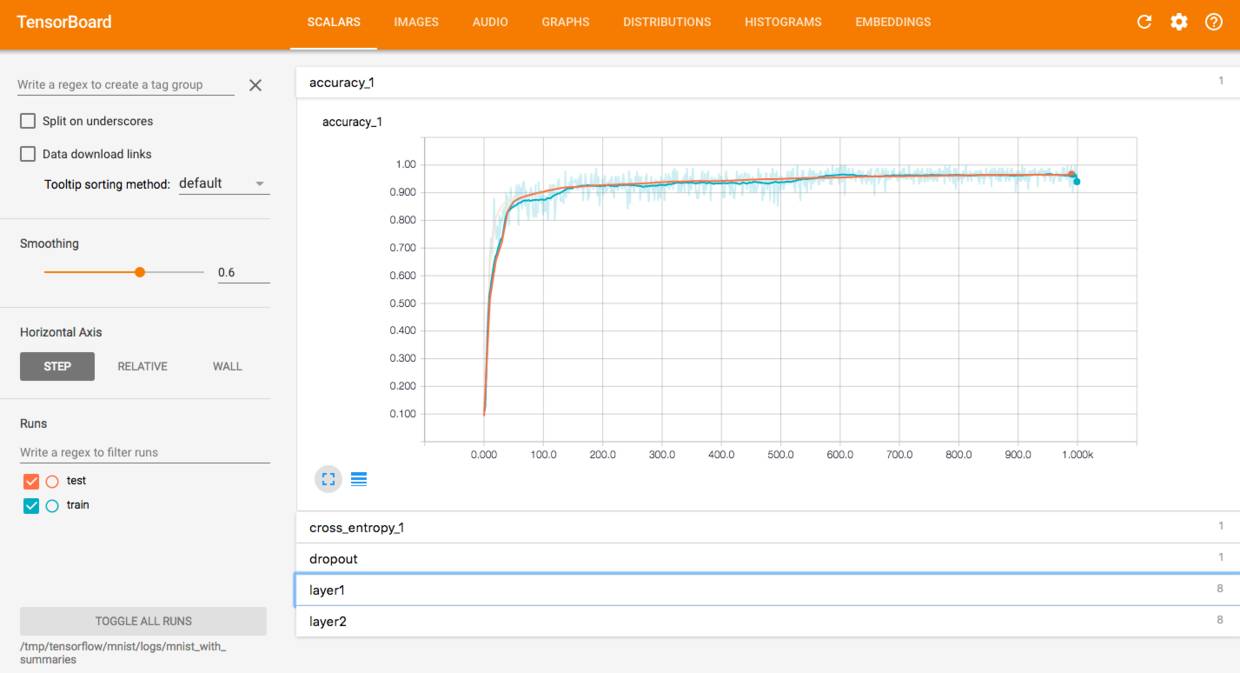
在 scalars 下可以看到 accuracy,cross entropy,dropout,layer1 和 layer2 的 bias 和 weights 等的趋势。
-
在 images 和 audio 下可以看到输入的数据。
-
在 graphs 中可以看到模型的结构。
-
在 histogram 可以看到 activations,gradients 或者 weights 等变量的每一步的分布,越靠前面就是越新的步数的结果。
-
distribution 和 histogram 是两种不同的形式,可以看到整体的状况。
-
在 embedding 中可以看到用 PCA 主成分分析方法将高维数据投影到 3D 空间后的数据的关系。
在官网有两篇关于 TensorBoard 的教程,学习之后总感觉还是不太会用,只是讲了如何做出图来,可是到底该怎么发挥 TensorBoard 的功能呢,不能只是看看热闹,画出来图了,该怎么解读呢?
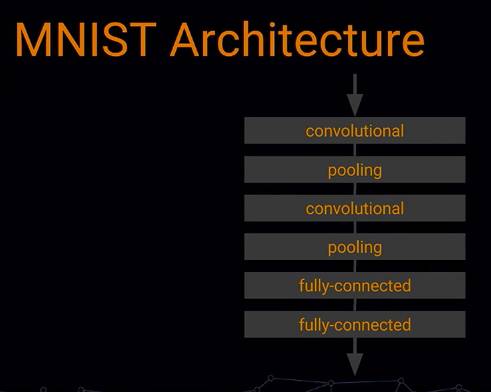
今天就来个更充实的,仍然以 MNIST 为例,来看如何一点点完善一个 model。
下面是一个普通的 convolutional 网络结构,我们全文会在这个结构上进行调优:
这是初级的代码:

先来看一下它的训练结果:

接下来将分为以下几步:
那让我们来打开 board ,看发生了什么,为什么这么低
想要可视化 graph,就先只传一个 graph 进去

在左边我们看到了一个 convolution,
在右边还有一些东西不知道哪里来的:
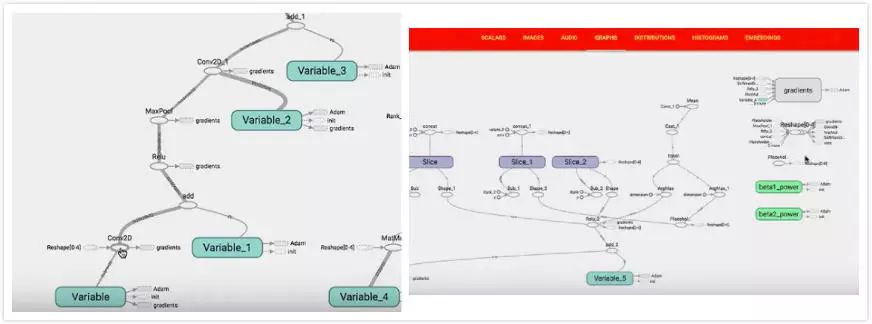
所以需要清理 graph
graph 是基于 naming system,它有 ops,ops 有 names
我们可以给某些具体的 node 特有的 name:
首先给一些重要 ops 赋予 name
如 weights 和 bias,
然后用 name scope ,这样所有的命名后的 ops 都会保持一个整洁的结构

接着给 placeholder names

然后接着给 training 或者 loss names
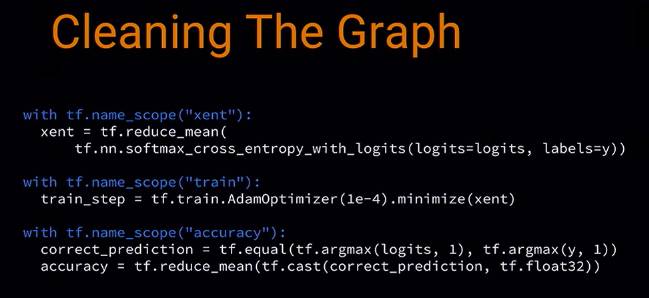
把这个 clean 后的存到 另外一个文件夹

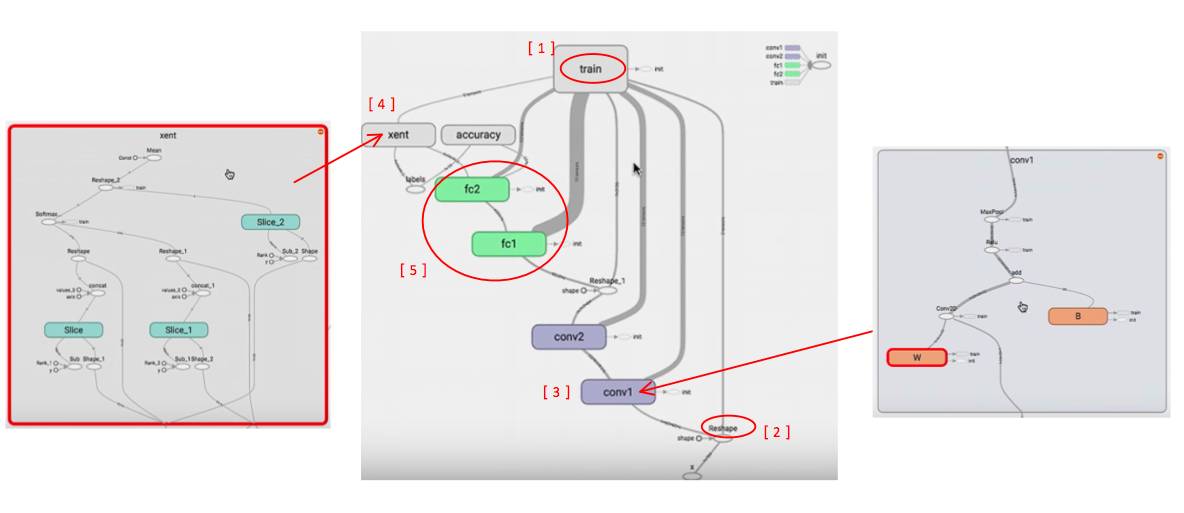
这一次的 graph 就会比较清晰:
-
有个 training block,连接着需要训练的参数,因为当你计算 gradients 时,就会用到相关的 variables
-
我们在代码中,先是有 x 的 placeholder,然后 reshape 了一下,
-
接着我们可以看一下 convolution layer
这样我们就可以看到,图里的结构和我们期望的是一样的
-
这里我们看到 cross entropy 是如何进行的
-
有相似结构的 block 会有同样的 color
-
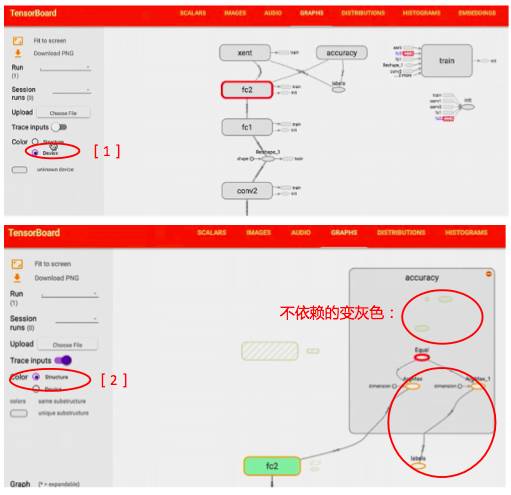
如果既用了 cpu 也用了 gpu ,点上 color by device 就会有不同颜色
-
打开 trace inputs,就可以看到你选中的变量,都与哪些变量有关
Step 2:查看 accuracy,weights,biases
接下来我们需要用到 summaries:
summary 就是一个 tf op,它会从你的 graph 里面提取一个 regular tensor,然后后产生一个 protocol buffers

-
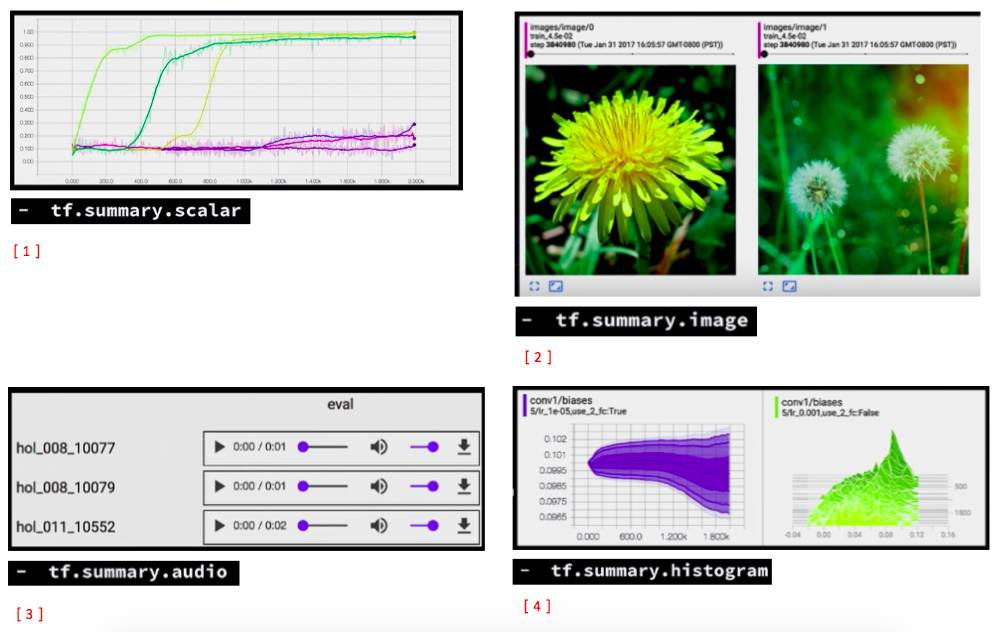
一种是 scalar,是针对单一变量的
-
还有 image 的可以输出 image,可以用来检查是否 data 是否是正确的格式
-
还可以看生成的 音频数据
-
histogram 可以看数据的分布
-
还有一个 tensor summary,可以用来看任何东西,因为 tf 中的所有都是 tensor 形式的
接下来让我们 add 一些 summary 吧:
-
例如来看 cross entropy 和 accuracy 是怎么随时间变化的,
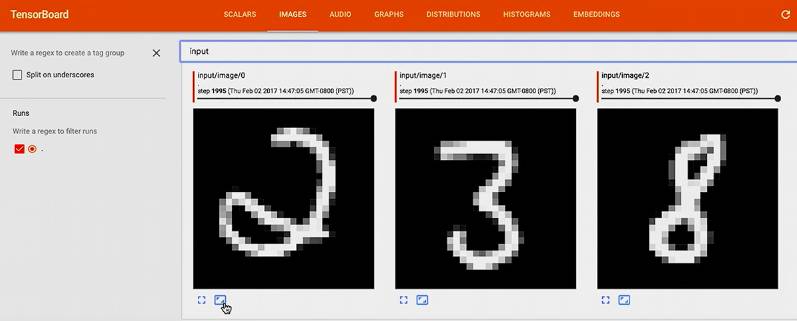
还可以看我们的 input 是不是 MNIST 数据
-
还可以加一些 add 一些 histogram,来看 weights,biases,activations,
我们运行 summary op,然后得到 protocol buffers,
然后写入 disk
-
然后用一个 merge 把所有的 summary 合成一个 target,就不用一个一个地去运行写入展示了

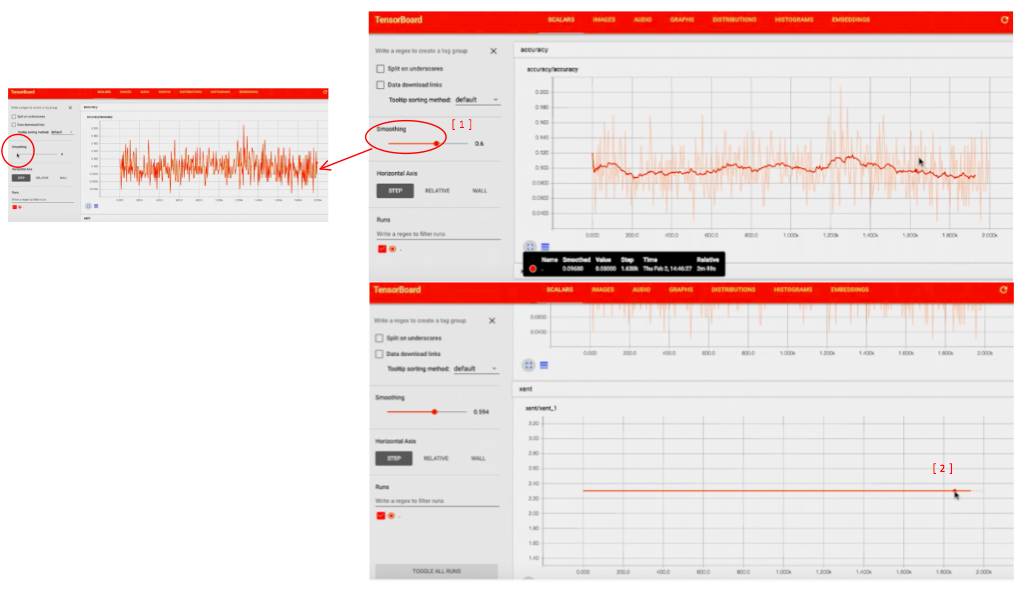
可以看到 accuracy 大约在 10% 徘徊:
-
原始的 data 是有很多噪音的,因为它只是随机抽样
smooth 之后可以看到清晰的 trend
-
还可以看到 cross entropy 的趋势,训练过程中一直都是常数,应该是 model 有点问题了
再看 image 里面的图,嗯,应该是 MNIST 里的数据没错
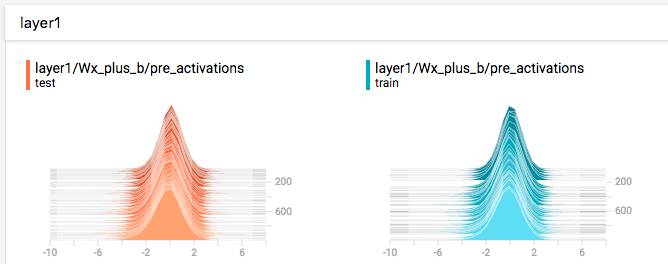
histogram 和 distribution 是两种不同的形式
-
distribution 可以看到 conv 卡在 0 上
-
histogram 可以看到只在 0 处有个尖峰
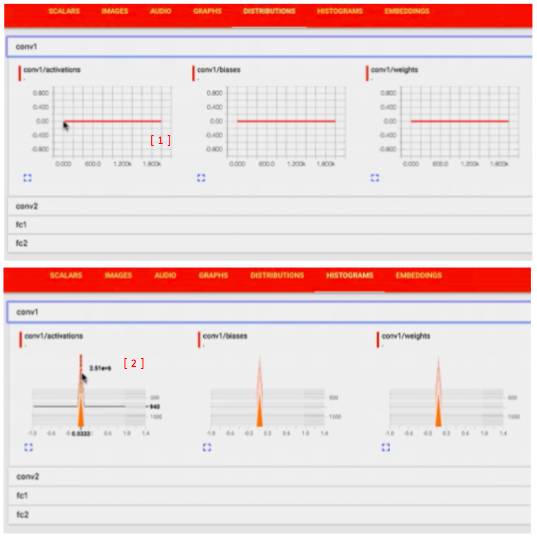
这样我们可以看到,我们在建立 layer 时出了一些问题,
因为当 bias 和 weights 都是 0 的话,我们传递给 activations 的就只是 0 gradients,这时没有训练任何东西
让我们来看看 这一层 怎么了
我们看到 weights 和 bias 被 初始化成 0 了

那我们可以把它们改成更合理的初始化:

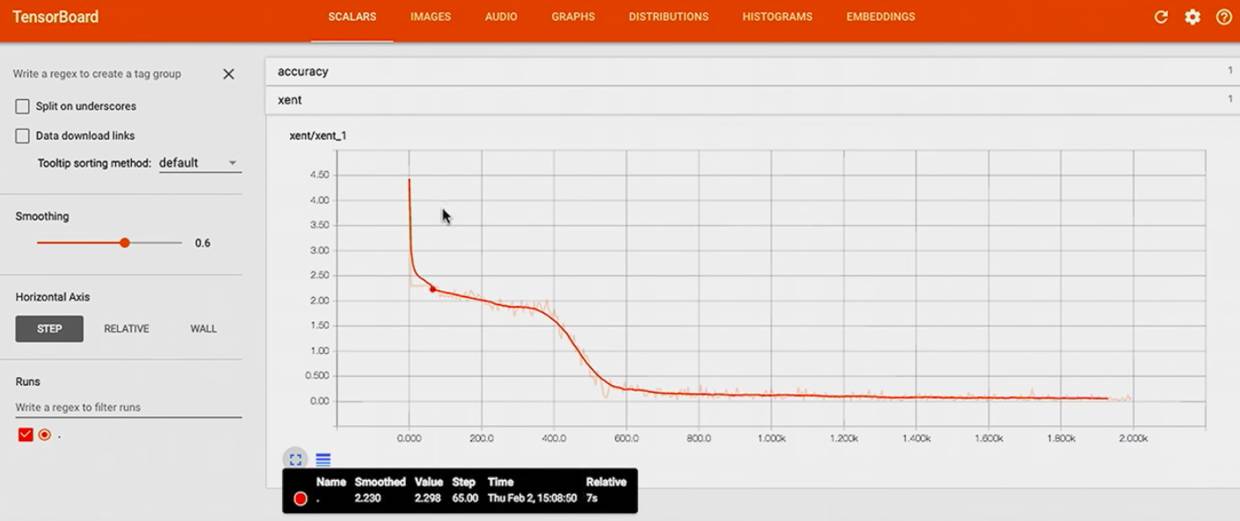
这样我们可以看到更好的结果了:
cross entropy 迅速降到 0,
accuracy 迅速升到 1.
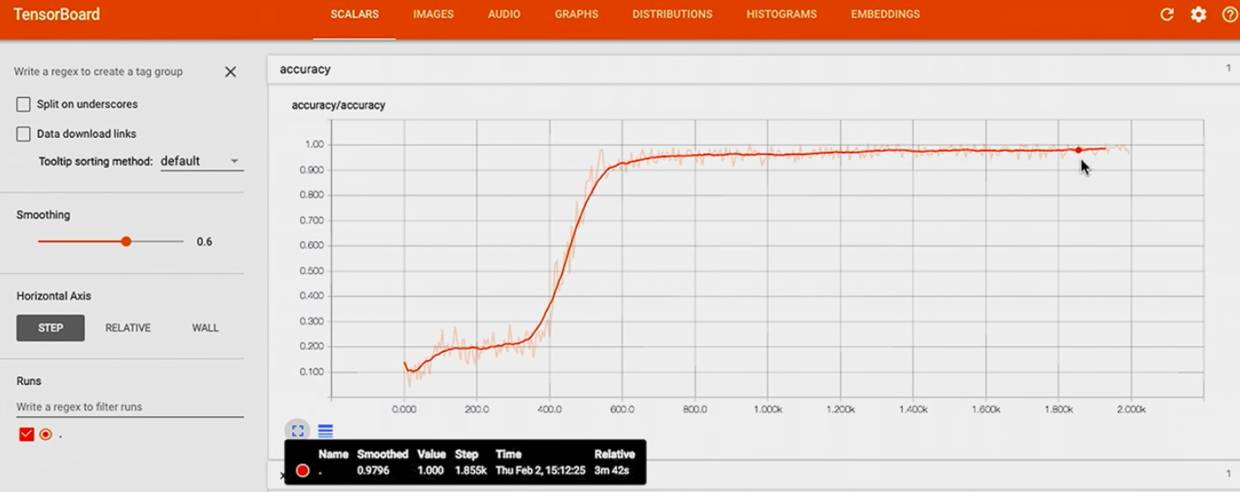
-
同样的,如果我们看 histogram,它也有了更好看的趋势
-
也可以把随着时间变化的展示,改成 overlap
-
在 distribution 可以看到类似的信息,
例如看最开始训练的时候有非常高的 maximum,
然后变成 90%, 60%
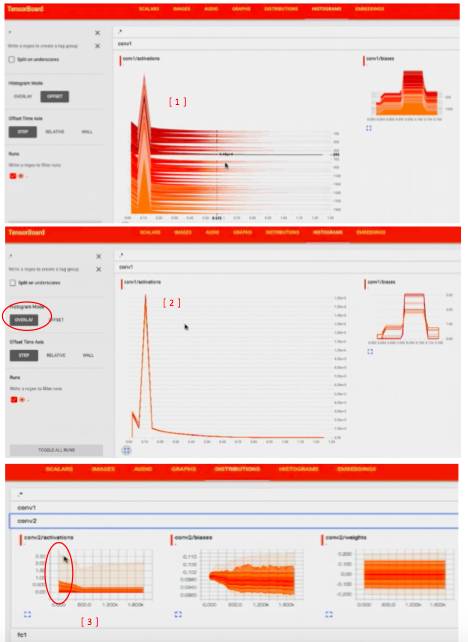
现在发现 model 基本训练的不错了
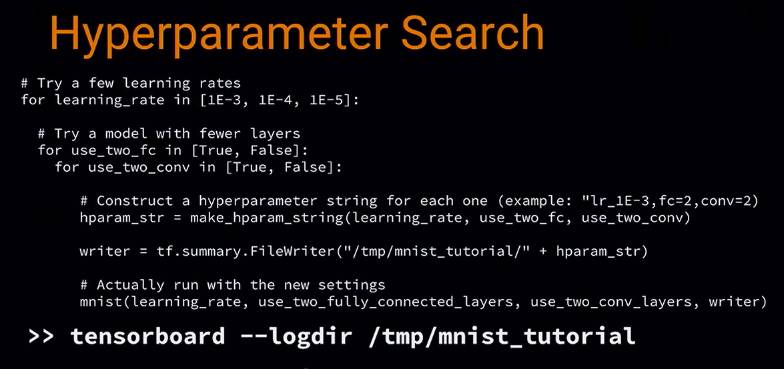
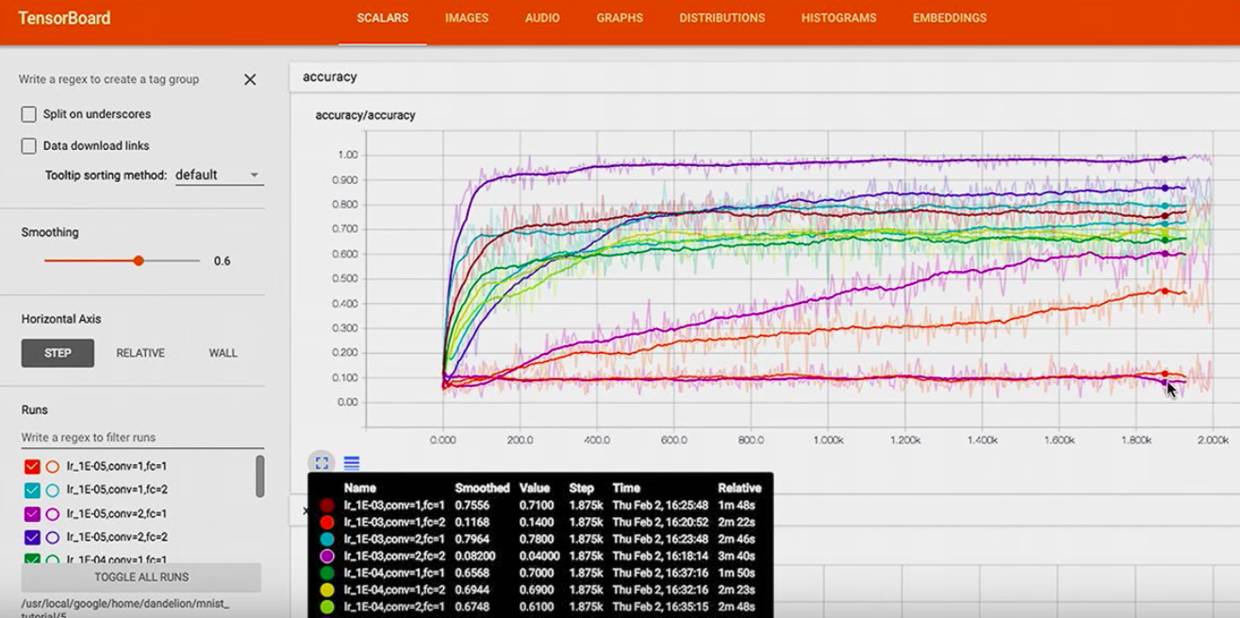
接下来 tf 还可以进行调参
可以看不同版本的 model 在 训练不同的 variable 时哪个更好。
我们要尝试 不同的 learning rates,不同的 convolutional 层,
建立一个 hyperparameter string,然后在打开 board 时指向了上一层文件夹,这样可以比较不同的具体的结果:
在左下角这里可以看到不同的 hyperparameter 设置:
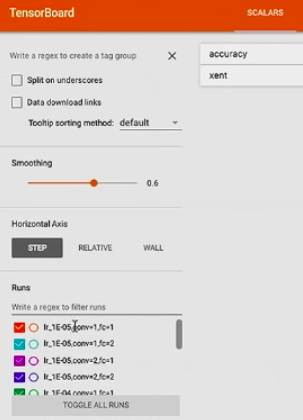
然后可以看到,cross entropy 在不同的 超参数下是怎样的走势
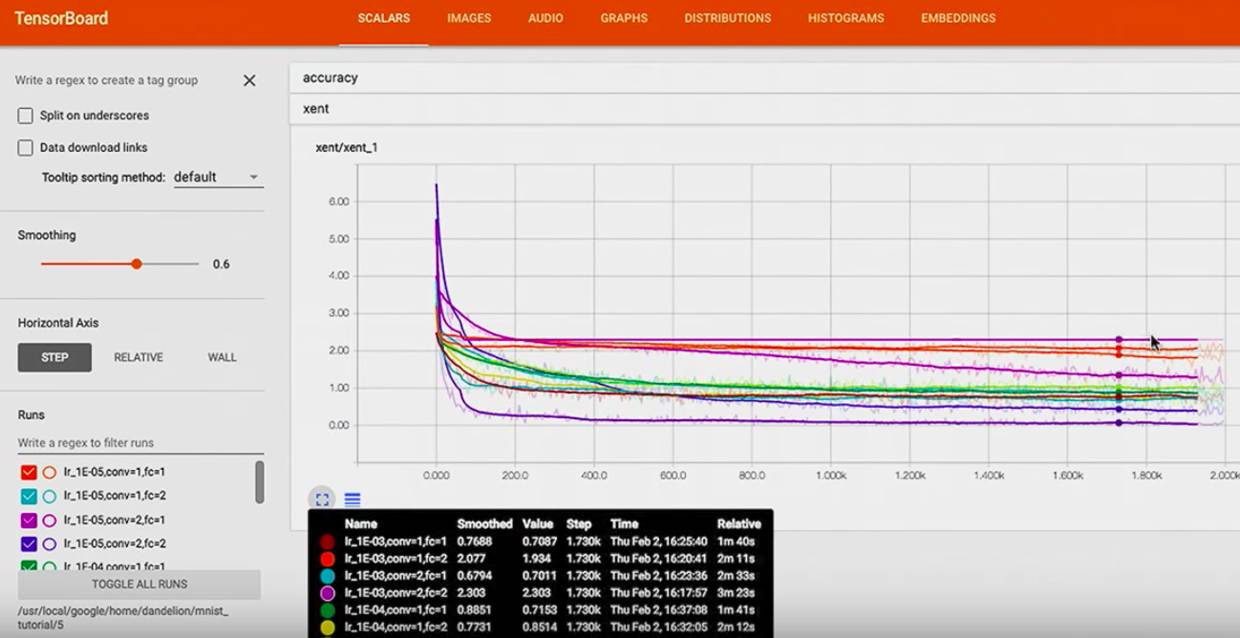
可以看到有些模型几乎没有训练出东西,有些比较成功
-
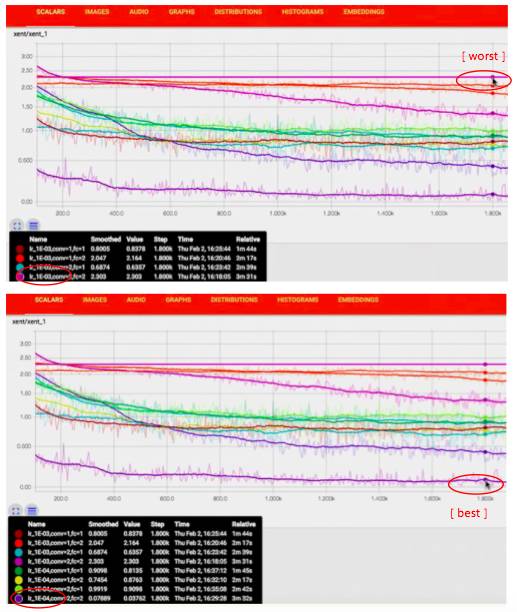
我们还可以看最 wrost 的模型,它的 learning rate = 1 E-03,
-
还可以看最 best 的模型,它的 learning rate = 1 E-04,
-
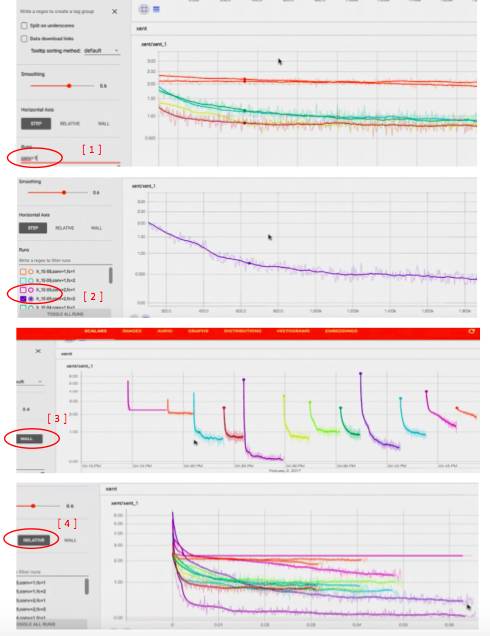
还可以在左下角输入想单独比较的超参数,例如 conv=1
-
还可以只看一条
-
可以用 wall 来看到 不同的模型是在不同的时间训练的
-
还可以通过 realtive 看到不同 模型 用了不同长度的训练时间
-
可以看到 bias 等在不同模型中是如何变化的
在 graph 中可以看到 这是个只有一个 convolutional 层的模型,也可以选择 run 的是哪个模型,就能看到相应的 graph:
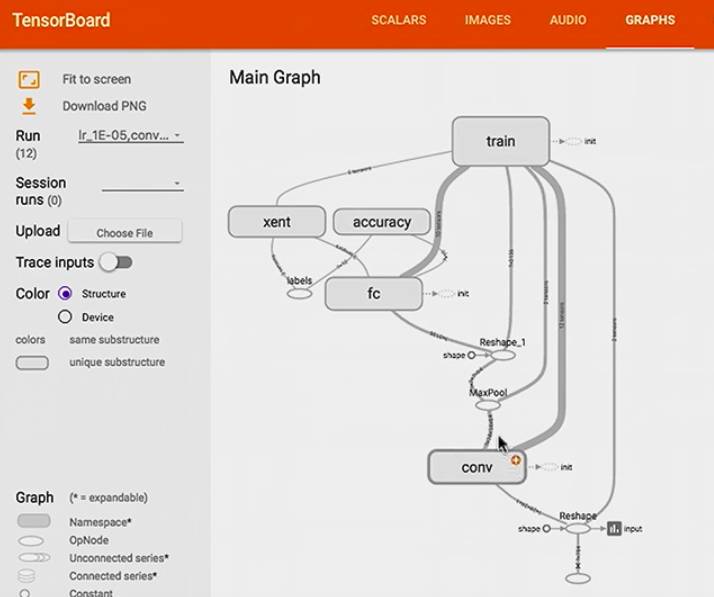
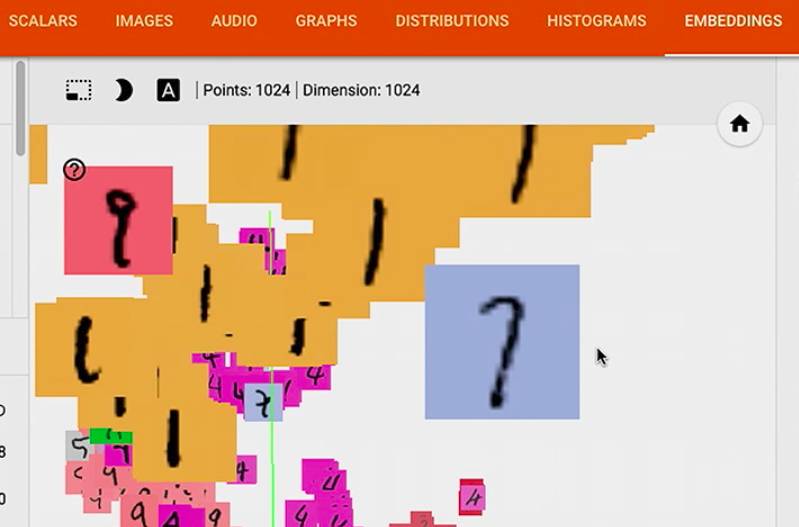
Step 5: 用 embedding 进一步查看 error 出处
接下来是最酷的功能,embedding 可视化,它可以把高维数据映射到 3D
我们有了 input,然后经过 NN,embedding 就是我们的 NN 是如何处理信息的 表现
我们需要建立 variable 来装测试集的每个 image 的 embedding,
然后建立 config,用来知道哪里可以找到每个 MNIST 的 sprite 图片,这样就可以在浏览器看到缩略图了,并用 label 把它们组织起来
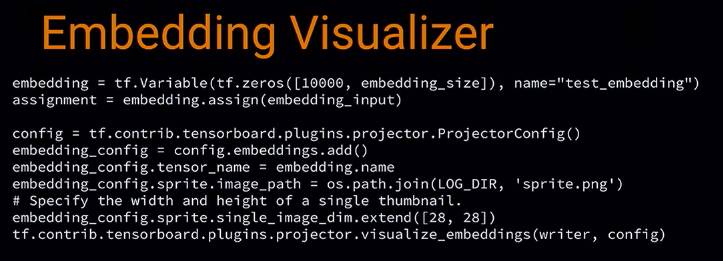
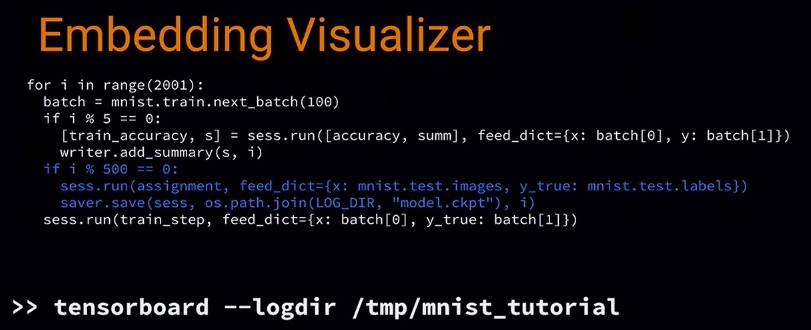
用 filewrite 写入 disk,每 500 步保存一个 model checkpoint,包含所有的 variables,包括 embedding 的
这样可以看到测试集的 1024 个数据,
我们现在用的 PCA,选了 top 3 的主成分,然后展示了 3D 的表示图,
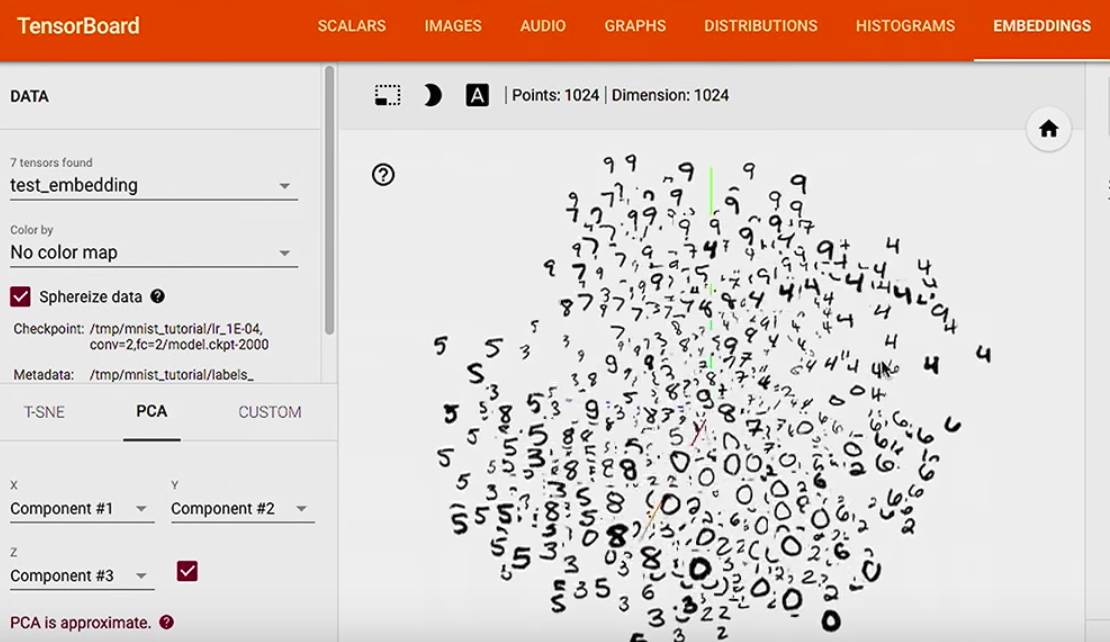
color by label 后,可以看到我们的 model 分类的比较不错哦,
例如 1 都聚到了一起,因为 1 就是 1,没有和它比较容易混淆的数字
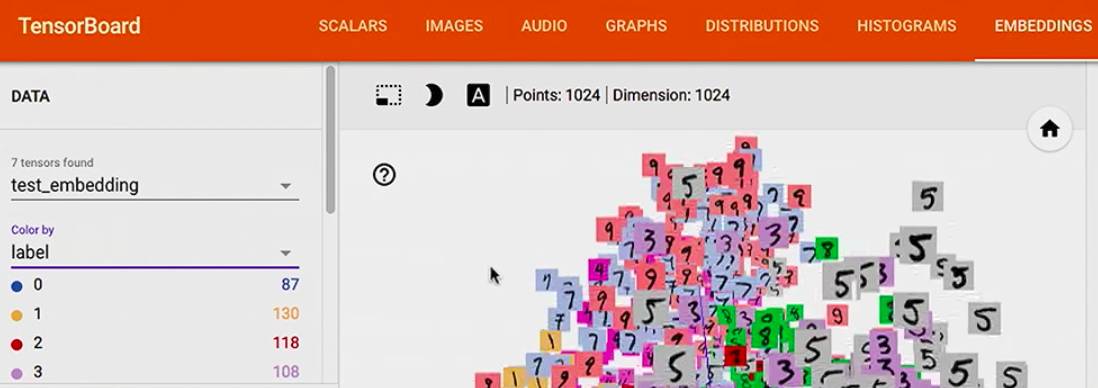
如果用 TSNE,它可以 保持 local 相似性,
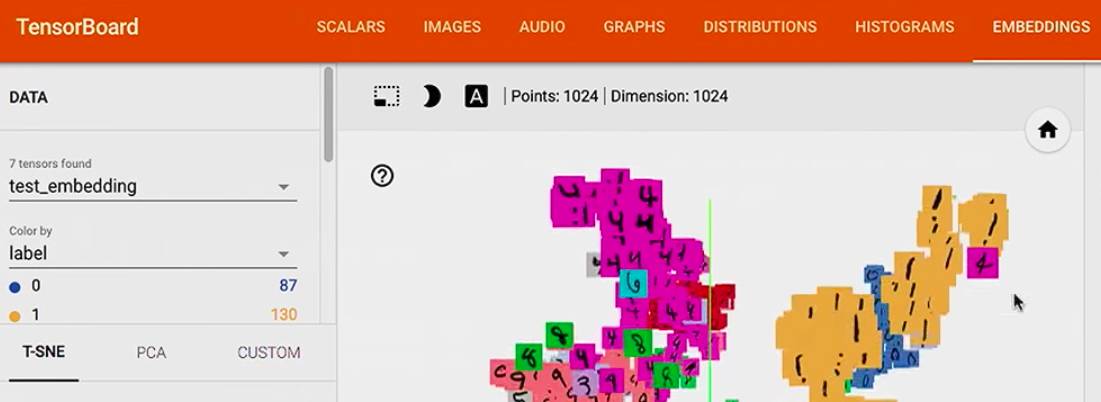
我们可以看到 1 识别的比较好,但是在 3,5,8 上面遇到了一些困难,因为它们看起来有点相近,
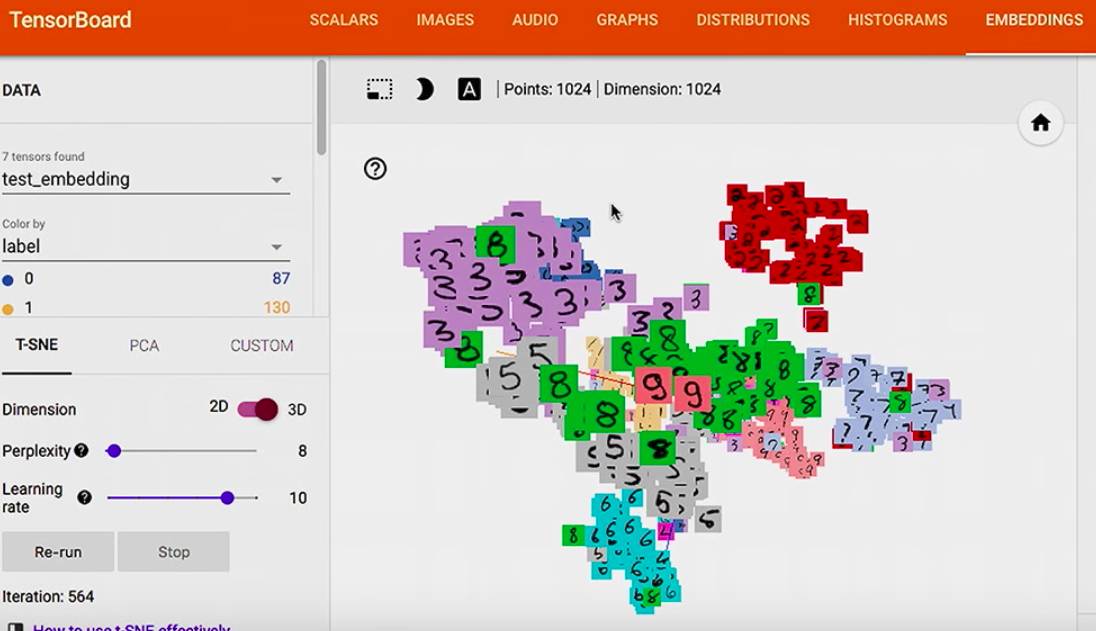
接下来让我们来看一下一个 bad 预测,例如这个 7, 它被放在了 1 的一堆中,也就是 model 把一个 7 标记成了 1,
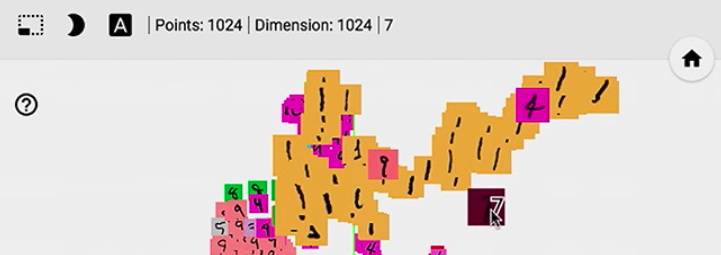
然后我们可以放大一下,这个 7 确实很像 1,那我们的 model 的确是会把它看成 1, 还有那个 9 也很像 1.
好了,上面基本把 TensorBoard 各板块上主要的功能简单介绍了一下,而且用了一个小例子,看如何借用各个板块的可视化结果来帮助我们调优模型:
希望也可以帮到大家,据说后面 TensorFlow 会推出更炫的而且更专业的可视化功能,例如语音识别的,有了这种可视化的功能,最需要精力的调优环节也变得更有趣了。
参考:
https://www.tensorflow.org/get_started/summaries_and_tensorboard
https://www.tensorflow.org/get_started/summaries_and_tensorboard
https://www.youtube.com/watch?v=eBbEDRsCmv4
本文 code:
https://gist.github.com/dandelionmane/4f02ab8f1451e276fea1f165a20336f1#file-mnist-py







