我们以前看到的很多架构变迁或者演进方面的文章大多都是针对架构方面的介绍,很少有针对代码级别的性能优化介绍。本文将针对一些代码细节方面的东西进行介绍,欢迎大家吐槽以及提建议。
-
单台 40TPS,加到 4 台服务器能到 60TPS,扩展性几乎没有。
-
在实际生产环境中,经常出现数据库死锁导致整个服务中断不可用。
-
数据库事务乱用,导致事务占用时间太长。
-
在实际生产环境中,服务器经常出现内存溢出和 CPU 时间被占满。
-
程序开发的过程中,考虑不全面,容错很差,经常因为一个小 bug 而导致服务不可用。
-
程序中没有打印关键日志,或者打印了日志,信息却是无用信息没有任何参考价值。
-
配置信息和变动不大的信息依然会从数据库中频繁读取,导致数据库 IO 很大。
-
项目拆分不彻底,一个 Tomcat 中会布署多个项目 WAR 包。
-
因为基础平台的 bug,或者功能缺陷导致程序可用性降低。
-
程序接口中没有限流策略,导致很多 VIP 商户直接拿我们的生产环境进行压测,直接影响真正的服务可用性。
-
没有故障降级策略,项目出了问题后解决的时间较长,或者直接粗暴的回滚项目,但是不一定能解决问题。
-
没有合适的监控系统,不能准实时或者提前发现项目瓶颈。
我们从第二条开始分析,先看一个基本例子展示数据库死锁的发生:
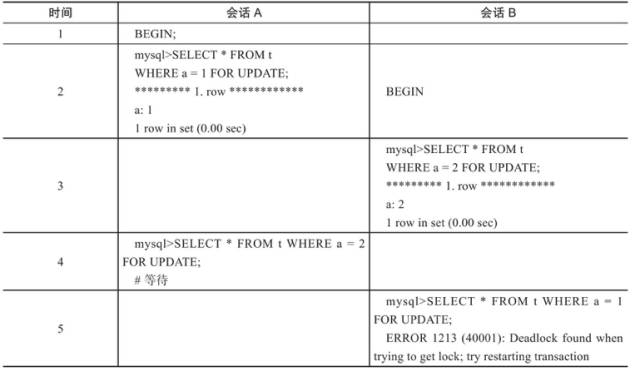
注:在上述事例中,会话 B 会抛出死锁异常,死锁的原因就是 A 和 B 二个会话互相等待。
分析:出现这种问题就是我们在项目中混杂了大量的事务 +for update 语句,针对数据库锁来说有下面三种基本锁:
当 for update 语句和 gap lock 和 next-key lock 锁相混合使用,又没有注意用法的时候,就非常容易出现死锁的情况。
那我们用大量的锁的目的是什么,经过业务分析发现,其实就是为了防重,同一时刻有可能会有多笔支付单发到相应系统中,而防重措施是通过在某条记录上加锁的方式来进行。
针对以上问题完全没有必要使用悲观锁的方式来进行防重,不仅对数据库本身造成极大的压力,同时也会把对于项目扩展性来说也是很大的扩展瓶颈,我们采用了三种方法来解决以上问题:
以上三种方式都必须要有过期时间,当锁定某一资源超时的时候,能够释放资源让竞争重新开始。
伪代码示例:
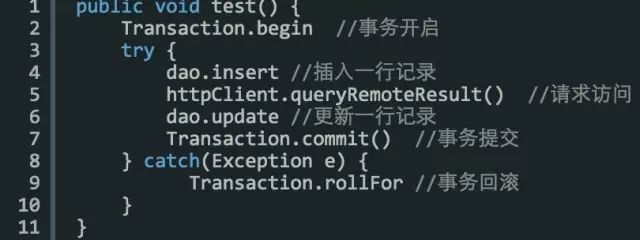
项目中类似这样的程序有很多,经常把类似 httpClient,或者有可能会造成长时间超时的操作混在事务代码中,不仅会造成事务执行时间超长,而且也会严重降低并发能力。
那么我们在用事务的时候,遵循的原则是快进快出,事务代码要尽量小。针对以上伪代码,我们要用 httpClient 这一行拆分出来,避免同事务性的代码混在一起,这不是一个好习惯。
下面以我之前分析的一个案例作为问题的起始点,首先看下面的图:
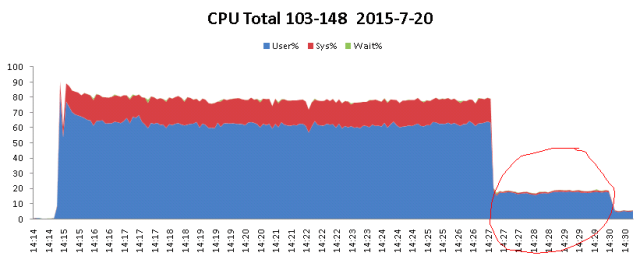
项目在压测的过程中,CPU 一直居高不下,那么通过分析得出如下分析:
我们针对线上的环境进行模拟,尽量真实的在测试环境中再现,采用数据库连接池为咱们默认的 C3P0。
那么当压测到二万批,100 个用户同时访问的时候,并发量突然降为零!报错如下:
com.yeepay.g3.utils.common.exception.YeepayRuntimeException: Could not get JDBC Connection; nested exception is java.sql.SQLException: An attempt by a client to checkout a Connection has timed out.
那么针对以上错误跟踪 C3P0 源码,以及在网上搜索资料发现 C3P0 在大并发下表现的性能不佳。
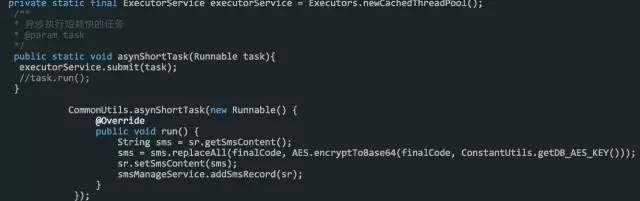
以上代码的场景是每一次并发请求过来,都会创建一个线程,将 DUMP 日志导出进行分析发现,项目中启动了一万多个线程,而且每个线程都极为忙碌,彻底将资源耗尽。
那么问题到底在哪里呢???就在这一行!





