〈五〉
一遇泰坦误终身
或许林燕妮自己也没有想到
写了一辈子的文
最后能和自己老公的「沧海一声笑」
一起流过的岁月的,
是那篇
《一遇杨过误终生》
今天的主题,叫做「一遇到泰坦误终身」。你会问,泰坦是什么?Titan X -- NVIDIA Pascal 架构下的终极显卡(Graphics Card)产品。显卡?!这不是一个人工智能硬件的专栏,我又不玩游戏,关显卡什么事?且听小编慢慢道来。

在进入正文以前,我们先来回忆两个概念,其一是加速器(你还记得挂在 ARM core 边上的加速协处理器么?见「脑芯编(三)」),其二是单指令多数据体系结构(SIMD,见「脑心编(四)」)。在人工智能大热之前,这两个方案就已经广泛地出现在我们的系统中,这个系统叫做「显卡」。那是一个显卡还在用来的投影(shadow)和渲染(rendering)的年代。除了高等级游戏玩家,普通人的电脑常有一个抬不起头的配置——「集显」。
显卡主要用于大规模的同一类型计算,比如向量积和一些简单的非线性操作。听起来有没有很熟悉?神经元也是同一类操作。也就是说在神经网络大红之前,显卡已经在类似硬件上默默耕耘了数十年。但是,十年前没有人会想到上帝会掉一个馅饼到 NVIDIA 额头上,让它成为了比肩 intel 的超强处理器帝国。原因有二,其一是显卡是最能体现体系结构中协处理架构和 SIMD 的硬件。除此之外,显卡还有一个法宝,称为——多线程并行(Multi-thread parallelism)。
最远的距离,是你的芯里没有我
张小娴说「世间最遥远的距离,不是生与死,天与地,是我在你面前,你却不知道我爱你。」而在数据处理器里,也有一个如此「遥远」的距离——存储数据访问失败。
故事起源于计算机体系结构中存储的分级结构(memory hierarchy)。一般,一台处理器的数据存储的位置,以离计算单元的位置排序,包括寄存器表(Register File),高速缓存(cache),内存(DDR Memory)和硬盘(SSD/Hard Disk)。非常容易理解地,离计算单元越远,访问延时越长,但是可用作存储的空间越大。
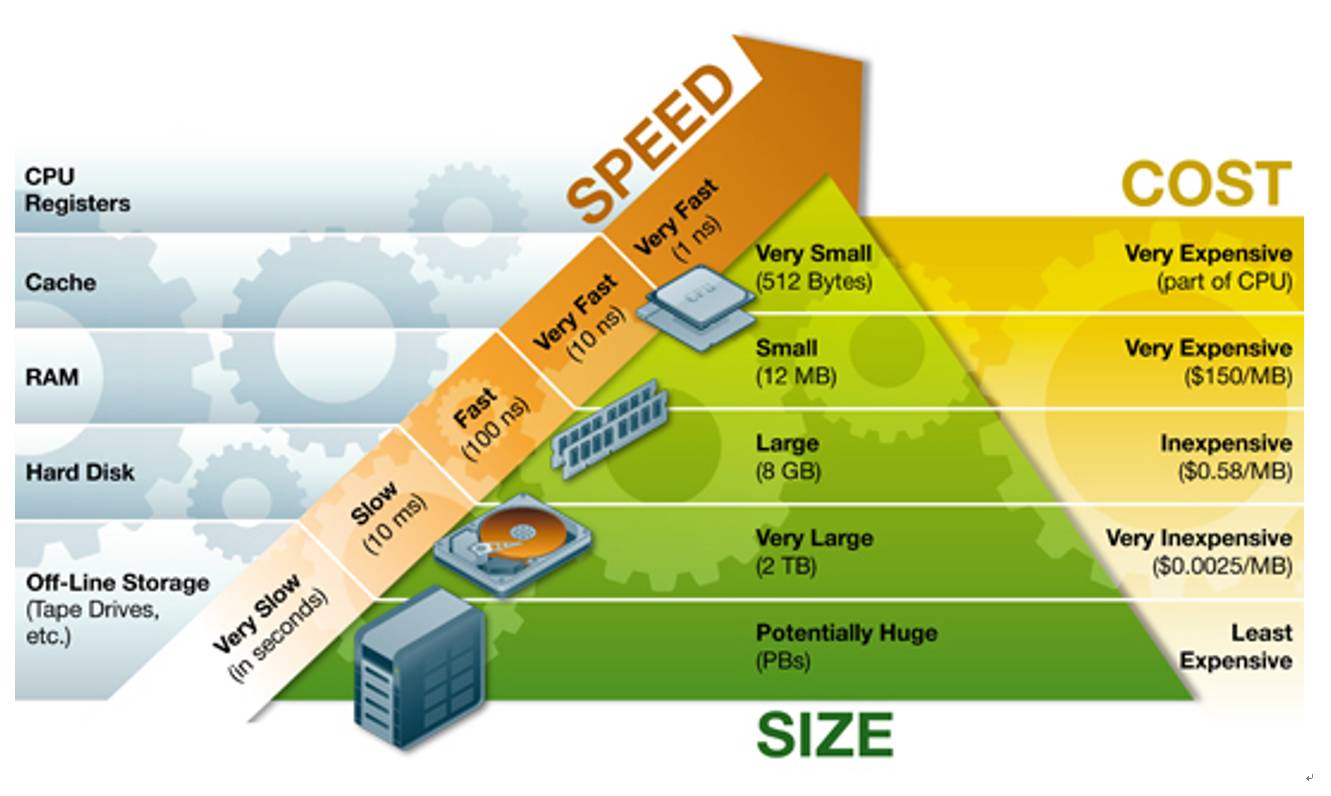
那问题是,什么样的数据,该放在 Cache 里呢?简单的答案,是不断被访问的数据。那万一不断被访问数据不在 Cache 里呢?那处理器就要派出一个信号兵,历经千山万水,走到 disk 来求得一本「真经」再带回处理器开始计算。那这段时间里,处理器单元在干什么呢?
等。
就像那些只能把爱存在心底的痴人。
解药,只能是爱上另一个人。
用计算机体系结构的话说,是执行——
另一个进程
我们在讲到 VLWI(超长指令集)谈到过说,其实不同类型的执行电路是相互独立的。对于一个包含 load/store 指令和 ALU 计算指令的处理器,完全可以同时执行 load/store 和计算,只要两者间的数据不存在依赖关系。即,处理单元在派出信号兵的时候,仍然也在高效率的计算。那么,我们把这两个没有数据依赖关系的指令称为它们分别属于两个进程(thread)。
对于这样的操作,处理器在传统体系架构往外还需要支持一个叫「scheduler」的发射器,用于分配当前处理器的不同模块分别处于哪一个进程中。显然地,就每个进程而言,其寄存器是独立的。共享的只是操作实现单元。
GPU 就是在这一概念下产生。下图是一个典型的 GPU 多核单元。可以看到,他有 32 个处理单元,称为 CUDA Core,每个 CUDA Core 里有一个浮点计算单元和一个整数计算单元。16 为一队分为两组。还有 16 个 Load/Store,和四个特殊函数计算单元(SFU, Special Function Unit)用来计算三角函数之类的。
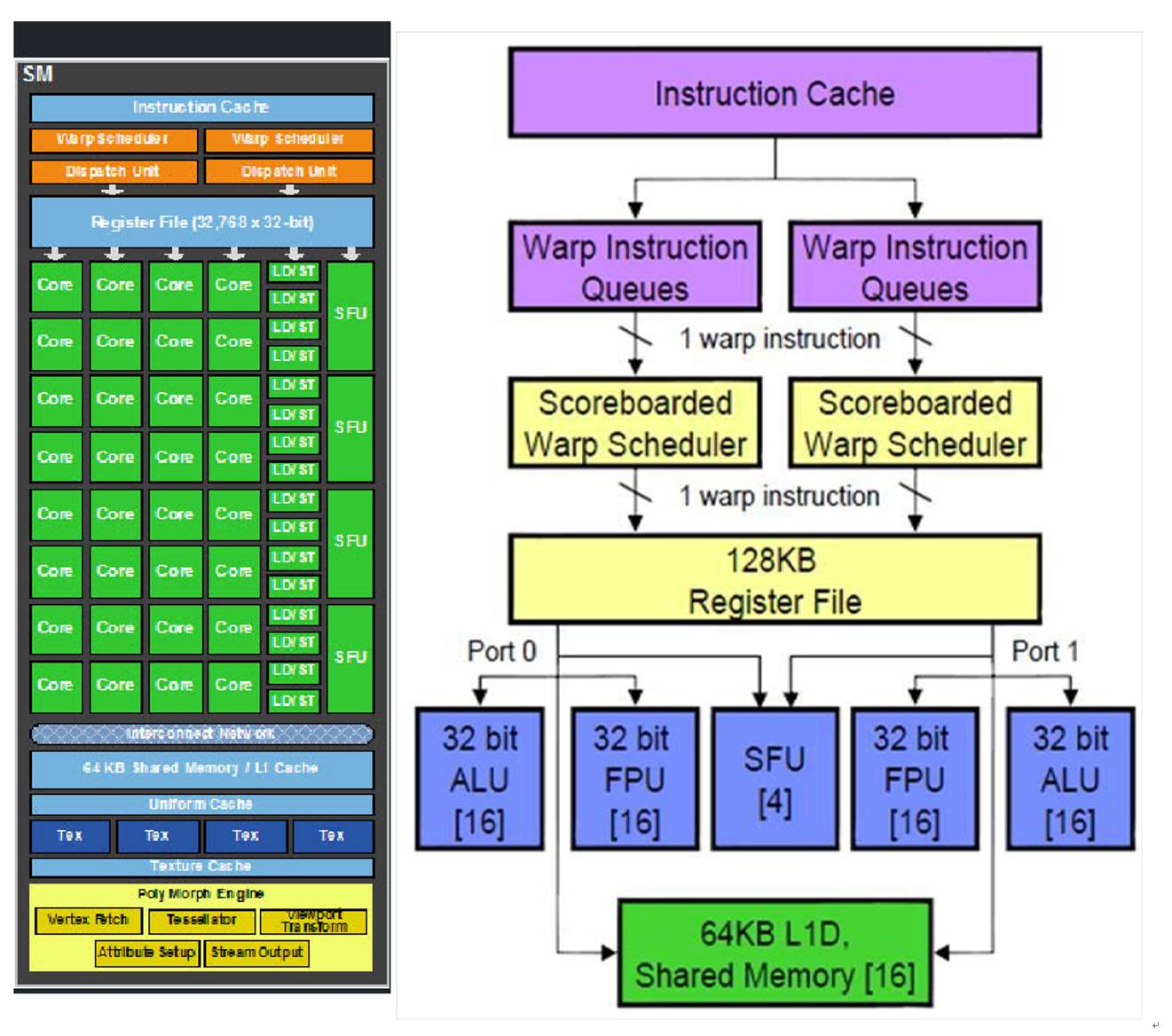
这样,这个处理器就可以以 16 为单位,在同一实现执行一条指令,即 SIMD。除此之外,LD/ST 与两组 CUDA Core 可以按照不同的指令同时对于不同的 Thread 进行不同的操作。至于当前情况对哪个 Thread 进行操作,由 Scoreboard(记分牌)和 Warp Scheduler 共同决定。因此,cuda 是不用等 ld/st 操作的。

讲到这里,不得不提一下 Nvidia 的起名,那也是一种境界。比如说线程吧,好好的 thread 的不叫,要叫 warp。如果各位硅工辅修一门「羊毛衫针织技术」课的就会理解这个名字精妙所在,上图是 google image 搜出来的 thread 和 warp。Thread 是单一没有规律的线,而 warp 是针织后多条并线错落有致的线。Warp 可以形象地体现 GPU 中每个线程的并行性和交替活跃的特征。可惜,大部分硅工连 warp 可以作名词都不知道。另外,NV 还把一个上述的并行的单元处理器叫做 streaming multiprocessor。对,简写就是那个五十度灰里羞羞的 SM,看 GPU 的文章时,一定不要对四处飞的 SM 想太多哦。
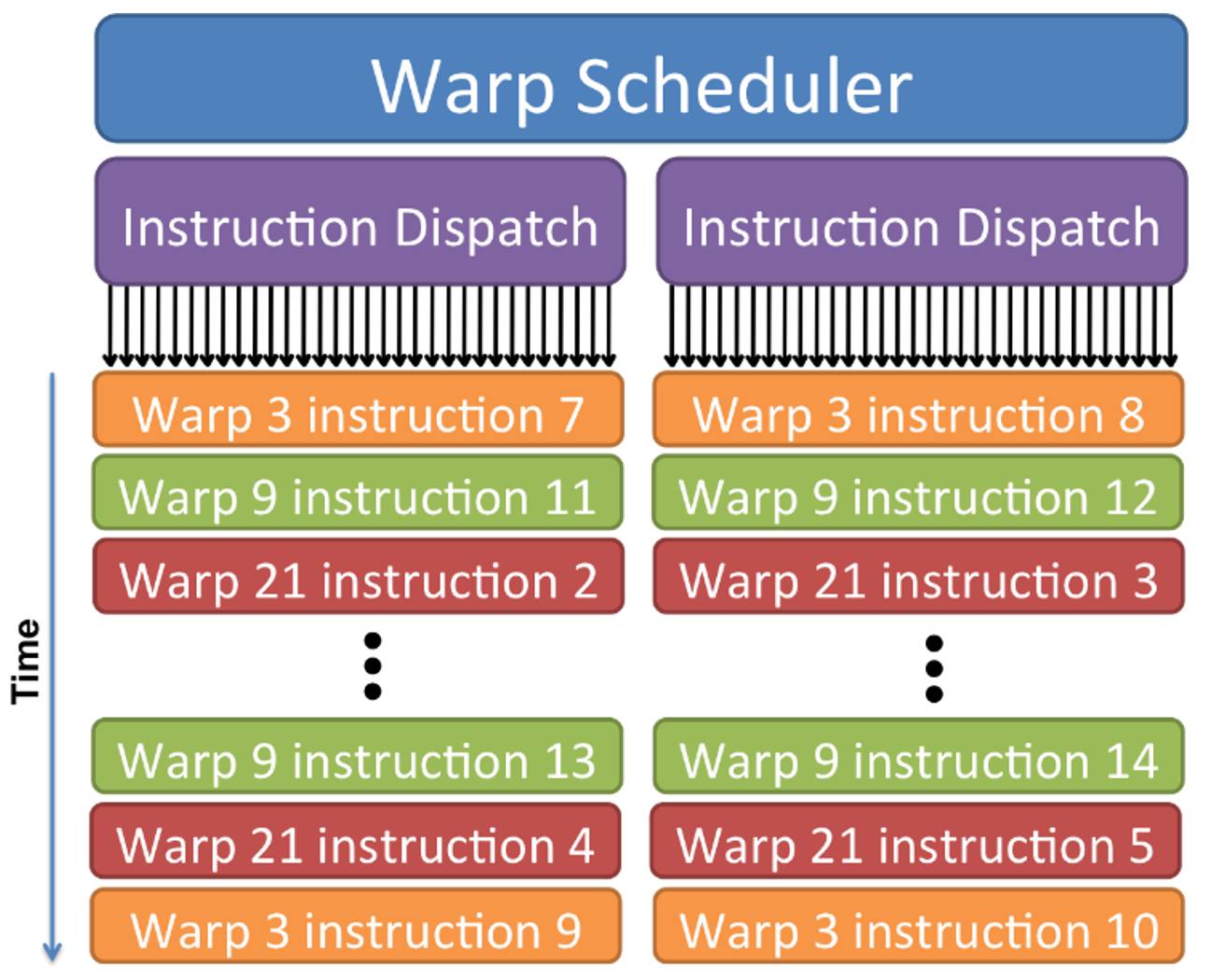
时间上,一个可能的 SM 处理的操作如下图所示。通过 Warp Scheduler, 每个对应的 cuda core 将在不同的 thread 间跳跃以达到性能的最优值,同时成功地掩护处理器对存储器里所需数据的访问时间。
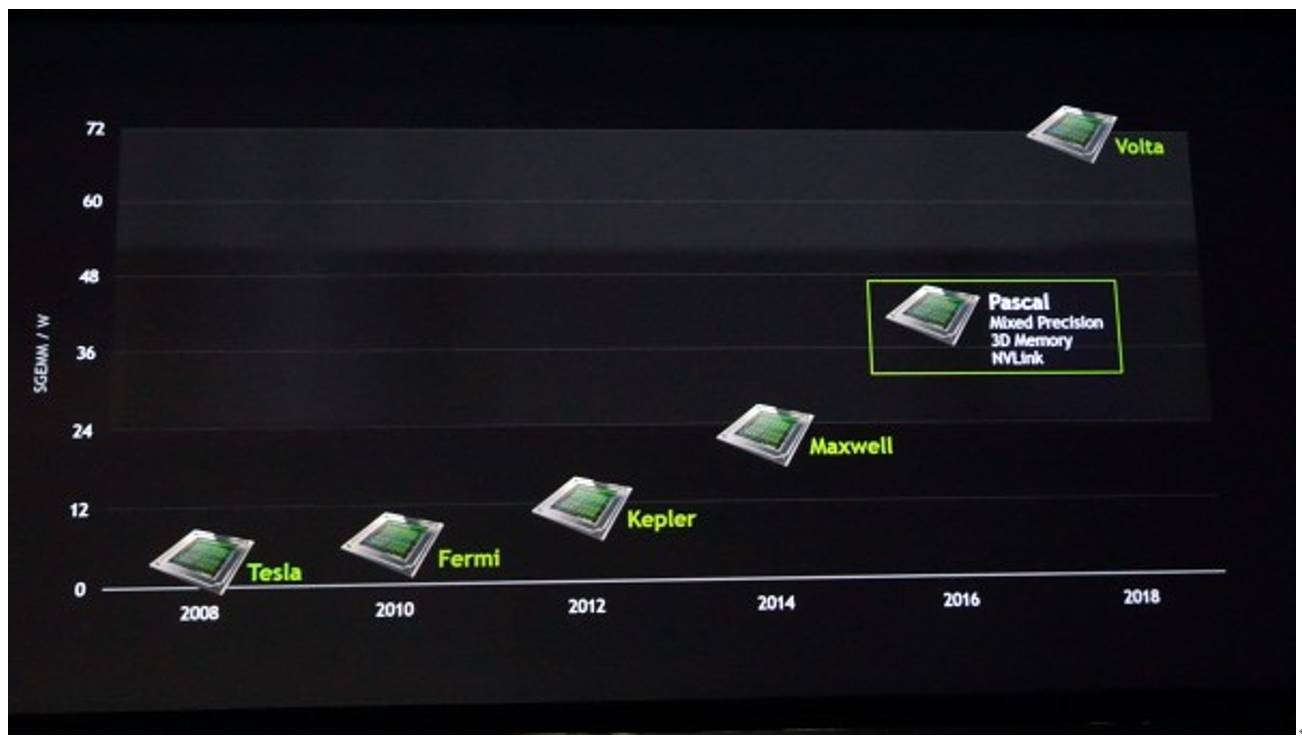
从费米到帕斯卡:泰坦之父们
希腊神话里面,泰坦们是天神 Uranus 和地神的 Gaia 的后代,是奥林匹斯众神(宙斯等)的父辈。然而,在 GPU 的世界里,泰坦之父却要贡献给这四个名字:
Fermi / Kepler / Maxwell / Pascal
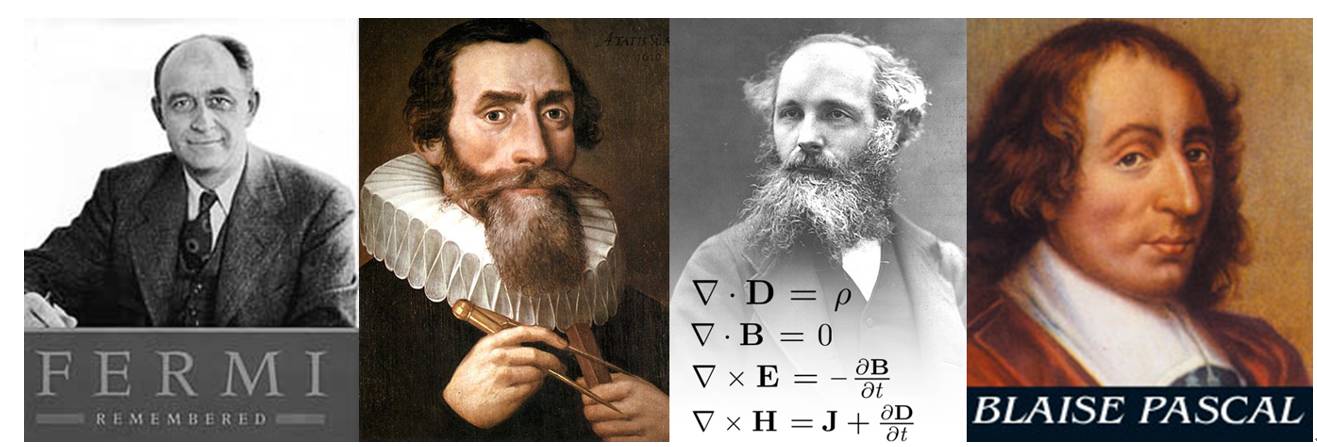
这 4 位鼎鼎大名的先贤(不认识的请自行回去打屁股)又和 GPU 有什么关系呢?这又要归结到 Nvidia 牛逼的起名学了。10 年以前,专用图像处理芯片都叫做「显卡」(Graphics Card)。但 2008 年的时候,多家公司决定给他一个高霸上的名字——「图像处理单元」(Graphic Processing Unit, GPU)。Nvidia 从那时起,给每一代自己的图像处理芯片都冠一个牛逼哄哄的干爹姓。第一任干爹就是大名鼎鼎的核物理学家——Enrico Fermi。其实,fermi 前还有个,叫 tesla 姓,但是现在 tesla 已经被 NV 作为一个产品线名字了。就这样,GPU 以两年一代的速度,不断进取,如今已经发展到 Pascal 代。在今年刚过去的 CES,下一代架构 Volta 的样机已经出现了,集成在 xaiver 平台上。(请参考《矽说--从芯片核弹到未来平台:从 CES 看 Nvidia 的转型野心》)
Titan X 首次亮相时在 Maxwell 时代,目前能买到的新款已经更新到 Pascal。其实,N 家作为卖游戏显卡的主,出的了很多性能超越 Titan 的游戏卡(比如 GTX 1080,游戏跑分基本秒杀 Titan)。但是为啥 Titan X 一直是 AI 加速、特别是 training 的主要硬件外挂呢?有两个重要要原因。
一是,Titian 在单精度模式上拥有长足的优势。单精度指的是 16 位的浮点计算模式(FP16),而日常显卡是为双精度(32 位浮点)甚至更高的 FP64 模式设计的。Data scientist 的经验表明,深度学习往往仅需要单精度即可得到。大家可以从 (A+B)(C+D) = AC+AD+BC+DC 中可以简单地发现,FP32 所需要的硬件代价大约是 FP16 的 4 倍,可以做 FP16 的 Titian X 自然成了 AI 训练的首选。
第二个原因是,Titan 卡上的存储空间(DRAM)是 NV 卡里最高的,达到 12GB。就如本文一开头所述的,离计算单元越近且越大的 Memory 越值钱。这一点在大规模神经网络中尤为有用。多少个矩阵乘就这么避免了被「五马分尸」的命运呢。因此,凭着这 12GB 的显卡内存,Titan 的运行 AI 是对「云深不知处」的主机内存访问又降低了很多。
既然讲到了 GPU RAM,可能会有筒子们问 GPU 是在 GPU 芯片里的还是芯片外的?。答案是两者都是。从 Pascal 架构开始,GPU 所用的 DRAM 不再是与 GPU 分立的单独存储芯片,而采用 2.5D 封装的 HBM 结构,为了更近、更快、更宽(位宽)的访问存储器。详情请参考《矽说-那些年我们追的摩尔定律(二)》

(说了那么多 N 家,最后拿 A 家的 ppt 镇个楼)
「一遇泰坦误终身」介绍了在 GPU 的在 SIMD 基础上的另一绝技——多线程,并且在此基础上义务地给 titan X 神卡做了个软文。可是,难道整个 AI 的硬件就要被黄教主统治了么?其他的硬件机遇在哪里?篇幅有限,且听下回分解。
眼瞅着就要过年了,
这也应该是年前脑芯的最后一更,
小编在这里给大家拜早年了!







