 芝能智芯出品
芝能智芯出品随着人工智能(AI)技术的飞速发展,高带宽存储器(HBM)已成为满足高性能计算(HPC)和AI训练需求的关键硬件之一,HBM的复杂制造工艺、高成本和可靠性挑战限制了其广泛应用。
我们聚焦于HBM技术在AI时代的关键问题、创新方向,以及为芯片制造商和下游应用企业提供的核心建议。
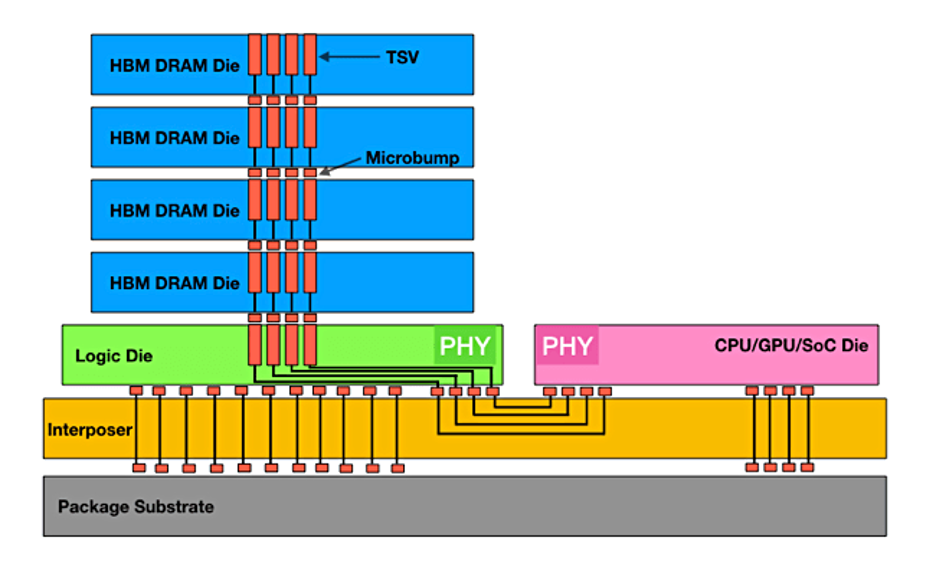
HBM的核心挑战在于其复杂的3D DRAM堆叠和高成本的先进封装工艺。包括硅通孔(TSV)、微凸块技术及回流焊工艺等环节均对制造精度和可靠性提出了极高要求。
尤其是TSV技术在中介层集成中的应用,不仅增加了封装成本,还带来了热机械应力、粘附问题以及微凸块失效等潜在风险。
从8层堆叠发展到12层、甚至16层的高密度设计,进一步增加了芯片翘曲和可靠性测试的难度。
为解决这些问题,三星、SK海力士等公司通过优化材料(如非导电膜)和焊接工艺,正在积极降低制造复杂性与良率瓶颈。
AI应用需要极高的内存带宽和低延迟,这使得HBM在数据中心等高端领域不可或缺。
然而,HBM3E的成本效益与广泛应用之间依然存在矛盾。例如,采用大规模回流焊技术的模塑底部填充工艺虽然在降低成本方面具备优势,但在实现更高堆叠密度时仍面临挑战。
与此同时,HBM4新标准带来的带宽翻倍和逻辑处理器集成趋势,虽然提升了性能,但也对成本控制提出了更大压力。
目前HBM市场由三星、SK海力士和美光三大巨头主导,各自采用不同的制造技术。三星依靠热压粘合的非导电薄膜技术,强调堆叠高度一致性;而SK海力士则通过模塑底部填充工艺在成本控制上占优。
此外,代工厂的参与也为HBM的基础芯片开发提供了更多可能性,例如台积电正为HBM提供更紧密的逻辑-内存整合方案。
这种多样化技术路径的背后是市场的巨大竞争压力,各厂商不仅要在成本、性能和良率间找到平衡点,还要满足AI训练和推理对实时性能的苛刻需求。
未来HBM的发展方向集中在内存与逻辑的整合,以及基于3D DRAM堆叠的性能优化。通过将内存控制器重新定位至基片,HBM4有望减少中介层的性能障碍,降低功耗并提升数据处理效率,JEDEC正在推动HBM4标准的制定,包括更高的堆叠密度、更快的传输速率及更大的封装容量。
这些创新将进一步缩短HBM产品的上市周期,但也需要克服材料、工艺与系统设计的多重挑战。
芯片制造商应进一步优化微凸块与TSV的加工工艺。例如,通过研发更高性能的非导电膜(NCF)和改进热压粘合技术,解决高层堆叠中翘曲与粘附问题。
此外,可以通过引入混合键合技术替代传统微凸块工艺,突破良率瓶颈并简化制造流程。
HBM的复杂制造需要代工厂、封装厂与材料供应商的深度协作。建议芯片企业与代工厂在逻辑-内存整合上展开联合研发,同时与JEDEC等标准制定机构协作,加速HBM4标准的落地。通过标准化和工艺共享,推动整个产业链的成本优化与技术迭代。
随着AI模型参数规模的持续增长,针对AI定制化需求的HBM开发将是未来的关键方向。
芯片企业需与AI厂商深度合作,在功耗、性能和面积(PPA)优化方面提供量身定制的解决方案。例如,为AI推理设计轻量化HBM模块,为训练任务开发高堆叠高带宽方案,满足不同场景的性能需求。
HBM市场的竞争正逐步从传统DRAM技术转向先进封装方案的创新。企业需要加大对2.5D与3D封装技术的研发投入,例如提升异构集成模块的可靠性与散热性能,通过引入大规模回流焊与R-LAB技术,降低中介层厚度并提升工艺兼容性,以抢占新一代HBM的市场制高点。
HBM作为AI与HPC领域的核心技术,正迎来一轮前所未有的技术变革与市场扩展期。尽管复杂制造工艺和高成本仍是当前的主要障碍,但随着新一代HBM4标准的制定和逻辑内存整合方案的推进,行业有望在未来两到三年内实现性能与经济性的突破平衡。
对于芯片制造商来说,唯有在制造工艺、产业协作和市场需求三方面协同发力,才能在这场技术竞赛中立于不败之地。
通过深耕AI场景的定制化需求、推动工艺优化与标准化进程,HBM的市场潜力将得到更大释放,为AI时代的计算需求提供强有力的支撑。
——芝能汽车










