本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博ID:唐僧_huangliang,以便更好地与读者互动。
差不多伴随着
Xeon SP
这一代,我看到
2U 4
节点服务器在结构设计上出现两个分支:
a.
传统的驱动器前置,节点从后端抽换;
b.
“盘
-
节点一体”前置,网络、
PCIe I/O
走机箱后端。
为什么出现这种分支,它们各有什么好处,又面临哪些限制呢?这就是我在本文中要跟大家讨论的。
首先更正一点,在昨天的《
2U 4
节点
Xeon SP
服务器
(
上
)
:
PowerEdge C6420
更受重视
》一文中,有朋友留言“
XXV710
支持
iWARP
的驱动
i40iw
已经有了”,不知
Intel
还会不会有专门的新款
25GbE
网卡控制器出来?
另外在最后一张照片中出现的白色
PCIe
扩展卡连接器,也有内行朋友认出是
OCP
规范定义的
Mezz
(网卡)
连接器。如下图:

固定在节点主板上那块就是
OCP Mezz
卡,使
C6420
继续带有一定互联网
/
云计算的风格。在它的上方还可以支持
另一块
PCIe Mezz
扩展卡,除了网卡之外,这个位置应该还可以通过转接套件来支持
mini PERC RAID
卡
。
除了
M.2 SSD
启动盘
之外,每个
C6420
节点
还可以支持
3
块
PCIe
扩展卡
(含
SAS RAID
卡
/HBA
)。
此外,该
2U 4
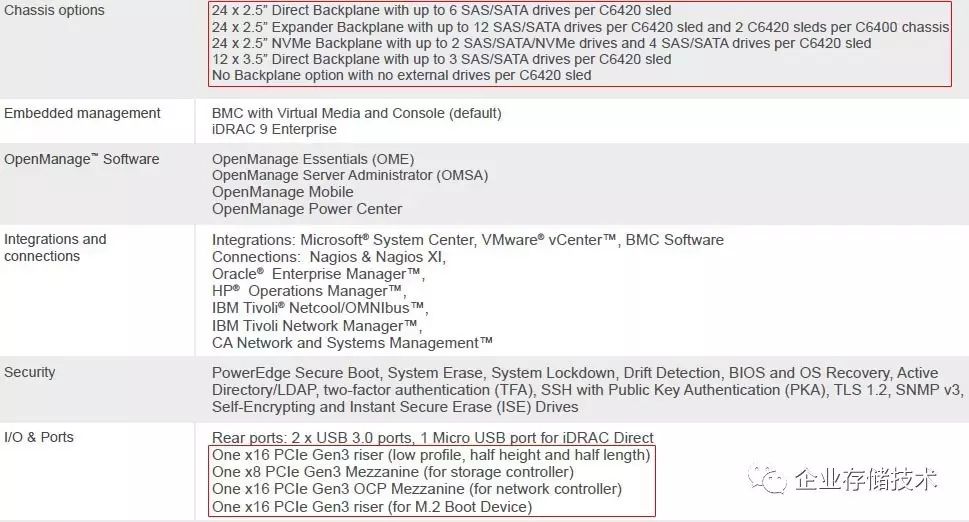
节点服务器支持的盘位,可以有以下几种选择:
-
24 x 2.5
英寸直通背板(每节点
6
个
SAS/SATA
驱动器);
-
24 x 2.5
英寸每节点
12
盘(
C6400
机箱中配
2
个节点,偏存储应用);
-
24 x 2.5
英寸每节点
2
个
SAS/SATA/NVMe + 4
个
SAS/SATA
;
-
12
个
3.5
英寸直通背板(每节点
3
个
SAS/SATA
大盘);
-
无背板前面板无驱动器。
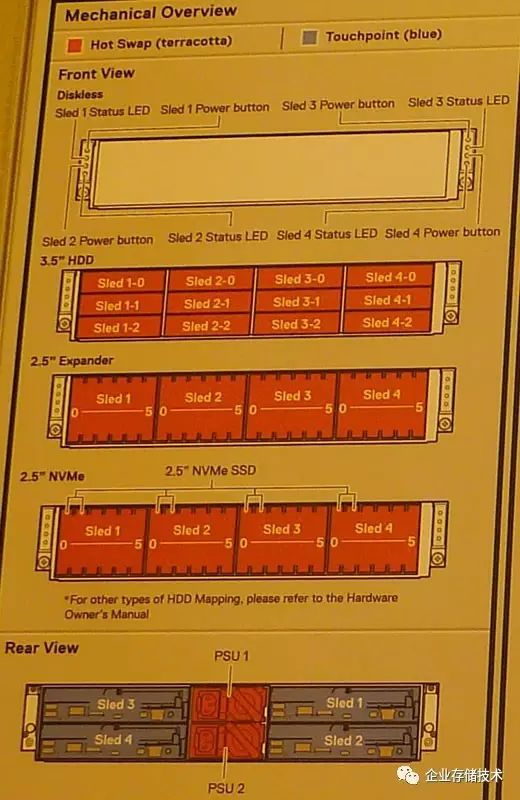
也许有朋友注意到,还有的
2U 4
节点服务器可以支持全部
24
个
NVMe SSD
的配置,也就是每节点
6
个。那么这里面有什么讲究吗?
1
、线缆连接复杂度
传统方式下,每个
SATA
接口的信号线是
7pin
,如果每节点
6
块盘总线缆
pin
数大约是
42
。比这再多一点走线负担也还好。

这台
PowerEdge C6420
使用的
SATA
连接器
与
R940
背板和
R640
(详见:《
Dell PowerEdge R640
:
NVMe
直连、
NDC
网卡、
PERC10
一览
》)上的
宽端口
PCIe
(
x8
)物理外形差不多
。这样一束线缆也能满足
SATA
硬盘
/SSD
直通连接的需求,如果换成
SASRAID
卡
/HBA
,
x4/x8 lane
连接到背板的复杂度与之类似。
而如果换成每节点
6
个
U.2
热插拔
NVMe SSD
支持,这样的连接器线缆就要
3
组,在
2U 4
节点比较拥挤的空间中走线可能就有些挑战了。
在
Xeon Scalable
这一代
2U 4
节点服务器中,我看到有几款没有采用传统的结构设计,而是将驱动器热插拔背板拆分,
把每个节点和对应的盘做成一体化
,就像下图这样。
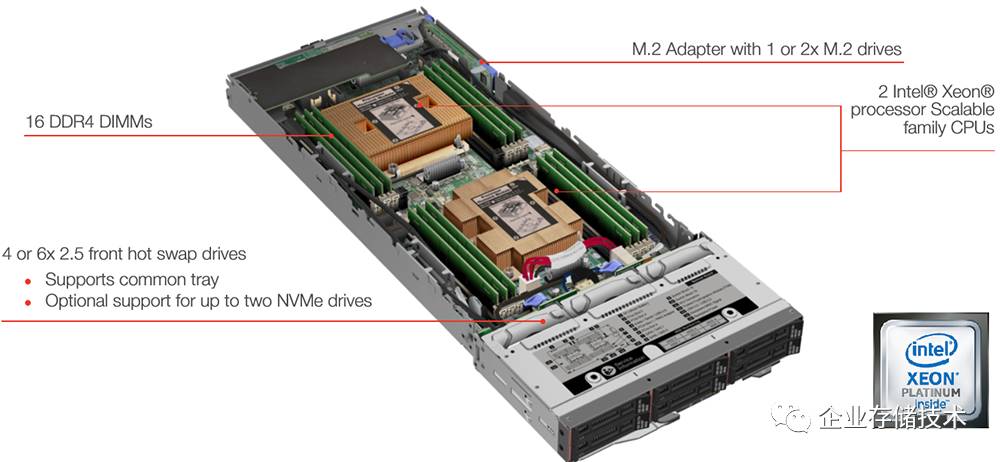
这里以某厂商的
2U 4
节点机型设计来举例,请留一下
内存插槽数和
CPU
散热器的宽度
,这个我在后面还会讨论。不过它支持的
NVMe SSD
也只有每节点
2
个,为什么类似结构也有区别呢?除了散热,可能还要
结合应用需求来分析
。
2
、
205W CPU+
全
NVMe
散热设计难度
如果是普通
2U
双路服务器支持
24
个
NVMe SSD
比较正常,我在《
Dell PowerEdge R740xd
解析:服务器只看参数那就错了
》中也没有特别提到散热的压力。而
2U 4
节点
CPU
的功率密度是普通
2U
的
4
倍
,再加上
Xeon SP
有
205W TDP
的型号,如果前面板满配
24
个
25W
的
SSD
散热吃的消吗?
搞过散热设计
/
测试的朋友应该熟悉
T-case
、
T-rise
这些指标,如果
35
℃
的进风温度服务器组件无法达到正常工作范围,还有一个取巧的办法——
将环境温度要求下调至
30
℃、乃至
20
℃
…
当然这样做不是没有代价,要求机房温度更低就意味着
空调散热成本的上升,
PUE
不会太好看
,至于
Fresh-Air
新风之类的更不用考虑了。
上述观点仅供参考,具体指标请咨询服务器厂商,我只是想指出散热设计也会有天花板。
3
、
3.5
英寸大盘支持

如果采用盘
-
节点一体化设计,就只能做成最多
6
个
2.5
英寸驱动器支持了,
3.5
英寸大盘不太好放。

上图为
3.5
寸驱动器配置的
PowerEdge C6420
。一些超融合用户喜欢用
1
个
SSD
(加转换托架后
3.5
英寸)
+ 2
个大容量硬盘的混合存储
,主要是因为
2.5
寸硬盘的
性价比
没有这么高。
4
、网络选择、
PCIe
模块设计和
KVM
连接

这个是前面列出的某厂商
2U 4
节点机型后端。在中间的电源上方,有
8
个网口直通连接到
4
个服务器节点。两侧有可抽出维护的
PCIe
扩展卡模块,提供每节点
1-2
块
PCIe
卡的选项。
相比之下,传统的
2U 4
节点设计的网口和
PCIe
扩展卡都是随节点一体化的。在新形态设计中,
单独的以太网和
PCIe I/O
模块
应该会带来一些成本上升。
至于
4
个节点的管理控制,可以通过上图中的千兆管理网口,此外还有另一种
KVM
连接支持后面会提到。

在
7
月
12
日
Intel Xeon Scalable
发布会上,
Celestica
(天弘)的
2U 4
节点平台也属于“盘
-
节点一体”的设计,并号称支持全
NVMe
。
我们注意到,
机箱后端布局可以有更多个性化
。如上图,每个
NODEx IO
模块抽出来之后,可以安装
3
个
PCIe
扩展卡。此外还有冗余电源和
SYSTEM I/O
的位置,后者是集中管理模块。大家可能看出来了,没有专门的网口设计,也就是至少要插一块
PCIe
网卡了。

写到这里,让我想起了
Dell
PowerEdge FX2
模块化服务器平台。由于它前端最多支持
8
个双路
Xeon E5
服务器节点(
FC430
),后部
8
个可单独维护的
PCIe
扩展卡位可以做
1
对
1
映射。如果配置为
2U 4
个
FC630
节点,也可以配置为
1
对
2 PCIe
映射,中间支持
PCIe Switch
对
I/O
卡热插拔不知是否有帮助?
除了冗余电源之外,
PowerEdge FX2
还提供了
2
个网络接口模块,可选直通或者交换功能
(多种版本)。一方面
16
网口可以确保
8
个节点都具备冗余网络连接,如果配交换的话机箱内的东西流量就不需要到外部交换机解决了。
左上角还有一个
CMC
管理模块
,熟悉
Dell
刀片服务器的朋友应该对
CMC
不陌生了。

PowerEdge FX2
的
CMC
管理模块
在
M1000e
刀片机箱中
CMC
模块有
2
个,
FX2
的设计应该是由空间限制和定位决定。
CMC
或者集中管理网口如果万一遇到问题,应该不会影响服务器节点的运行,在线更换模块后可以恢复对各节点
BMC
的管理。
下面再拿
PowerEdge FC630
中的
PCIe Mezz
卡来举个例子:
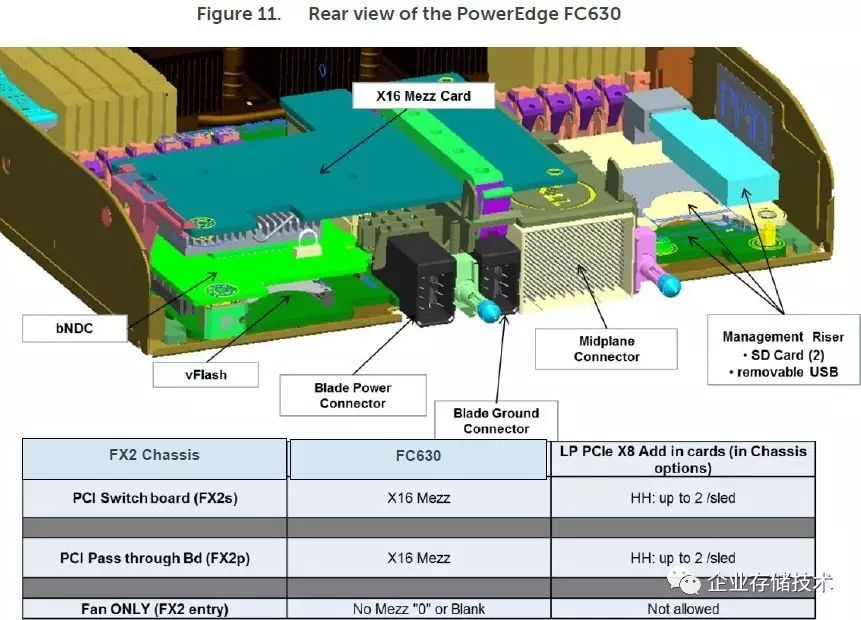
FX2
机箱可以选择
PCIe
交换板、直通板和
Fan ONLY
(无
PCIe
扩展)三种规格,
Mezz
在这里的作用就是将
PCIe
信号转接到直通板或者交换板。目前
普通的
2U 4
节点机型应该都没有
PCIe Switch
,因为
FX2
的模块化还有另外一种用法——将
FD332
中的
2
个
PERC RAID
卡单元与计算节点连接(如下图),这里面就牵涉到对
PCIe Switch
的配置。

引用自《
数据中心选址贵阳理由:天、地、电
》一文,里面对
PowerEdge FX2
模块化存储单元
FD332
的设计做了简要解析。
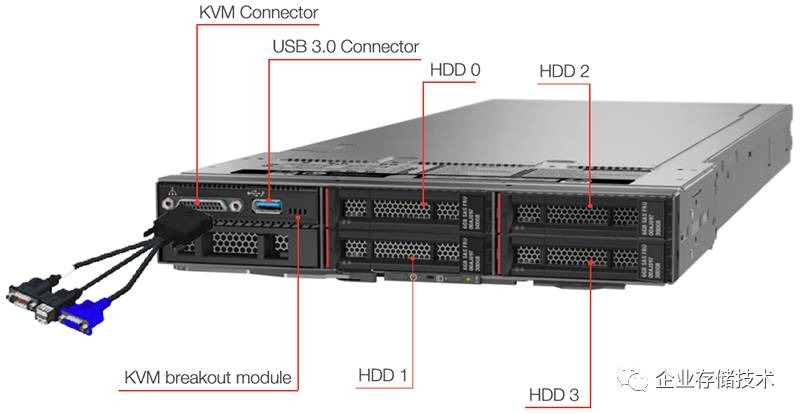
这张图描述的设计,是在计算节点的前面板增加
KVM
和
USB 3.0
接口。如此一来就可以直接本地访问,代价是牺牲
2
个
2.5
英寸盘位,从每节点
6
盘位降至
4
盘位。
相比之下,像
PowerEdge C6420
、
C6320
这样的传统结构设计,就不会有这种纠结。
5
、内存密度——又回到散热的话题
记得在
Intel
发布会上午看完各家机器之后,我在
EPSD
展台与
Intel
一位美女聊了会。其中就谈到为什么有的
2U 4
节点服务器能做到
24
个内存插槽?就像下图中这款每颗
CPU
两侧各有
6
个
DIMM
。

这家ODM的节点,由于
CPU
散热器宽度受限,于是在风道后侧那个选择高鳍片密度以增加散热面积,而前面离我们较近的采用低密度散热片尽量减少风阻和温升(为后侧的
CPU
创造好条件)——散热能力的不足则靠热管和伸出两侧的鳍片来弥补。
看过上一篇的朋友应该知道
C6420
是每节点
16
个内存槽,比较宽松的同时位于风道后方的
CPU
散热尺寸可以加宽(这样做的原因我在《
2U 4
节点
Xeon SP
服务器
(
上
)
:
PowerEdge C6420
更受重视
》中解释过了)。
Dell
不是没有做
24
个
DIMM
的能力,因为
PoweEdgeFX2
平台上的
FC630
就做到了,
CPU
散热器宽度同样受限,要知道新一代
Xeon SP
还有
205W
和
165W
的
CPU
。
我想借此说明一点:内存槽数量等相关
参数并不是越高越好
,普通用户很难分辨出类似的高密度设计的局限和代价在哪里。比如近日另一家宣传的
4U 100
盘位服务器,即便散热能做好,这种高密度部署对共振、机柜供电和地板承重也提出了比较苛刻的要求。
6
、满足应用需求才是王道
回到
2U 4
节点服务器的核心应用——
HPC
、云服务提供商和超融合
领域,基本上
CPU
的大部分资源都要跑计算或者虚拟机,能够用来支撑存储
IOPS
的相对有限。因此每节点
2
个
NVMe SSD
加上
4
个
SAS/SATA
硬盘或者
SSD
的配置应该能满足绝大部分需求,我想这也是许多厂商不急于上全
NVMe
配置的原因。
比如以性能著称的
ServerSAN
软件
ScaleIO
,目前跑到每节点
20
万
IOPS
已经相当快了,分布式存储的扩展性和弹性虽好,但其数据保护(副本等)和企业级特性的开销还是制约着单节点性能的发挥。这一点和我在《
Dell EMC
透露
NVMe
战略,为什么阵列还要等半年?
》中讨论过传统存储有相似之处。
另一方面,目前使用
SPDK
那样的用户态
polling
的还比较少。对于有极致服务器本地
IOPS
需求的用户,不妨考虑下
PowerEdge R640
、
R740
这样的传统
1U/2U
机型,
8-24
个
NVMe SSD
支持还是比较过瘾的。
扩展阅读《
SPDK
实战、
QoS
延时验证:
Intel Optane P4800X
评测
(5)
》
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
huangliang_storage

长按二维码可直接识别关注
历史文章汇总
(传送门):
http://chuansong.me/account/huangliang_storage





