
在机器学习中,从原始数据到经过优化的模型的路径由数据预处理技术铺就,这些数据预处理的技术为成功奠定了基础。数据科学家和机器学习工程师通常花费大量时间准备数据,因为干净、结构良好且经过精心设计的数据能够显著提升模型的性能和洞察力。
“垃圾进,垃圾出。”这是每位数据科学家必须理解的重要原则。接下来,我们将探讨每个数据科学家必须掌握的五种关键预处理技术:处理缺失数据、缩放与规范化、编码分类数据、特征工程和处理不平衡数据。这些主题对于将杂乱的真实数据集转化为机器学习算法可以有效学习的形式至关重要。
1. 处理缺失数据
缺失数据是现实世界机器学习项目中不可避免的挑战。数据集经常由于传感器故障、人工错误或其他原因而出现缺失值。如果处理不当,缺失数据可能导致模型预测偏差、误导性见解,甚至训练失败。在训练任何模型之前,务必以保留数据集完整性的方式处理缺失值。
本节将将探讨诸如逐行删除、均值/众数插补以及多变量插补等策略。
缺失数据的类型:
-
完全随机缺失 (MCAR)
:缺失数据点的概率与任何其他观察到或未观察到的样本无关。在这种情况下,删除数据可能不会引入偏差,因为它是随机的。
-
随机缺失 (MAR)
:数据点的缺失与其他观察到的变量有关,但与缺失值本身无关。这在调查或人口统计数据集中很常见,例如缺失的收入数据可能与教育水平相关。
-
非随机缺失 (MNAR)
:缺失与未观察到的数据本身相关。例如,高收入者可能不愿透露自己的收入,这如果处理不当会导致数据集的偏差。
策略 1:逐行删除(移除缺失数据)
处理缺失数据的最简单方法是删除包含缺失值的行。虽然这种方法适用于缺失条目较少的小数据集,但对于缺失数据频繁的大数据集而言,它实用性较低,因为会导致有价值信息的损失。
最佳实践:谨慎使用逐行删除。当缺失数据是完全随机缺失(MCAR)时,才适合使用此方法,或者在删除行不会对数据集的完整性产生重大影响时使用。
策略 2:插补方法(填补缺失数据)
如果无法删除数据,可以使用统计指标(例如均值、中位数或众数)来插补(即填补)缺失值。插补允许模型利用所有可用信息,确保不会丢弃任何数据。
通常使用该列观察值的均值(或中位数)来插补数值数据。当数据呈对称分布时,这种方法效果良好,但在偏态分布中可能会引入偏差。
最佳实践:均值插补对于偏态较小的数值数据是有效的。对于偏态数据,考虑使用中位数进行插补。
策略 3:类别数据的众数插补
无法使用均值对类别数据(例如,性别或国家)进行插补,要使用众数。因此,我们用出现频率最高的类别填补缺失值。
最佳实践:众数插补适用于类别数据,特别是性别或国家等特征,其中最频繁的值具有实际意义。
策略 4:高级技术 — 链式方程的多元插补(MICE)
简单的插补方法如均值或众数可能会引入偏差,特别是在复杂数据集中。在这种情况下,我们可以使用链式方程的多元插补(MICE)。该技术基于多个特征之间的关系来预测缺失值。
MICE 迭代地将每个有缺失值的特征建模为其他特征的函数,使用回归或其他预测模型。这种方法更加准确,并更好地考虑数据的结构。
最佳实践:在特征之间存在复杂相互依赖关系的数据集中使用 MICE,特别是在简单插补可能引入偏差时。
处理缺失数据是预处理过程中的关键步骤。虽然逐行删除在某些情况下可能有效,但通常需要插补缺失值以保留数据集中有价值的信息。根据数据的特性,选择合适的插补策略;可以选择简单的均值/众数插补方法,或者使用 MICE 等高级方法以获得更高的准确性。
关键要点:
合适的插补策略能够保持数据集的完整性,并为构建稳健的机器学习模型奠定坚实基础。
2.缩放和归一化
许多机器学习算法,特别是涉及基于距离的度量(例如 k 最近邻或支持向量机)或基于梯度的优化器(例如逻辑回归和神经网络),假设特征在相似的尺度上。
当特征的范围差异较大时(例如,一个特征的范围为 [0, 1],而另一个特征的范围为 [1,000, 100,000]),可能会误导这些算法,因为它们会不成比例地权衡特征。
可以通过应用缩放和归一化来解决这个问题。这些方法根据数据分布和机器学习模型的不同,调整特征值。
缩放和归一化主要区别:
为什么缩放很重要?某些算法对输入特征的相对尺度非常敏感:
-
基于距离的算法,如 k 最近邻和 k-means 聚类,假设特征具有相似的尺度,因为它们依赖于欧几里得距离。如果一个特征的范围比其他特征更大,它将主导距离度量。
-
基于梯度的算法,如神经网络和逻辑回归,受益于标准化数据,以防止梯度下降振荡并缓慢收敛。
-
其他算法(例如决策树)不受缩放影响,因为它们基于不依赖于距离度量的分裂标准。
Min-Max 归一化
Min-Max 是最简单且使用最广泛的归一化方法,它将特征值重新缩放到一个固定范围,通常是 [0, 1],具体使用以下公式:
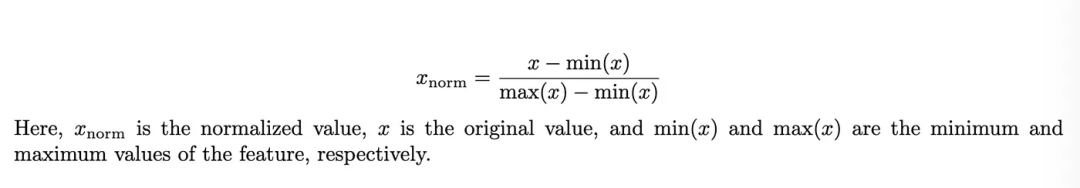
Z-Score 标准化(标准缩放)
当数据遵循高斯分布或其期望值接近零时,Z-Score 标准化更为合适。为什么使用 Z-Score 标准化?
-
确保每个特征对模型的贡献是均等的。
-
对于假设数据呈正态分布的算法非常有帮助。

Min-Max 标准化最适合在以下情况下使用:
另一方面,Z-Score 标准化更适合在以下情况下使用:
潜在陷阱与最佳实践
缩放和标准化至关重要,缩放和标准化是许多机器学习算法的重要预处理步骤。Min-Max 标准化在保留数据关系方面表现出色(例如,在图像数据或神经网络中);Z-Score 标准化适用于需要特征具有相似统计特性的基于距离或基于梯度的模型。
关键要点:
通过正确应用这些技术,可以确保模型具有最佳学习基础,从而提高性能和更好的泛化能力。
3.编码分类数据
大多数机器学习算法,特别是基于数值计算的算法,期望输入为数值。然而,现实世界的数据集往往包含分类数据——如性别、国家或产品类型——在训练机器学习模型之前,必须将其转换为数值形式:编码。
挑战在于确保编码能够正确捕捉分类变量之间的关系,而不引入偏差。例如,给类别分配任意数字可能会无意中暗示它们之间存在某种排序,无论这种排序是否真实存在。
接下来,我们将探讨几种编码技术,如标签编码(Label Encoding)和独热编码(One-Hot Encoding),并讨论每种方法最适合的情况。我们还将提及更高级的技术,如目标编码(Target Encoding)。
标签编码
标签编码为每个类别分配一个唯一的整数。尽管这种方法简单,但它主要适用于有序变量(类别具有内在顺序)。对于无序变量(类别没有顺序),它可能引入意外的有序关系。
education: {'高中': 0, '本科': 1, '硕士': 2}
标签编码通常在分类变量具有有序关系时使用(即类别具有内在排名,例如 [低、中、高])。在这种情况下,数值编码保留了顺序。通过明确定义顺序,编码值保持数据中的固有排名,这对可能将数值视为具有相对意义的模型至关重要。这确保编码正确反映特征的有序性质,并支持有意义的模型训练。
对于名义(无序)变量,谨慎使用标签编码,因为它可能引入虚假的顺序感。
独热编码(One-Hot Encoding)
这种方法将每个类别转换为一个新的二进制列(或特征)。每一列对应一个特定的类别,如果该类别存在,则标记为1,否则标记为0,适用于名义变量。
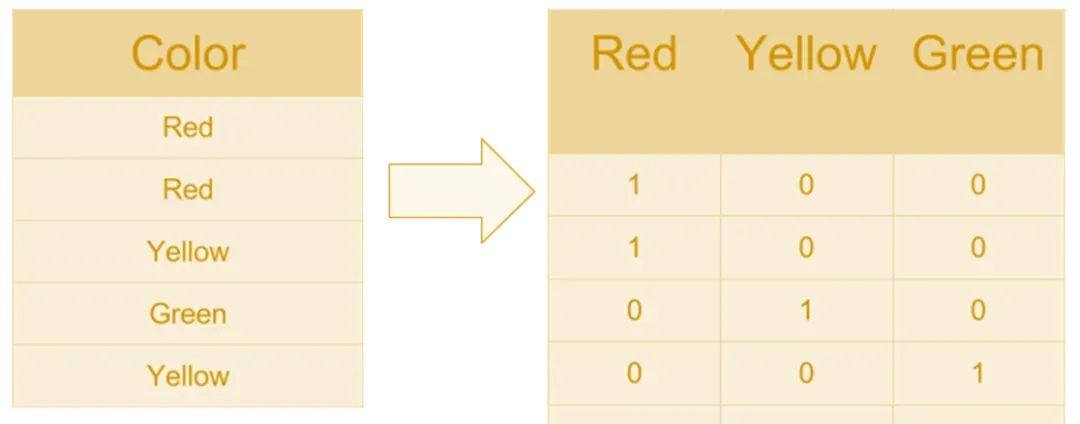
独热编码适用于名义(无序)变量(例如,性别、国家或颜色)。这种方法避免了引入错误的顺序关系。需要注意的是,独热编码可能会显著增加数据集的维度,尤其是在你有很多独特类别时。
独热编码适用于具有少量独特类别的数据集。然而,当应用于具有许多独特值的列时,它可能会显著增加数据的维度,使得模型更容易过拟合或训练成本更高。
高级编码技术:目标编码
这种方法根据每个类别的目标变量的均值对类别进行编码。在类别特征具有许多级别的情况下非常有用,但如果处理不当,可能会引入过拟合。





