问题导读
1.你认为spark该如何入门?
2.你认为spark入门编程需要哪些步骤?
3.本文介绍了spark哪些编程知识?
转载注明链接:
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21959

spark学习一般都具有hadoop基础,所以学习起来更容易多了。如果没有基础,可以参考
零基础学习hadoop到上手工作线路指导(初级篇)
。具有基础之后,一般都是按照官网或则视频、或则文档,比如搭建spark,运行spark例子。后面就不知道做什么了。这里整体梳理一下。希望对大家有所帮助。
1.spark场景
在入门spark之前,首先对spark有些基本的了解。比如spark场景,spark概念等。推荐参考
Spark简介:适用场景、核心概念、创建RDD、支持语言等介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9389
2.spark部署
首先还是说些基础性的内容,非零基础的同学,可以跳过。
首先还是spark环境的搭建。
about云日志分析项目准备6:Hadoop、Spark集群搭建
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20620
spark环境搭建完毕,例子运行完毕。后面就不知道干啥了。
这时候我们就需要了解spark。
从不同角度,可以有多种不同的方式:如果我们从实战工作的角度,下面我们就需要了解开发方面的知识
如果我们从知识、理论的角度,我们就需要了解spark生态系统
下面我们从不同角度来介绍
3.spark实战
3.1spark开发环境
比如我们从实战的角度,当我们部署完毕,下面我们就可以接触开发方面的知识。
对于开发,当然是首先是开发工具,比如eclipse,IDEA。对于eclipse和IDEA两个都有选择的,看你使用那个更顺手些。
下面是个人总结希望对大家有帮助[
二次修改新增内容
]
spark开发环境详细教程1:IntelliJ IDEA使用详细说明
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22320
spark开发环境详细教程2:window下sbt库的设置
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22409
spark开发环境详细教程3:IntelliJ IDEA创建项目
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22410
spark开发环境详细教程4:创建spark streaming应用程序
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22465
更多了解即可:
Spark集成开发环境搭建-eclipse
http://www.aboutyun.com/forum.php?mod=viewthread&tid=6772
用IDEA开发spark,源码提交任务到YARN
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20316
Spark1.0.0 开发环境快速搭建
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8403
spark开发环境中,如何将源码打包提交到集群
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20979
田毅-Spark开发及本地环境搭建指南
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20313
Spark 开发环境IntelliJ IDEA图文教程、视频系统教程
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10122
3.2spark开发基础
开发环境中写代码,或则写代码的时候,遇到个严重的问题,Scala还不会。这时候我们就需要补Scala的知识。如果是会Java或则其它语言,可能会阅读C,.net,甚至Python,但是Scala,你可能会遇到困难,因为里面各种符号和关键字,所以我们需要真正的学习下Scala。下面内容,是个人的总结,仅供参考
#######################
about云spark开发基础之Scala快餐
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20303
spark开发基础之从Scala符号入门Scala
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20159
spark开发基础之从关键字入门Scala
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20223
更多内容:
spark开发基础之Scala快餐:开发环境Intellij IDEA 快捷键整理【收藏备查】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20380
学习Scala的过程中,参考了以下资料
《快学Scala》完整版书籍分享
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8713
scala入门视频【限时下载】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12434
更多可以搜索Scala
http://so.aboutyun.com/
#######################
相信上面的资料,足以让你搞懂Scala。Scala会了,开发环境、代码都写好了,下面我们就需要打包了。该如何打包。这里打包的方式有两种:
1.maven
2.sbt
有的同学要问,哪种方式更好。其实两种都可以,你熟悉那个就使用那个即可。
下面提供一些资料
scala eclipse sbt( Simple Build Tool) 应用程序开发
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9340
使用maven编译Spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=11746
更多资料
Spark大师之路:使用maven编译Spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=10842
用SBT编译Spark的WordCount程序
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8587
如何用maven构建spark
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12261
3.3spark开发知识
spark 开发包括spark core的相关组件及运算,还有spark streaming,spark sql,spark mlib,GraphX.
###########################
下面的知识是关于spark1.x的,关于1.x其实有了基础,那么spark2.x学习来是非常快的。那么他们之间的区别在什么地方?最大的区别在编程方面是spark context,sqlcontext,hive context,都使用一个类即可,那就是SparkSession。他的编程是非常方便的。比如
通过SparkSession如何创建rdd,通过下面即可

再比如如何执行spark sql
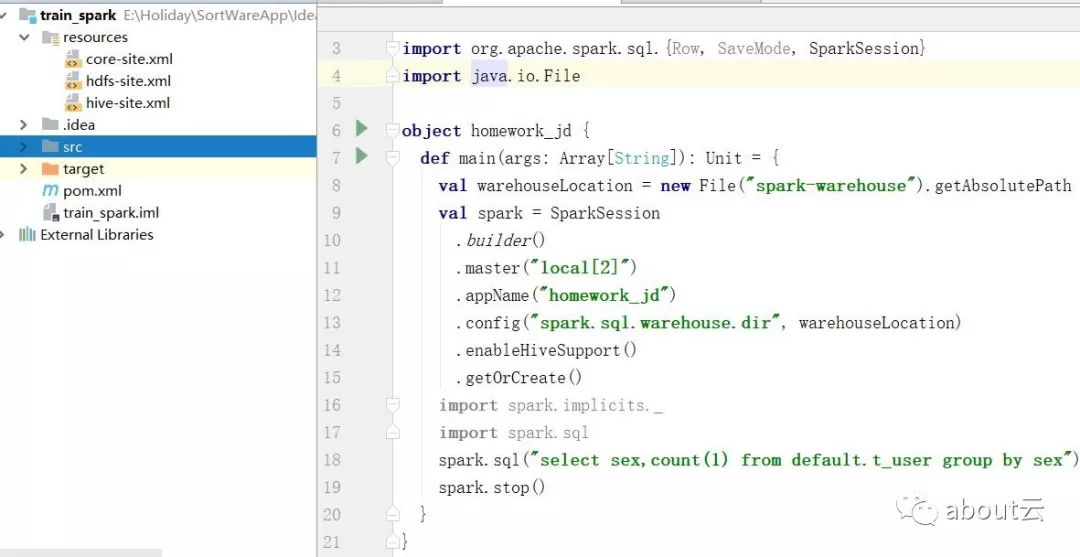
更多参考:
spark2:SparkSession思考与总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23381
SparkSession使用方法介绍【spark2.0】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=19632
spark2使用遇到问题总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=24050
spark2.0文档【2016英文】
http://www.aboutyun.com/forum.php?mod=viewthread&tid=18970
spark2 sql读取数据源编程学习样例1:程序入口、功能等知识详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23484
spark2 sql读取数据源编程学习样例2:函数实现详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23489
使用spark2 sql的方式有哪些
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23541
spark2之DataFrame如何保存【持久化】为表
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23523
spark2 sql编程样例:sql操作
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23501
spark2 sql读取json文件的格式要求
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23478
spark2 sql读取json文件的格式要求续:如何查询数据
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23483
spark2的SparkSession思考与总结2:SparkSession包含哪些函数及功能介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23407
spark2.2以后版本任务调度将增加黑名单机制
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23346
##########################
3.3.1spark 编程
说到spark编程,有一个不能绕过的SparkContext,相信如果你接触过spark程序,都会见到SparkContext。那么他的作用是什么?
SparkContext其实是连接集群以及获取spark配置文件信息,然后运行在集群中。如下面程序可供参考
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
5
6
7
|
import
org.apache.spark.SparkConf
import
org.apache.spark.SparkContext
val
conf
=
new
SparkConf().setAppName(“MySparkDriverApp”).setMaster(“spark
:
val
sc
=
new
SparkContext(conf)
|
下面图示为SparkContext作用
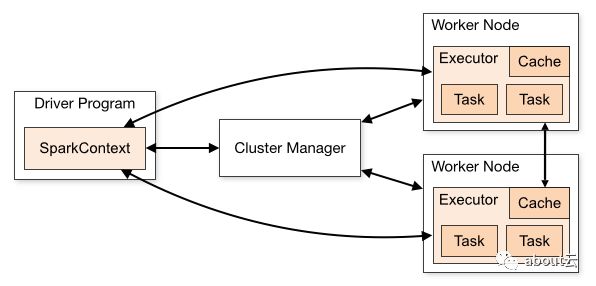
当然还有 SQLContext 和HiveContext作用是类似的,同理还有hadoop的Context,它们的作用一般都是全局的。除了SparkContext,还有Master、worker、DAGScheduler、TaskScheduler、Executor、Shuffle、BlockManager等,留到后面理论部分。这里的入门更注重实战操作
我们通过代码连接上集群,下面就该各种内存运算了。
比如rdd,dataframe,DataSet。如果你接触过spark,相信rdd是经常看到的,DataFrame是后来加上的。但是他们具体是什么。可以详细参考
spark core组件:RDD、DataFrame和DataSet介绍、场景与比较
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20902
看到上面我们其实可能对它们还没有认识到本质,其实他们就是内存的数据结构。那么数据结构相信我们应该都了解过,最简单、我们经常接触的就是数组了。而rdd,跟数组有一个相同的地方,都是用来装数据的,只不过复杂度不太一样而已。对于已经了解过人来说,这是理所当然的。这对于初学者来说,认识到这个程度,rdd就已经不再神秘了。那么DataFrame同样也是,DataFrame是一种以RDD为基础的分布式数据集.
rdd和DataFrame在spark编程中是经常用到的,那么该如何得到rdd,该如何创建DataFrame,他们之间该如何转换。
创建rdd有三种方式,
1.从scala集合中创建RDD
2.从本地文件系统创建RDD
3.从HDFS创建RDD
详细参考
spark小知识总结
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20920
如何创建dataframe
df
当然还可以通过rdd转换而来,通过toDF()函数实现
rdd.toDF()
dataframe同样也可以转换为rdd,通过.rdd即可实现
如下面
val rdd = df.toJSON.rdd
为了更好的理解,在看下面例子
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
|
先创建一个类
case
class
Person(name
:
String, age
:
Int)
然后将Rdd转换成DataFrame
val
people
=
sc.textFile(
"/usr/people.txt"
).map(
_
.split(
","
)).map(p
=
> Person(p(
0
), p(
1
).trim.toInt)).toDF()
|
即为rdd转换为dataframe.
RDD和DataFrame各种操作
上面只是简单的操作,更多还有
rdd的action和Transformation
Actions操作如:reduce,collect,count,foreach等
Transformation如,map,filter等
更多参考
Spark RDD详解
http://www.aboutyun.com/forum.php?mod=viewthread&tid=7214
DataFrame同理
DataFrame 的函数
collect,collectAsList等
dataframe的基本操作
如
cache,
columns
等
更多参考
spark DataFrame 的函数|基本操作|集成查询记录
http://www.aboutyun.com/blog-1330-3165.html
spark数据库操作
很多初级入门的同学,想在spark中操作数据库,比如讲rdd或则dataframe数据导出到mysql或则oracle中。但是让他们比较困惑的是,该如何在spark中将他们导出到关系数据库中,spark中是否有这样的类。这是因为对编程的理解不够造成的误解。在spark程序中,如果操作数据库,spark是不会提供这样的类的,直接引入操作mysql的库即可,比如jdbc,odbc等。
比如下面Spark通过JdbcRDD整合 Mysql(JdbcRDD)开发
http://www.aboutyun.com/forum.php?mod=viewthread&tid=9826
更多可百度。
经常遇到的问题
在操作数据中,很多同学遇到不能序列化的问题。因为类本身没有序列化.所以变量的定义与使用最好在同一个地方。
想了解更详细,可参考
不能序列化解决方法 org.apache.spark.sparkException:Task not serializable
http://www.aboutyun.com/home.php?mod=space&uid=29&do=blog&id=3362
小总结
如果上面已经都会了,那么spark基本编程和做spark相关项目外加一些个人经验相信应该没有问题。
3.3.2spark sql编程
spark sql为何会产生。原因很多,比如用spark编程完成比较繁琐,需要多行代码来完成,spark sql写一句sql就能搞定了。那么spark sql该如何使用。
1.初始化spark sql
为了开始spark sql,我们需要添加一些imports 到我们程序。如下面例子1
例子1Scala SQL imports
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
|
import
org.apache.spark.sql.hive.HiveContext
import
org.apache.spark.sql.SQLContext
|
下面引用一个例子
首先在maven项目的pom.xml中添加Spark SQL的依赖。
org.apache.spark
spark-sql_2.10
1.5.2
[Scala]
纯文本查看
复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package
[url
=
http
:
import
org.apache.spark.{SparkConf, SparkContext}
import
org.apache.spark.sql.SQLContext
object
InferringSchema {
def
main(args
:
Array[String]) {
val
conf
=
new
SparkConf().setAppName(
"aboutyun"
)
val
sc
=
new
SparkContext(conf)
val
sqlContext
=
new
SQLContext(sc)
val
lineRDD
=
sc.textFile(args(
0
)).map(
_
.split(
" "
))
val
personRDD
=
lineRDD.map(x
=
> Person(x(
0
).toInt, x(
1
), x(
2
).toInt))
|





