来源:https://dahuasky.wordpress.com/
数星星的数学

小时候,在晴朗的夜里,我喜欢仰望星空,去数天上的星星——那是无忧无虑的快乐童年。长大后,当我们再度仰望苍穹,也许会思考一个不一样的问题:这点点繁星的分布是不是遵循什么数学规律呢?这个问题也许问得太不解风情了。但是,在这篇文章里,我希望向大家表达的是,这个问题会把我们带入一个比星空更为美丽的数学的世界。
探讨这个问题,不需要什么高深的方法。还是和我们小时候一样,我们从“数星星”做起。相比于整个夜空,每个星星是在太小太小了,所以,我们可以做一个简化的设定:把每颗星星看成是一个点——一个没有大小的点——在我们的讨论中,我们只关心星星的位置和数目,不关心它的大小和形状,更不会关心那上面也许存在的外星人。(在之后的连载中,还会讨论这些星星的重量,以及它们在历史长河中的产生,运动,和消亡。)
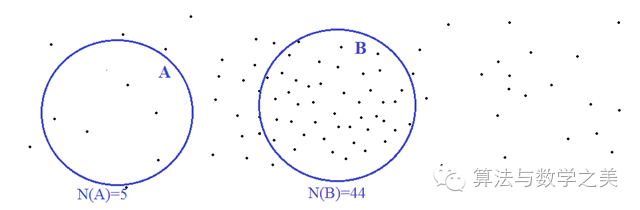
我们开始数星星。为了方便,我们把整个星空分成不相交的区域,然后分区数数。在上面这个图里面,我画出了两个区域:A 和 B。N(A)和N(B)分别表示,这两个区域里面的星星的个数。我们可以看到,星星的分布可能是不均匀的,有些地方稀疏一些,另外一些地方稠密一些。所以,虽然A和B的面积差不多,但是,里面包含的星星数目却相差好多倍。
由于各种各样的原因,我们每天看到的星空中星星的分布可能都在变化。即使同一个区域,里面包含的星星数目也可能是不确定的——这就是概率理论能发挥作用的时候了。对于每个给定的区域,我们认为里面的星星数目是个随机变量,比如上面所说的N(A)和N(B)。为了我们的讨论能够继续进行,需要做出一些简化假设。在这里,我们的假设很简单:
1. 对于任意两个不相交的区域A和B,N(A)和N(B)是独立的。
2. 两颗星星几乎肯定不会出现在同一个点上。
对于这两个假设,我需要做些说明。首先,请大家注意,除了说他们独立之外,我没有对N(A)和N(B)的分布形式作出任何假设——后面,我们会看到,为什么不需要假定它们是什么分布。另外,在第二个假设中“几乎肯定”(almost surely)这个术语在数学上是有严格定义的,某个事情“几乎肯定”会发生,表示,它们发生的概率是 1。
了解现代概率理论的朋友对于almost surely想必是司空见惯了。为了让对这个术语不太熟悉的朋友不产生误解,我还是在这里澄清一下。“几乎肯定发生”和“必然发生”在数学上是有所区别的。举个例子,我们在从 [0, 2] 这个区间的均匀分布中随便抽一个数 a,那么 a 刚刚好等于 1 的概率是多少呢?——是 0。所以,我们可以说,a “几乎肯定”不刚好等于 1。但是,我们不能说 a 必然不等于 1。
空间点过程
好了,继续回到我们的主题。
这个数星星的例子代表了一类非常广泛的随机过程——空间点过程(Point Processes)。具体来说,什么叫做一个空间点过程呢?我们知道,对于一个(实数值)随机变量,每次抽样(或者试验),得到的是一个实数;对于一个随机向量,每次从分布里面抽取的是一个向量。那么,一个空间点过程,每次抽样得到是在某个空间中的一个离散点集(里面有有限个或者可数无限个点)。在数星星的例子里面,这个空间就是“星空”了。一般来说,这个空间可以是任意的,比如实数集,二维空间,三维空间,曲面,甚至是无限维的函数空间。
最基本的空间点过程,叫做空间泊松过程(Spatial Poisson Process)——一个空间点过程,如果在不相交的区域中的计数是相互独立的,那么这个空间点过程就叫空间泊松过程。虽然,我们没有对N(A)的分布形式作出具体的设定。但是,仅仅凭着不相交区域内计数的独立性,我们就可以得到一个重要的结论:
对于任意的区域 A,在A里面的点的数目 N(A) 服从泊松分布(Poisson Distribution)。
这里说“任意区域”其实是不太严格的——在正式的数学定理中,泊松过程所基于的空间必须是一个测度空间(measure space),这里的区域A,必须是一个可测集(measurable set)。不熟悉测度理论的朋友可以不妨暂且认为这个区域是任意的吧——因为,在实际常见的几乎所有几何空间里,你能想象出来的集合都是可测集,而不可测的集合只存在于数学家的奇怪构造中。
为什么我们要讨论空间泊松过程呢?它究竟有什么用呢?在我非常有限的知识范围里,我觉得它起码有两个非常重要的意义:
1.在我们所生活的大千世界里,无数的自然现象和科学观测都可以很好地用空间泊松过程来建模和分析。除了天上的星星之外,还有很多很多:天上飞的鸟,水里游的鱼,街上走的人,空气中的分子,放射过程产生的粒子,桌上的灰尘,很多仪器产生的图像中的黑白噪点。
2.泊松过程是构造很多别的过程的理论根基所在。了解Machine Learning的朋友应该知道近几年,对非参数化贝叶斯(Non-parametric Bayesian)的研究热火朝天——其中很重要的一种过程叫做狄里克莱过程(Dirichlet Processes)。对于狄里克莱过程,大家耳熟能详的也许是Chinese Restaurant Process,又或者是Stick Breaking。可是,您是否知道,狄里克莱过程的理论根源却是源于空间泊松过程?关于这两种过程的联系,是随机测度理论的一个非常美妙的结果。这我们会留在以后的连载中继续探讨。
对于泊松过程,我相信很多朋友不是今天才第一次听说的了。因为,它是很多初级随机过程课程所讲授的内容之一。在初级教科书里面,泊松过程是一个定义在时间上的过程。
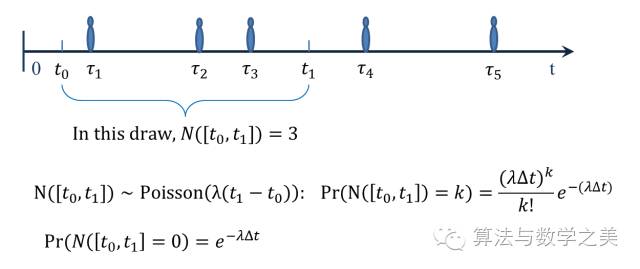
时间上的泊松过程用于描述随机到达,比如来排队的人,或者路过的车子。上面这个图回顾了时间上的泊松过程的一些基本的性质:
1.不相交的时间段上到来的数量是相互独立的;
2.两个点几乎肯定不会同时到达;
3.在某个给定的时间段到达的数量服从泊松分布,分布均值正比于时间段的长度。
大部分初级教科书以性质1和3来定义时间上的泊松过程。我们比较一下这些假设和空间泊松过程的假设,就可以看出来,时间上的泊松过程其实是一般的空间泊松过程的特列。这里,泊松过程所基于的空间就是“时间轴”。其实,这里面的性质3,对于定义一个泊松过程不是必须的,泊松分布这种分布形式,其实是满足性质1的必然结果。至于分布均值正比于时间段的长度,仅仅适用于均匀的泊松过程。对于一般的泊松过程,很可能在某些时间来得密集一些,另外一些时间稀疏一些,这时候分布均值就不一定正比于时间段长度了。
上面关于时间点过程的回顾,仅仅是为了说明这篇文章所讲述的内容其实是大家在随机过程课中所学的泊松过程的推广。在下面的讨论中,我们还是回到一般的空间泊松过程。
计数独立和泊松分布
看到这里,我想大家也许会有疑问?为什么不相交区域的计数独立,就必然会导致任意给定区域内的计数服从泊松分布呢?作为一篇博客文章,我不可能在这里进行一个严格的证明。但是,我会尝试从更直观的角度来解释这个结论是怎么来的。这里的背后正隐含了独立计数和泊松分布之间的深刻联系。
为了考察这个问题,我们首先对整个空间进行细分,把它分成很多很小的不相交的小格子。
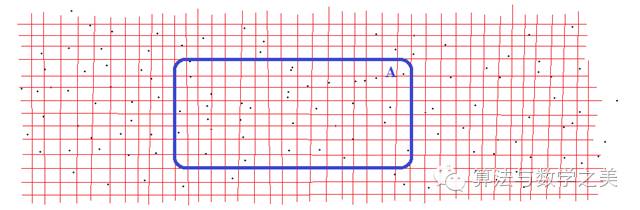
因为每个格子很小,因此对于每个具体的格子,它里面包含点的概率是很低的,而包含不止一个点的概率就更是低到几乎可以忽略了。因此,每个区域中点的数量,大概等于包含点的格子的数量——这样,我们把数点变成了数格子。
假设区域A包含M个格子,它们包含点的概率分别是p_1, p_2, …, p_M。如果我们用X_i表示在第 i 个格子是否存在点,那么 X_i 是一个成功概率为 p_i 的伯努利试验。因而,包含点的格子的总数可以表示为 X_1 + X_2 + … + X_M。因为这些格子不相交,根据不相交区域的独立性假设,X_1, X_2, …, X_M 是相互独立的。在这种条件下,它们的和有一个重要的结论:
对于M个独立伯努利试验X_1, X_2, …, X_M,成功概率分别为p_1, p_2, …, p_M,当每个p_i都很小,它们的总和是个常数C,那么 X_1 + X_2 + … + X_M 近似服从以C为均值的泊松分布。当M趋近于无穷大,每个p_i分别趋近于0,并且总和保持为C,那么在极限条件下,X_1 + X_2 + …,严格服从以C为均值的泊松分布。(熟悉概率理论的朋友应该知道,这样的描述其实是指“按分布收敛”。)
所以,当我们对空间进行无限细分,在极限条件下,会发生下面的事情:
1.每个格子的大小趋近于零,因而里面包含点的概率趋近于零;
2.同时,某个固定区域内的格子数目趋近于无穷大;
3.一个格子内几乎肯定不会出现两个点,因此某个区域内的点数几乎相等于区域内的包含点的格子数;
4.在这个过程中,某个区域内所有格子的含点概率的总和维持为一个常数,我们称之为C。
这些观察合在一起可以得到这样的结论:这个区域内的点数,服从以C为均值的泊松分布。如果您熟悉测度理论和依分布收敛的内容,要根据这个思路写出一个严格的证明其实并不困难。
在上面,我们通过独立性假设,建立的泊松过程。其实,泊松过程还可以从另外一个方面去刻画。我们知道,对于某个具体的区域,它里面的点数服从泊松分布(假设均值为C)。根据泊松分布的公式,在这个区域为空的概率(点数为零)是 exp(- C) 。这似乎只是一个简单的性质,但是请不要小看它——就这个小小的性质本身(不需要附加独立性假定),就足以定义泊松过程:
一个空间点过程,如果区域为空的概率随区域的大小(测度)以指数衰减,那么这个过程是一个空间泊松过程。
对于这个事情,它的严格证明需要使用Characteristic function的有关理论。但是,尽管不太严格,我们还是可以通过直观的观察对这个结论的原理有所感觉。假定,一个区域的大小(测度)为C,那么如果把它分成很多小格子,每个格子大小(测度)是C_1, …, C_M。那么,显然C = C_1 + … + C_M。因此,这个区域为空的概率有
exp(- C ) = exp(- (C_1 + … + C_M)) = exp(- C_1) exp(- C_2) … exp (- C_M)
注意,exp(- C_i) 正是第 i 个细分的小格为空的概率。如果一个概率能够按照乘积分解,其实已经在某种意义上预示了,每个格子是否为空其实是各自独立的,也就是说每个格子是否包含点也是各自独立的——这正好吻合了前面我们对泊松过程的构造。
所以,一方面,计数的独立性必然导出泊松分布;反过来,泊松分布其也蕴含了独立计数的内在性质。它们是一对孪生兄弟,谁也离不开谁。
这让我们回忆起概率论中非常著名的“中央极限定理”:大量的独立随机变量的和依分布收敛于高斯分布。(我们上面说的是:大量的独立伯努利试验的和依分布收敛于泊松分布)。如果说,中央极限定理奠定了高斯分布(正态分布)在概率论中的核心地位;那么在空间点过程这个领域,上述的关于独立计数和泊松分布的关系,则奠定了泊松分布在空间点过程理论中的核心地位。
很多的其它重要的随机过程,包括Cox过程,Gamma过程,以及Dirichlet过程,都是以泊松过程为基础的。在后面的文章中,还会进一步讨论我们如何从泊松过程出发构造其它过程,特别是“完全随机测度”(Completely Random Measure),而统计建模中被广泛采用的Gamma过程和Dirichlet过程,则是这种构造的一个重要的例子。










