本文主要介绍了人工智能领域的两大巨头——英伟达和英特尔的行动和布局。英伟达利用其在GPU领域的优势,在人工智能、自动驾驶、智能家居等领域取得显著进展。它通过推出新产品如Tesla P100、Driver PX等,并在深度学习领域推出CUDA语言和开发套件,实现了深度学习性能的大爆发。而英特尔则通过收购和合作的方式,打造了一个完整的人工智能产业集群,涉及深度学习、自动驾驶等领域。它收购了Altera、Mobileye、Nervana等公司,强化了自身在人工智能领域的实力。两家的不同策略都是为了在人工智能这个未来的巨大市场中获得更大的份额和利益。
推出了新产品如Tesla P100、Driver PX等,并在深度学习领域推出CUDA语言和开发套件,实现了深度学习性能的大爆发。进军自动驾驶、智能家居等领域。
收购了Altera、Mobileye、Nervana等公司,涉及深度学习、自动驾驶等领域。掌控了算法和硬件的结合,提供全面的人工智能、深度学习解决方案。
英伟达和英特尔将继续在人工智能领域带来更多的新技术和体验。
人工智能,这个听起来离我们特别遥远的概念,正成为业内最热门的话题。无论是图像识别、人脸匹配,还是自动驾驶、人机交互,人工智能正在给我们带来巨大的惊喜和无与伦比的改变。在人工智能行业中,PC界的巨头自然不可能抽身在外,英特尔和英伟达,正在利用其在CPU、GPU、FPGA以及算法、平台上的优势,向着业界顶端冲击。那么,在人工智能方面,这两家企业有什么布局呢?
人工智能是目前业内研究的焦点。从早期让电脑识别照片开始,到自动驾驶系统逐渐成熟,智能语音系统使用日渐广泛,智能翻译算法也越来越准确,人们看到了一个前所未有的巨大市场—根据瑞银的预测,到2020年,全球人工智能市场将突破1800亿美元。毫不夸张地说,人工智能将成为业内技术爆发和经济增长的重要技术和基本推动力,甚至有人将人工智能和产业革命相关联,认为人工智能将带来不亚于互联网和信息技术的产业革命,将人类从大量无意义的工作中解放出来。
面对如此庞大的市场和未来,抢先行动起来的除了政府和科学界人士外,还有天生嗅觉灵敏的跨国巨头。在IT界这个人工智能的发源地,跨国巨头已经开始动用各种手段布局人工智能行业。其中英特尔和英伟达的动作非常令人关注:它们一个是PC业界巨头,掌握着全球最先进的半导体工艺制程;另一个则是GPU和并行计算的实际规范制定者,正在利用GPU和深度学习撬动人工智能的半壁江山。那么,英特尔和英伟达在人工智能产业上都有哪些实际行动呢?
如果说最近几年崛起较快的企业,那其中英伟达一定会占据一个位置。这家公司的估值从2015年的不到一百亿美元暴增到目前约600亿美元,GPU的天然优势和人工智能的快速发展为其带来了爆发的动力。
英伟达最重要的产品是GPU,此外,英伟达还涉足SoC芯片行业,也推出过Tegra系列处理器产品。早期英伟达为了尽可能多的利用GPU的通用计算功能,推出了CUDA语言和相关的开发套件。早期的CUDA环境应用范围和内容都比较少,但是进入人工智能时代后,“CUDA+GPU”的搭配面对深度学习表现出了极强的适应性和强大的计算能力。

▲从架构角度来说,GPU先天适合深度学习计算。
▲英伟达利用CUDA和GPU配合,实现了深度学习性能的大爆发。
一般来说,人们认为GPU更适合于大量并发计算,但是不够擅长逻辑判读等操作,这是因为GPU较短的流水线和先天面向图形的设计结构所致。相比之下,CPU的流水线更长,分支预测、逻辑判断等适应性更出色,但是更少的核心数量和较低的计算能力却限制了它的性能。在深度学习应用中,以图形识别为例,将大量的图片信息并发处理,并多次迭代的计算方法对CPU来说太过勉强。目前核心数量最多的CPU也只有32个物理核心,即使有超线程等技术的帮助,也只能做到64线程并发。实际上深度学习要求的并发数量更多,甚至超过数万个,要求的计算能力往往在TFLOPS级别—这样一来,线程数量少、流水线深度较深的CPU就无力维持了,并且在这种应用场景下无论哪个方面,CPU计算效率是远不如GPU的。GPU数千个计算核心和超强的计算能力,很适合这样的大规模并发运算。以英伟达为深度学习推出的Tesla P100为例,单精度计算能力10.6TFLOPS,远超目前最强大的CPU数个数量级。
在硬件和软件上拥有优势后,英伟达的触角伸向了深度学习的应用领域。目前英伟达的主要精力放在下列几个方面:
英伟达的核心是GPU,这一点在前文也有说明。不过,GPU现在的含义应该从“Graphics Processing Units”转向“General-purpose Processing Units”,也就是通用处理器。显然,GPU在人工智能上的用途尤其是深度学习带来的智能化功能,使其能够满足更多场景和环境下的应用。除了硬件外,软件方面英伟达借助CUDA成熟的生态环境,结合GPU的优势,基本上已经成为了人工智能深度学习方面的事实标准。具体到行业应用上,包括超级计算机、大学研究、工业设备以及大量研发类产品,英伟达的“GPU+CUDA”正在不断的攻城略地。
如果说英伟达在人工智能和深度学习上的努力终于开花结果的话,那么最大的那一颗果实就是自动驾驶。在2015年和2016年的CES展会上,英伟达的主题演讲核心内容只有一个,就是自动驾驶平台,主角就是Driver PX和Driver PX2。这两款产品以Terga处理器为核心,搭配GPU来实现高效率的深度学习,最终可以达到Level 3到Level 4级别的自动驾驶。
当然,目前的Driver PX系列产品还存在很多问题,比如功耗过高(超过200W)、稳定性尚未经过考验等。不过,在2017年的CES上,英伟达公布了正在研发的全新一代产品“Xavier”,这是一颗专门为深度学习和智能驾驶等应用领域设计的全新的产品,它采用的是新一代512 CUDA Core的Volta GPU架构,搭配八核心CPU,深度学习计算能力可达20DL TOPS,功耗降低至约20W,适合使用在汽车上作为主要计算核心。

▲英伟达推出的DriverPX 2,用于汽车自动驾驶。不过这款产品功耗太高,散热甚至需要水冷,难以在民用汽车上长期使用。
另外,英伟达还推出了辅助驾驶系统AI Co-Pilot,依旧是利用了深度学习技术,它能够根据驾驶员的语音、动作甚至是唇语、眼神等了解到驾驶员的意图,并通过控制车外传感器和汽车操控来实现辅助驾驶功能。从产品来看,在真正的自动驾驶到来之前,AI Co-Pilot可以作为一个辅助驾驶功能帮助司机了解到周围的情况和问题,包括示警、防碰撞、道路监测等,它相当于是一个过渡手段,用于补偿在自动驾驶技术正式上市之前的这段空白时间。

▲AI Co-Pilot主要是利用深度学习技术完成辅助驾驶功能。
目前业内自动驾驶发展的如火如荼,各家都在推出不同的方案。不过为了更好地区分从人工驾驶到自动驾驶的差异,业内还是定义了一些级别,来衡量自动驾驶技术的发展程度。这个级别分级如下:
Level 0:完全没有自动驾驶功能,所有控制都需要依靠人工实现。
Level 1:实现了一些自动驾驶功能,比如重要的巡航控制、车道保持、自动转向、泊车辅助等,人工依旧需要控制。
Level 2:自动驾驶系统开始介入大部分操作,包括自动转向、制动、加速等。不过人必须保持随时接管汽车的能力。
Level 3:除了特殊环境和特殊情况(复杂的无道路场景),汽车都可以自动驾驶,人可以在乘车时做其他事情,但是驾驶员依旧需要准备应对突发情况。
Level 4:除了极端天气和极端环境(比如暴风雨),汽车都可以自动驾驶,人可以在乘车时做其他事情,但是驾驶员依旧需要准备应对突发情况。
Level 5:人类只是货物,驾驶完全交给机器来进行。
目前市场上绝大部分汽车的自动驾驶级别是Level 0,配备了诸如泊车辅助、自动巡航等功能的汽车可以勉强算作Level 1。目前宣称具有高级辅助驾驶功能的汽车,一般也都是Level 1~ Level 2水平,很少有完全可以达到Level 2的,Level 3级别目前尚未有厂商可以保证,还需要进一步的观察。
英伟达在自动驾驶领域的努力,为其带来了一轮股价狂潮。不过英伟达并没有停下脚步,还在进一步扩展自己的业务范围,包括智能家居、智能医疗、无人机等场景。比如智能家居方面英伟达发布了名为SPOT的智能家居控制中心,用户可以使用语音来控制家里的电器,实现包括灯光、音响、语音等全面的控制。在医疗方面,利用深度学习技术,英伟达和麻省总医院正在训练电脑识别高达100亿份医学影像,为疾病诊断、监测和治疗做出努力,此外英伟达还和美国国家癌症研究所一起,推进癌症的深度学习研究。
上述所有布局,都展示了英伟达利用GPU在深度学习上的优势,进一步加强自己在技术领域的地位并扩展自己的市场,希望获得更大的回报。回顾十几年前,谁又能想到这样一个主攻GPU显卡的公司能发展至如此庞大的地步,甚至即将深入、掌控我们的生活。
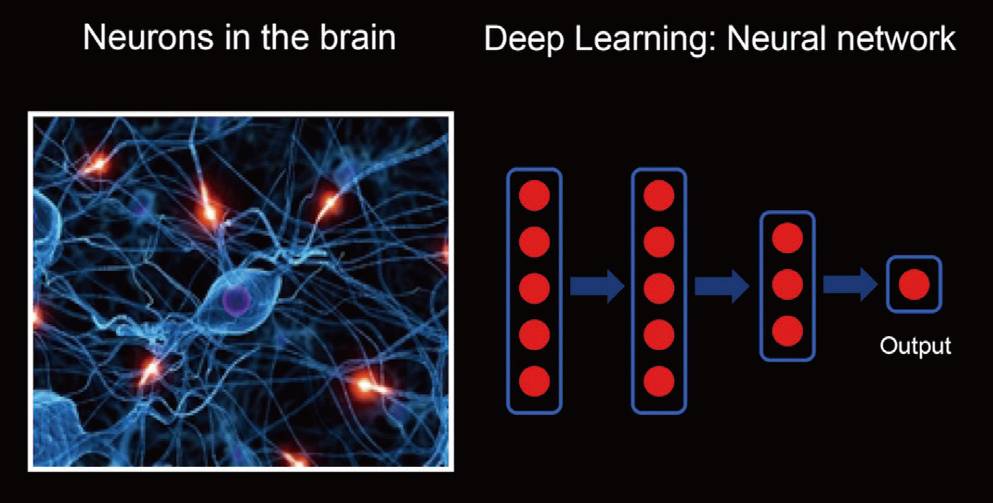
说起深度学习,人们总觉得非常遥远。实际上深度学习并非凭空出现,而是一个仿真、模拟大脑思考事物方式的过程。深度学习只是机器学习的一个分支技术,由于其技术、算法和目前的软硬件环境匹配度较高,因而得到了快速的发展。
深度学习的技术原理是由David Hubel和Torsten Wiesel提出的。他们于1958年在约翰·霍普金斯大学(The Johns Hopkins University)工作时,通过研究猫的瞳孔区域和大脑皮层神经元的对应关系,发现一种名为“方向选择性细胞”的神经元,这种神经元主要是用于测量物体边缘的方向。随后在其他一些研究中显示,大脑通过对采集到的信息进行不断迭代和抽象,经过多层处理,最终得到了我们大脑反应的信息。
▲深度学习通过模拟大脑处理图像的方法查找关键单元。
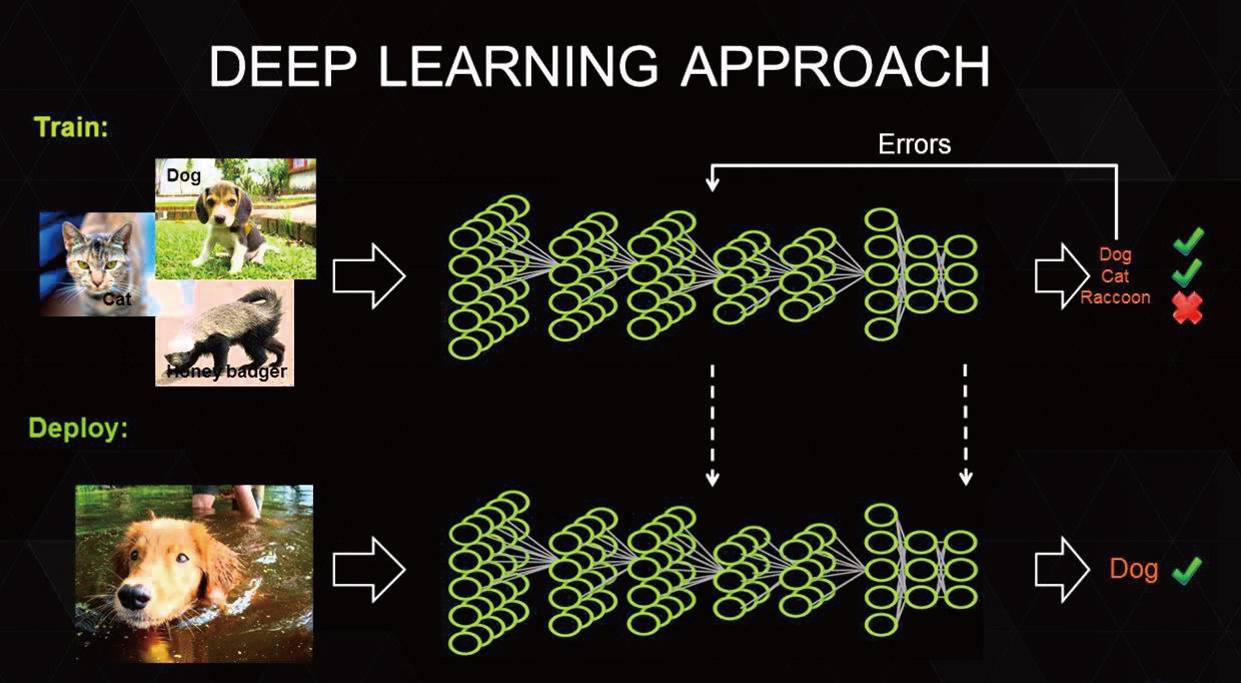
我们用一个例子要说明深度学习是怎样一个过程:假设有一个机器,它不懂阅读,但是明白每个字的意思。当它看到一段话时,实际上由于整段话太长,它并不理解这段话的意思。这个时候,机器可以通过认识每个字并不断地学习由字组成的词,从而得知词的意思;然后用词推及短语,了解到短语的意思,最后再读懂组成的句子。这是一个不断学习和迭代的过程,通过“字—词—短语—短句—段落”的迭代,最终理解一段话的意思。
以深度学习中比较常见的图像识别为例,机器其实不懂任何图像所表达的意思,在机器眼中,像素层面的图像就是一个个数字。但通过一些采样算法,机器能够识别出显著不同的图像边缘并记录这些边缘的特征。虽然有了一些特征数据,但是在像素尺度上,这些数据实际上是零碎的、不可辨识的,它不代表任何东西。这个时候,通过多次的组合和迭代处理,机器开始拥有了将这些特征点逐渐逼近原图含义的能力,最终在多次迭代和组合、学习、对比后,机器能够给出原图有关信息的答案。

▲这是深度学习在处理图片,以图片中的边缘作为查找目标。
▲制备完成的碳纳米管照片,可见条形结构。
从这里也可以看出,所谓深度学习,是指在机器得到的数据和给出的最终信息之间一个多层的、有深度的处理过程,因此它也被称作Deep learning,用于处理这些数据的模型和算法被称作NeuralNetwork,也就是神经网络。深度学习和神经网络,组成了我们目前最常见的人工智能的基础。
目前英伟达对Xavier的基本结构还没有公布太多信息,只是给出了一些最基本的参数,包括八核心CPU、Volta架构的GPU以及深度计算能力高达20DL TOPS,制程方面维持TSMC 16nmFinFET+不变。
从产品的角度来推测,Xavier在CPU部分应该改用了全新的架构,之前的Denver并没有出现在发布会上,考虑到其专用性,英伟达很可能涉及了新的架构来满足深度学习的需求。另外在GPU方面,512 CUDA Core的Volta架构也是首次发布,因为现在桌面产品还在使用Pascal架构。
最后来看深度学习能力,英伟达的想法:Xavier处理器的秘密是,在20W内做到20DL TOPS(TOPS)的深度计算能力(DL TOPS是一个8位整数计算能力的衡量方法,Xavier希望做到1 DL TOPS/W),考虑到目前的DriverPX2的计算能力只有24DL TOPS,因此Xavier在工艺不变的情况下,架构上必须做出巨大的调整才可以做到。一旦Xavier的功耗控制在20W以内,那么大批量在汽车上使用就不会成为难题了。


▲Xavier经过重新设计,功耗大幅度降低,在和博世合作后,外观设计更像汽车配件,也更容易在汽车内使用和搭配了。
在功能上,Xavier能够融合更多的传感器,包括摄像头、激光雷达、雷达、超声波等。另外,Xavier目前在和博世合作开发提供给汽车厂商的版本。考虑到Xavier将在2018年或者2019年大批供货,那么首次在汽车上看到Xavier应该在2020年以后了。
▲借助Xavier和深度学习,汽车最终可实现完全的自动驾驶。

▲英伟达推出的智能家庭控制中心。
在很多用户的印象中,英特尔似乎对人工智能的发展不那么热心。比如英特尔除了在展会上带来一些有关人工智能和深度学习的应用、案例外,一般用户接触不到太多案例。实际上,英特尔在人工智能上走的是特殊的方法—通过收购和合并,打造一个人工智能全产业链集团。
之前英特尔在人工智能的研究方面也投入了不少精力。不过,和英伟达有GPU作为计算核心相比,英特尔在人工智能领域之前没有专精的产品,毕竟英特尔长期战略是坚持以CPU为核心。但这种情况在2012年发生了变化,英特尔在2012年推出的Xeon Phi加速计算器,在众核和大规模并行计算方面开始有了实际的硬件产品。在2016年的IDF上,英特尔也将重点瞄准了深度学习,其代号为Knights Mill的全新一代Xeon Phi的深度学习能力达到上代产品的4倍以上,采用全新10nm工艺打造,集成高达72个Airmont核心,能够利用板载16GB 3D RAM和384GB DDR4内存。此外,英特尔还通过大量的收购,建立了一个完整的人工智能产业集群。

▲Xeon Phi是英特尔在人工智能和深度学习方面最重要的硬件产品之一。

▲英特尔全新的Knights Mill Xeon Phi将带来更强悍的性能。
除了在硬件上作准备外,英特尔在资本市场上也开始逐步发力。其中包括以162亿美元收购Altera公司、以153亿美元收购Mobileye,以及收购Saffron Technology、Movidius和Nervana等创业企业。通过对这些企业的并购,英特尔得以快速切入人工智能市场,不但开拓了全新的领域,也大大加强了自己的实力,开始准备和英伟达正面厮杀。
在人工智能市场上,如果说英伟达是自然生长并一步步做大的话,那么英特尔就是通过并购“合纵连横”、“强行进入”的—充足的现金流和先进的制造技术给了英特尔谈判的底气,而快速的收购也让英特尔得以在最短时间内切入市场。下面,本文就简单介绍一下英特尔在人工智能市场上至关重要的三次收购。
Altera是一家以FPGA为主要产品的公司。所谓FPGA,就是现场可编程门阵列,它是一种半定制化的集成电路,主要应用在固定计算任务和目标的场合。和一般的通用型处理器不同,FPGA特别擅长处理某一类任务,因为它的电路和芯片设计就是特别针对某一种程序进行优化的。这使得FPGA在固定应用场合非常受到用户欢迎。
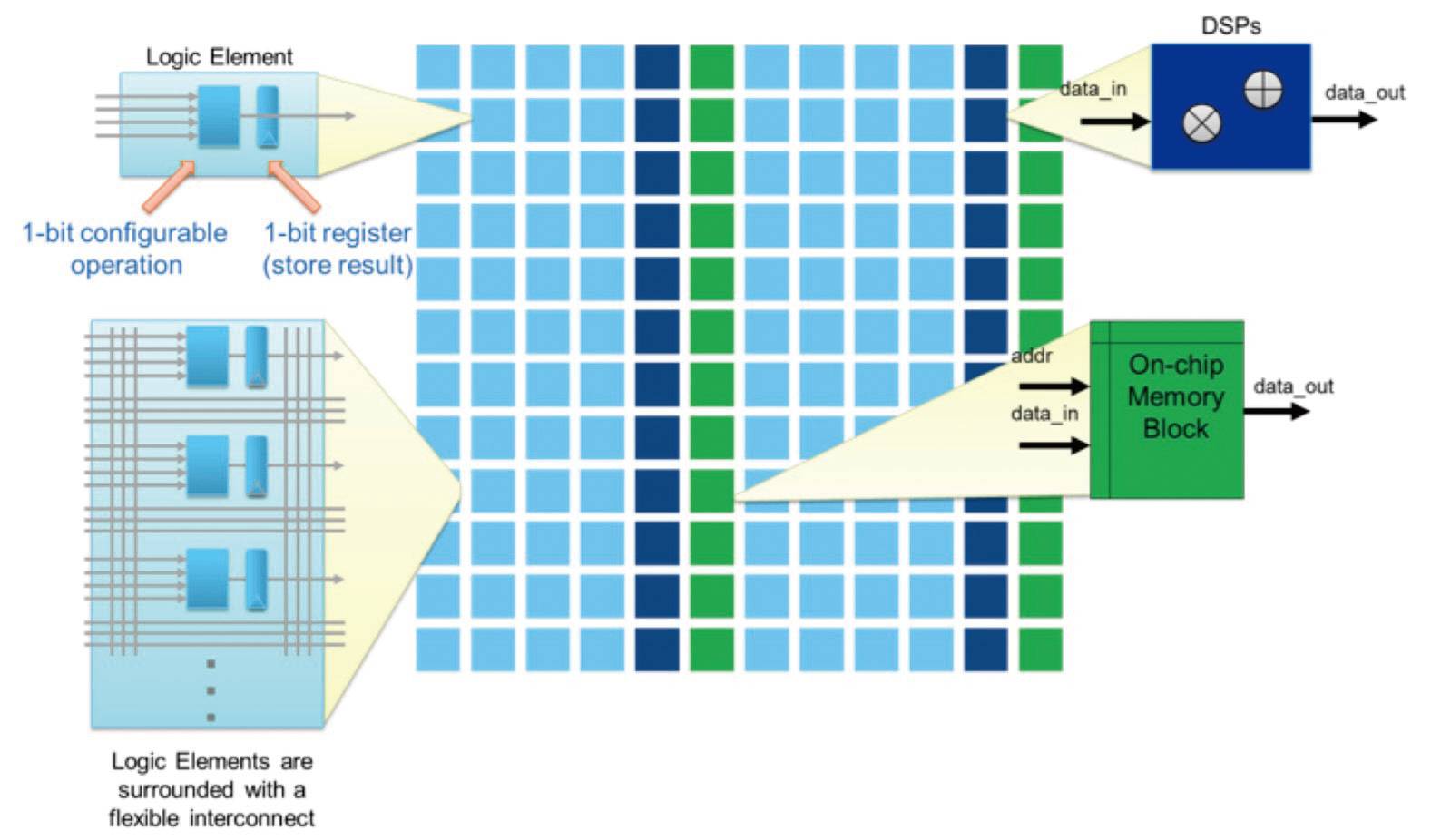
▲目前深度学习的热门发展方向中,FPGA是不可或缺的一环。
从传统意义的市场来说,FPGA和CPU这样的通用产品还没有开始抢饭碗,但是在深度学习市场上,深度学习高度依赖于算法,FPGA在这里有一定的用武之地,而且计算架构可重构特性也能满足用户对深度学习应用的需求。此外,FPGA和异构计算的关系也密不可分,英特尔也正是看中了Altera在深度学习和异构计算上的优势,才最终下手将其收入囊中。
至于收购Mobileye,就更显得理所应当了。Mobileye是来自于以色列的创新公司,早期Mobileye为特斯拉提供车载智能驾驶模块,并且实现了特斯拉的半自动化驾驶功能。业内一度将Mobileye看作是英伟达的竞争对手。不过Mobileye存在自己的缺陷,那就是芯片设计能力弱。
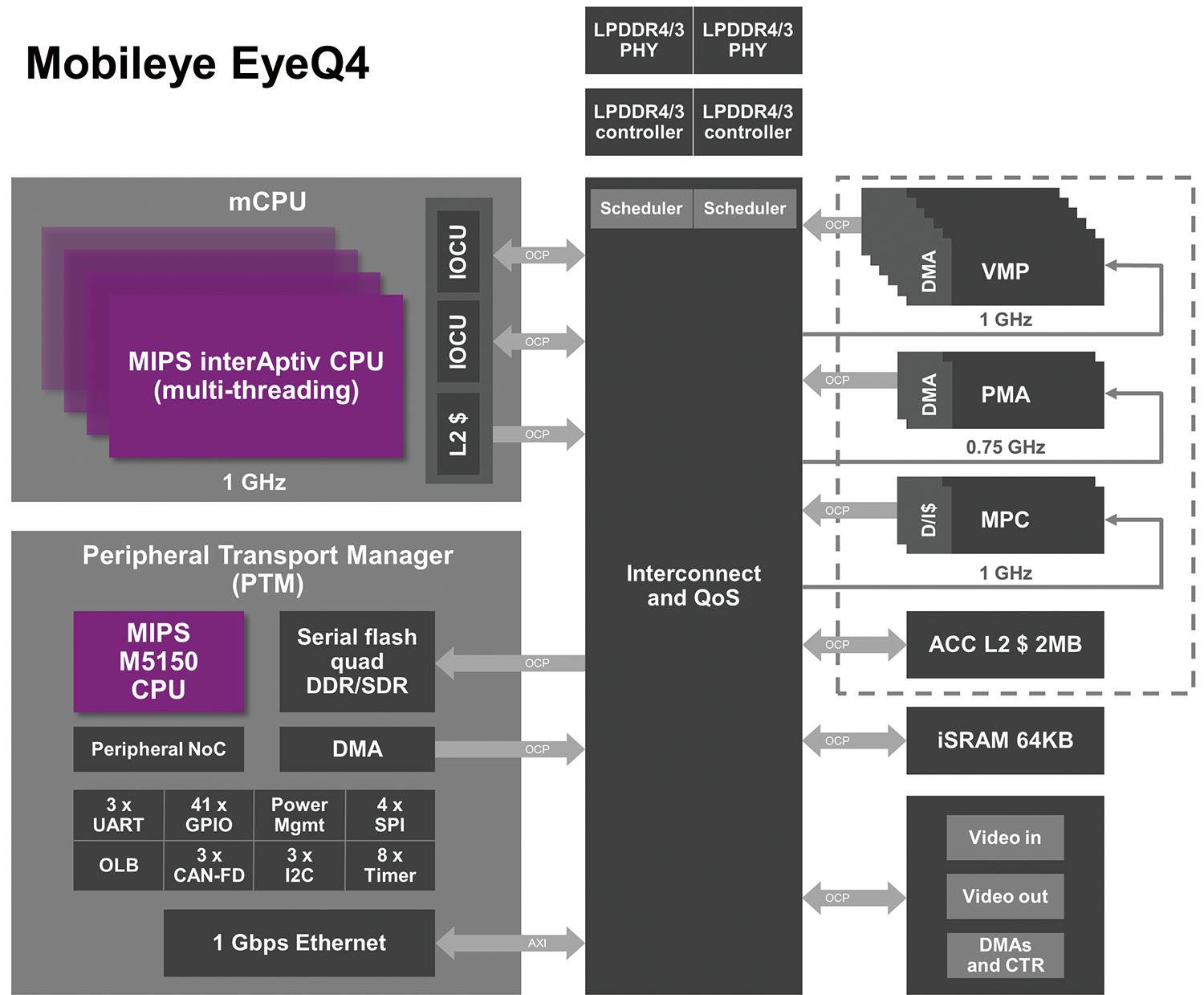
▲Mobileye EyeQ4产品架构图,实际上也是利用深度学习来实现自动驾驶功能。
作为一个创业型公司,Mobileye之前没有芯片设计经验,其2016年发布的EyeQ5芯片选择了意法半导体作为制造的合作伙伴,并且出货时间定在了2020年。这样的行为让业内不少人感到震惊:没有产品,依靠PPT就开发布会,这并不是芯片行业的行规。
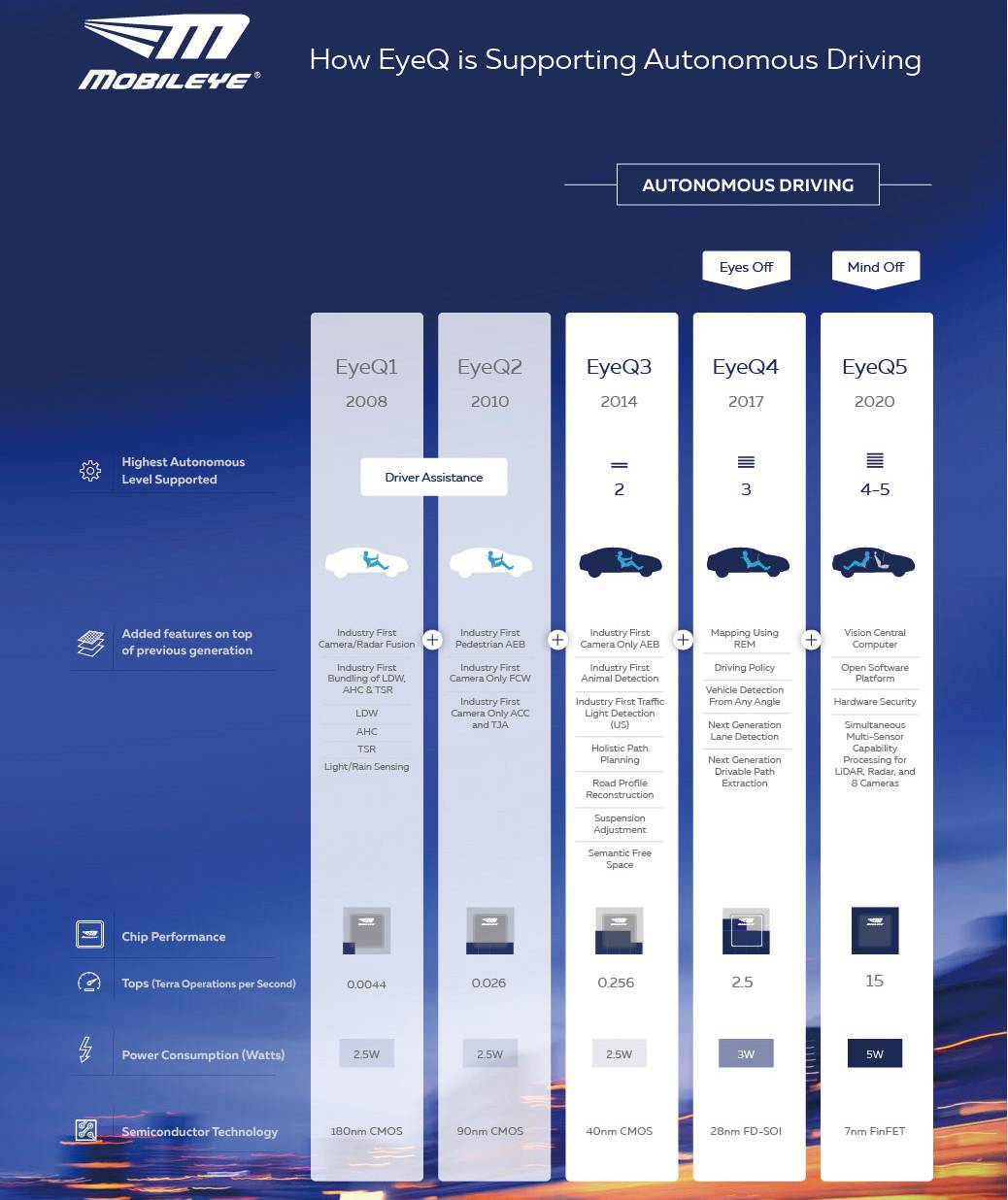
▲Mobileye设计的EyeQ5芯片在2020年可能实现4~5级别的自动驾驶,不过工艺等问题还是最大的桎梏。
从这一点来说,Mobileye本身需要将自己的算法和数据更好的和硬件结合。在这一点上,英特尔恰好能给予其这样的支持,英特尔拥有深厚的芯片设计功力和独步业内的制造能力,能够很好地进行算法和芯片的协同设计,这样的强强联合,英特尔获得了进入自动驾驶市场的门票,Mobileye也加强了自身。
除了高达百亿级别的大型收购合作外,英特尔还将目标瞄准了一些小型企业,比如Nervana,这家企业由三名神经学家创立,其主要研究的内容就是如何让计算机更有效率地模拟人脑的思维方式来进行深度学习计算,Nervana也曾指出GPU运行深度学习算法实际上并非最高效率的做法,因为GPU还是面向图形设计的,部分内容对神经网络来说不是必须的,甚至Nervana在考虑自行设计神经网络计算芯片来实现最高效能的计算。

▲收购Nervana后,英特尔拥有了现成的深度学习算法。
这里有一个小趣事:在英特尔向Nervana发出收购要约后,Nervana曾询问英伟达是否愿意并购自己,毕竟自家的深度学习软件Neon也能够非常高效地运行在GPU上。不过英伟达当时没有对这项收购表现出兴趣,直到英特尔和Nervana已经签署协议后,英伟达才开始接触Nervana,但是此时除非英伟达支付一笔赔偿费用,否则Nervana和英特尔联姻便成定局,所以最终还是英特尔抢先一步“抱得美人归”。
通过多次收购,英特尔完成了由量变到质变的积累过程:从一个PC和制造行业的巨头转身进入高速发展的人工智能行业,并直接切入到利润最高和最有希望快速商业化的智能驾驶市场。
▲经过多次收购,英特尔在人工智能上的布局逐渐完成。
在完成了大量道收购后,英特尔在人工智能方面已经有了一整套布局,包括不同行业的解决方案、工具和平台(包括Saffron、Movidius和Nervana等公司,以及英特尔的深度学习SDK)、英特尔的优化型开放框架(提供对Spark、Caffe、CNTK等深度学习框架的支持)、英特尔免费的库/语言(比如英特尔数学核心函数库、英特尔数据分析加速库、英特尔Python发行版等)、英特尔酷睿、Xeon和Xeon Phi、FPGA等产品的支持等。通过这些软件和技术,英特尔能够从软件到硬件、从行业到个人、从学校到工厂,提供全面的人工智能、深度学习解决方案。
从上文的介绍可以看出,英特尔和英伟达两个技术巨头,在人工智能市场上纷纷布局,希望在未来能够获得更大的份额和利益。英伟达的风格比较自我,通过搭建自家的软硬件生态,不断涉足更多领域来扩大市场影响力并获取利润。英特尔则利用并购快速进入市场,并形成完整的产业布局。在未来很长一段时间,随着人工智能技术的发展,英伟达和英特尔还将带来更多新鲜的技术和全新的体验。本刊也会在往后就它们在人工智能领域上的具体产品、技术进行深度解析,尽请关注。







