Git 跟其他版本控制系统最大的优势就在于其高级的分支模型。
Git 允许而且 鼓励 你在本地使用多个完全独立的分支。这些分支的创建,合并和删除几乎都可以在几秒内完成。
这意味着你可以轻松的做如下操作:
-
无痛的上下文切换 创建分支试验一个想法,提交几次,切回你原来分支的状态,应用一个改动 patch,切回你原来正在试验的状态,将刚才应用的 patch 合并过来。
-
基于角色的代码支线 你可能会有一个分支仅仅包含那些只存在于生产环境上的代码,另外有一个独立的分支用以合并测试环境代码,还有若干个更小一些的分支用于日常开发工作
-
基于特性的工作流 为每一个新的特性创建新的分支,你可以方便平滑的在这些分支之间无缝切换,当这些特性的改动完成的时候,你可以将其合并入主分支,并把特性分支删掉。
-
任意试验 创建一个分支专门用来试验,当觉得试验不理想的时候,直接删除掉即可,放弃掉之前的试验内容。这时候不会有任何其他人察觉到这个试验(甚至在这期间你还可以推送其他不相关的分支)

尤其是当你推送至远程仓库的时候,你不必推送所有分支,你可以选择只推送少数你愿意分享的分支,当然如果你愿意,也可以推送所有分支。这一点倾向于让开发者在试验很多新的想法的时候免除发布自己的未成熟的试验计划的顾虑。
当然,也有一些其他的系统可以部分实现上述的功能和优势,只是具体的执行会变的困难和容易出错。Git 让这些工作变得难以置信的简单,它在开发者学习其使用的同时就改变了开发者的工作模式。
Git 很快。Git 基本上所有的操作都在本地执行,这对于那些必须跟服务器通信的集中式系统是一个巨大的速度优势。
Git 一开始是为了管理 Linux Kernel 的源代码设计的,这意味着他从第一天诞生就拥有了处理大型仓库的高效优势。Git 使用 C 语言编写,减轻了使用更高级别编程语言的 Runtime 带来的性能损耗。Git 最开始的两个重要的设计目标就是性能和速度。
压力测试
让我们看一下与 SVN (一个通用的集中式存储版本控制系统,跟 CVS 和 Perforce 很像)相比下的常规操作的性能测试指标。这里指标是值越小,速度越快。
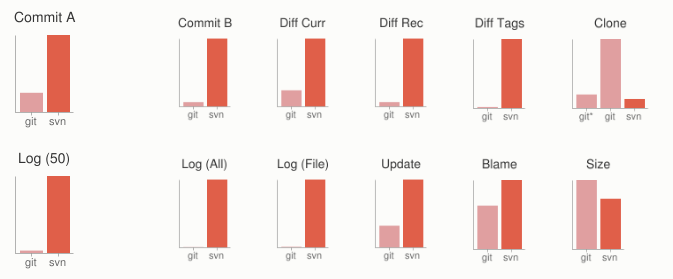
为了测试,我们在亚马逊的 AWS 的同样的可用区上新建了两个 Large 类型的计算服务器实例。每一个计算实例上都安装 Git 和 SVN。 我们把 Ruby 的源代码仓库拷贝到了 Git 和 SVN 的计算服务器示例上,两者都执行通用的操作。
在有些情况下,两者的命令和实际效果并不能完全对应起来。在这里,我们在常用的操作中选择相似效果的匹配情况。例如,对于“提交”的测试,在 Git 中我们也是计算 Push 的时间的。然而在大多数情况下,你可能实际上并不会在提交后马上就推送到服务器上,这在 SVN 上是不可分割的操作。
下面表格中所有的时间单位都是秒。
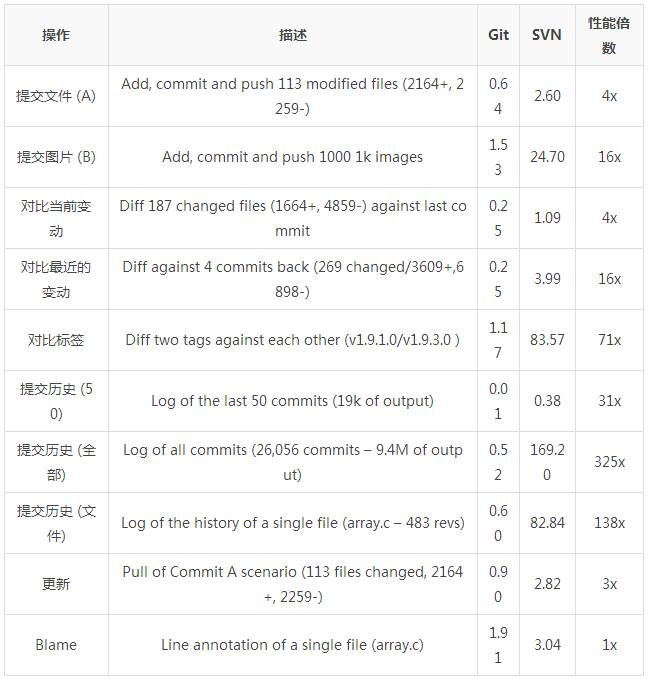
你需要注意的是,这已经是 SVN 最好的运行场景了 — 一个没有任何负载的服务器,客户端和服务器之间的网络带宽达到 80MB/s。上文中的所有指标在受网络波动,或者在一个更差的网络环境下 SVN 的表现都更差,然而 Git 这边几乎所有的指标都不受影响。
很明显,在这些最常用的版本控制工具的操作中,甚至是在SVN 的理想使用环境下,**Git 在很多方面都大幅领先**。
一个 Git 比 SVN 慢的地方是初始化 clone 仓库。在这种情况下,Git 是在下载整个仓库历史而不是仅仅是最新版本的代码。上文中的表格所示,仅仅执行一次的操作影响并不是很大。
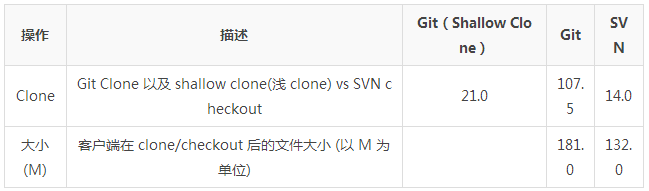
另外一个有趣的点是,Git 和 SVN 在 Clone 或者 Checkout 到本地后的文件大小几乎差别不大,要知道对于 Git 来说,本地可是包含了整个项目历史。这也展示了 Git 在文件压缩和存储上的超高效率。
Git 最棒的特性之一就是分布式。这意味着,你要 clone 整个仓库而不是仅仅 checkout 分支的最新头部版本。
多个备份
在日常的使用场景中 Git 往往有多个备份。这意味着就算在使用一个中央存储式的工作流,每一个用户都在本地有一个服务器上的完整备份。这里的任意一个版本都可以在服务器端数据损坏或者丢失的时候推送回服务器以挽救损失。事实上,只要你的仓库不是只有一个 copy,Git 就不会存在单点问题。




