(本文阅读时长:10分钟)
朴素贝叶斯的简介
在机器学习的分类算法的各个门类中,贝叶斯分类方法是一个比较重要的组成部分。而隶属于贝叶斯分类方法的算法,均是以贝叶斯定理为基础的。
对于一个分类问题,目标是Y{y1,y2…yN},已知条件X{x1,x2…xN},需要通过用X来推断出Y。在贝叶斯定理的思想下,预测目标y是否属于某一类ck,我们需要计算出相应的概率P(y=ck|x),进而判断Y的类别。通过贝叶斯公式,可以通过下式求得:
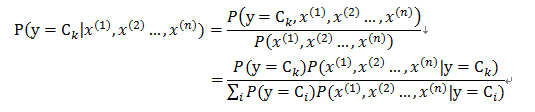
通过给定的训练数据集合,我们可以直接计算出P(y=ci)和单个变量x的条件(后验)概率P(xi|y=ci) ,需要知道P(x|y=c),还得计算出后验概率P(x|y=ci),我们还需要一个假设:
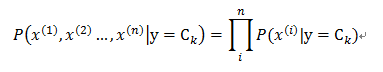
即条件独立性假设,这便是朴素贝叶斯算法的核心(即为什么“朴素”)。条件独立性假设使得各个特征属性之间彼此相互独立,因此只要将各个特征在给定类别ci的后验概率相乘就可以估算出当前各个特征取值的后验概率P(y=ci|x)。这是一个很强的假设(现实中往往很难成立)。
下面给出二分类朴素贝叶斯的训练和预测流程:
对于输入的X和Y
1.计算出先验概率:
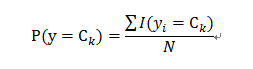
2.计算出每一个特征各个取值的后验(条件)概率:
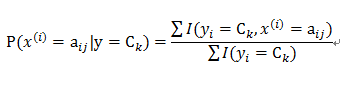
3.对于给定的新的数据,按照条件独立性假设和贝叶斯公式求得y所属各个类别的概率,按照概率大小决定分类结果:
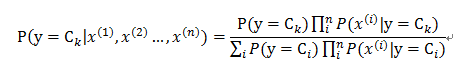
改进:拉普拉斯平滑
由于朴素贝叶斯建模过程中,对于每一条特征在y的条件下后验概率的计算时,若训练集的某个特征取值在当前类别中未出现,则其后验概率为0,这样将会导致在预测中该特征在取到当前值的时候概率为0(无论其他特征如何),可能会严重影响模型的预测。因此在通常情况下,我们会在单特征各取值的后验概率公式的分子适当加一个数值,来避免概率值为0的情况:
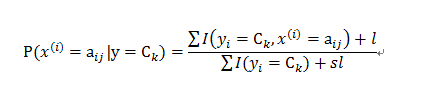
当l为1时,则称之为拉普拉斯平滑法。
朴素贝叶斯的特点
作为比较简单的分类器之一,朴素贝叶斯有着自己的特点。其优势在于:首先,朴素贝叶斯源于古典数学的理论基础,有着稳定的分类效率;然后,朴素贝叶斯算法对小规模的数据表现很好,且可以处理多分类任务,适合增量式训练,即使数据量超出内存时,我们可以一批批的去增量训练;其次,朴素贝叶斯模型对缺失数据不太敏感,算法也比较简单,常用于文本分类(如垃圾邮件区分)。
同时,朴素贝叶斯模型的缺陷也很明显:第一,理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,但这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果较差;第二,建模过程中需要知道先验概率,而先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳;第三,由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
代码的实现过程
导入包和数据
接下来,我们同样采用Python去实现简单的朴素贝叶斯分类器。首先加载相应的模块,并且导入数据。numpy用于建模计算,pandas仅用于导入数据。本文所用的数据依旧是马疝病的分类数据集
import numpy as npimport pandas as pd #用于加载数据集
horse = pd.read_table(u'.../horseColicTraining.txt',
sep='\t',names=['x' + str(i) for i in range(21)]+['y'])
horse_t = pd.read_table(u'.../horseColicTest.txt',
sep='\t',names=['x' + str(i) for i in range(21)]+['y'])
连续型变量离散化
通常,朴素贝叶斯只能直接处理离散型(类别)变量(也可以假定变量的分布来进行概率推测,本文不涉及这一方面内容),所以对于那些连续(数值)变量需要首先离散化处理,建立一个分箱器,对数据集中连续型变量进行分箱。
#分箱器
def bin_get(x,your_bins):
new_x = x.copy()
for i in range(your_bins.shape[0]):
if i==0:
new_x[x<=your_bins[i]]=0
if i>0:
new_x[(x>your_bins[i-1])&(x<=your_bins[i])]=i
if i==your_bins.shape[0]-1:
new_x[x>your_bins[i]]=(i+1)
return new_x
在分箱过程中,以0.2,0.4,0.6,0.8四个分位数为截点,分为5箱。若数据集unique值类别较少,则视为离散变量,不做处理。并且将分箱以后的DataFrame转换为numpy矩阵形式。
#分箱
horse_bin = horse.copy()
horse_t_bin = horse_t.copy()
for i in range(horse.shape[1]-1):
if len(set(horse_bin.ix[:,i])) > 7:#只对拥有7个unique值以上的变量进行分箱工作
horse_bin.iloc[:,i] = bin_get(horse.ix[:,i],
np.array(horse.ix[:,i].quantile([0.2,0.4,0.6,0.8])))
horse_t_bin.iloc[:,i] = bin_get(horse_t.ix[:,i],
np.array(horse.ix[:,i].quantile([0.2,0.4,0.6,0.8])))#转化为numpy矩阵便于建模
horse_bin = np.array(horse_bin)
horse_t_bin = np.array(horse_t_bin)
朴素贝叶斯模型定义
首先定义模型类,先写入先验概率计算函数、条件(后验)概率计算函数等,并考虑拉普拉斯平滑的问题:
class Naive_Bayes_JQ:
def pri_prob_for1(self,x,lapras=0): #对先验概率的计算函数
prob_dir1 = {}
for i in set(x):
prob_dir1[i] = float(sum(x == i)+lapras)/(len(x)+lapras*len(set(x))) return(prob_dir1) def pri_prob_for2(self,x,y,lapras=0): #先验概率的计算函数(X且Y)
prob_dir2 = {}
for i in set(x):
for j in set(y):
prob_dir2[(i,j)] = float(sum(y[x==i]==j)+lapras)/(len(x)+lapras*len(set(x)))
return










