随着人工智能、自动驾驶、物联网(IoT)和5G等技术的快速发展,对高带宽内存的需求持续增长,HBM也就应运而生了。HBM(High Bandwidth Memory,高带宽存储器)是一种先进的内存技术。通过高带宽、低功耗和紧凑的封装设计,它能满足高性能计算(HPC)、人工智能(AI)、图形处理(GPU)和数据中心的需求。

HBM的核心特点
高带宽,HBM通过宽接口和多通道设计实现了高数据吞吐量。相较于传统的GDDR内存,HBM提供更高的每针带宽,适合处理大规模并行计算任务。

低功耗,HBM通过减少信号传输路径长度和优化电路设计,降低了功耗。工作电压通常为1.2V或更低,比GDDR显著节能。
紧凑封装,HBM采用2.5D封装,将DRAM芯片垂直堆叠并通过硅中介层(Interposer)连接到处理器,显著减少了PCB面积。
高密度,采用TSV(Through-Silicon Via,硅通孔)技术使得HBM可以支持多层堆叠,每堆可达16层甚至更多。
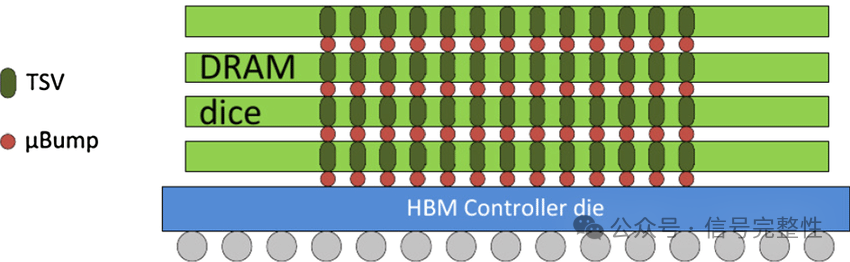
HBM的技术架构
HBM的架构包括以下几个关键部分:
1.堆叠设计,HBM内存由多层DRAM芯片堆叠组成,层数从4层到16层不等。通过TSV技术在垂直方向实现层间互联,降低信号延迟。
2.宽接口,每堆HBM内存具有数千个I/O接口,典型为1024位宽或更高,显著提高了数据传输速率。
3.硅中介层(Interposer),HBM内存与处理器之间通过硅中介层连接,提供高带宽、低延迟的通信。
4.分片架构,HBM内存被分成多个逻辑分片(Channels),每个分片都有独立的控制器以提高并行访问能力。
从2015 HBM第一代发布到现在近10年的时间,已经商用的是HBM3E,预计明年会发布HBM4。

每一代HBM的发布都会带来非常大的变革。下面我们简单介绍下每一代发布的主要内容,重点比较它们的性能、技术特点和应用领域:
参数 | HBM1 | HBM2 | HBM3 | HBM3E | HBM4 |
发布时间 | 2015 | 2016 | 2021 | 2023 | 预计2025年 |
带宽(每堆叠) | 128 GB/s
| 256 GB/s | 819 GB/s | ~1.2 TB/s | 2 TB/s 或更高 |
总带宽 | 512 GB/s | 1 TB/s | 3.2 TB/s | 4.8 TB/s | 6 TB/s 或更高 |
单堆容量 | 1 GB–4 GB | 4 GB–8 GB | 16 GB | 24 GB | 48 GB 或更高 |
堆叠层数 | 4–8 层 | 4–8 层 | 8–12 层 | 12–16 层 | 16 层或更多 |
I/O 速度 | 1 Gbps | 2 Gbps | 6.4 Gbps | 9.2 Gbps | 12 Gbps 或更高
|
功耗效率 | 较低 | 提升10% | 显著提升 | 进一步优化 | 更高的能效 |
工艺节点 | 28nm | 20nm | 12nm | 10nm 或更先进 | <10nm |
关键技术 | 基础 TSV 堆叠 | 高层 TSV 堆叠 | 高速通道优化 | 无助焊剂键合 | 无助焊剂+更高堆叠 |
典型应用 | 图形处理(GPU) | AI 和 HPC | 数据中心,HPC | 生成式 AI,加速器 | 下一代 AI 与 HPC |
制造商 | SK Hynix, AMD | SK Hynix, AMD, Nvidia | SK Hynix, Samsung | SK Hynix, Samsung
| SK Hynix, Samsung |
为什么不采用GDDR或者DDR5这类存储总线呢?其实个人认为最主要的原因主要集中在带宽、能效、延迟和紧凑性等关键性能指标上。比如单堆叠HBM3的带宽可达 819 GB/s,系统总带宽可超过 3.2 TB/s,虽然GDDR6X最高可达64 GB/s已经很高,但是还是远不及HBM高;DDR5就更加不具备高密度传输的能力了。
以下是关于HBM3与GDDR6/6X以及DDR5的简要对比:
参数 | HBM3 | GDDR6/GDDR6X | DDR5 |
主要用途 | HPC、AI训练、图形处理、数据中心 | 游戏显卡、专业显卡 | 服务器、PC内存 |
接口宽度 | 1024 位(或更高) | 32 位(单通道) | 64 位 |
带宽(每堆/通道) | 819 GB/s(HBM3) | 16–21 GB/s(GDDR6) | 4.8–6.4 GB/s |
64 GB/s(GDDR6X) |
总带宽 | >3.2 TB/s(多堆叠) | 1 TB/s(典型显卡) | 51.2 GB/s(典型配置) |
容量(单模组) | 8–16 GB(单堆叠) | 8–24 GB(单显存模组) | 8–256 GB |
功耗效率 | 高效(低功耗设计)
| 较高功耗 | 中等功耗 |
工作电压 | 1.1 V | 1.35–1.5 V | 1.1 V |
封装形式 | TSV+硅中介层(2.5D封装) | 标准显存封装 | 标准DIMM |
延迟 | 极低 | 中等 | 高 |
典型频率 | 3.2–6.4 Gbps(有效) | 16–21 Gbps(有效) | 4.8–6.4 Gbps(有效) |
制造成本 | 高 | 中等 | 较低 |
典型应用场景 | HPC、AI加速器(如Nvidia A100/H100) | 游戏GPU(如Nvidia RTX、AMD RX系列) | 个人电脑、服务器工作负载 |
这样一对比,HBM的优势与挑战也就显而易见了。HBM的优势就是:
(1).提供更高的带宽以满足计算密集型任务需求。
(2).高度集成,减少主板空间和功耗。
(3).低延迟设计,有助于提升系统响应速度。
其挑战包括了:
(1).成本高:TSV和硅中介层技术复杂,增加了生产成本。
(2).热管理:高堆叠层数导致热密度增加,需要有效散热方案。
(3).制造难度:封装和互联工艺对精度要求极高,影响良率。
HBM技术将不断进化,HBM4可能出现:更高堆叠层数(>16层)、更低功耗设计、更快的I/O速度(>20 Gbps)。
总之,HBM在高带宽、低功耗、低延迟、紧凑设计上具有显著优势,非常适合 AI训练、HPC、高端图形处理 等专业应用场景。尽管成本较高,但其性能对于这些领域来说是无可替代的。而 GDDR 和 DDR5 则因功耗、带宽和延迟的限制,更适用于消费级和通用计算领域。
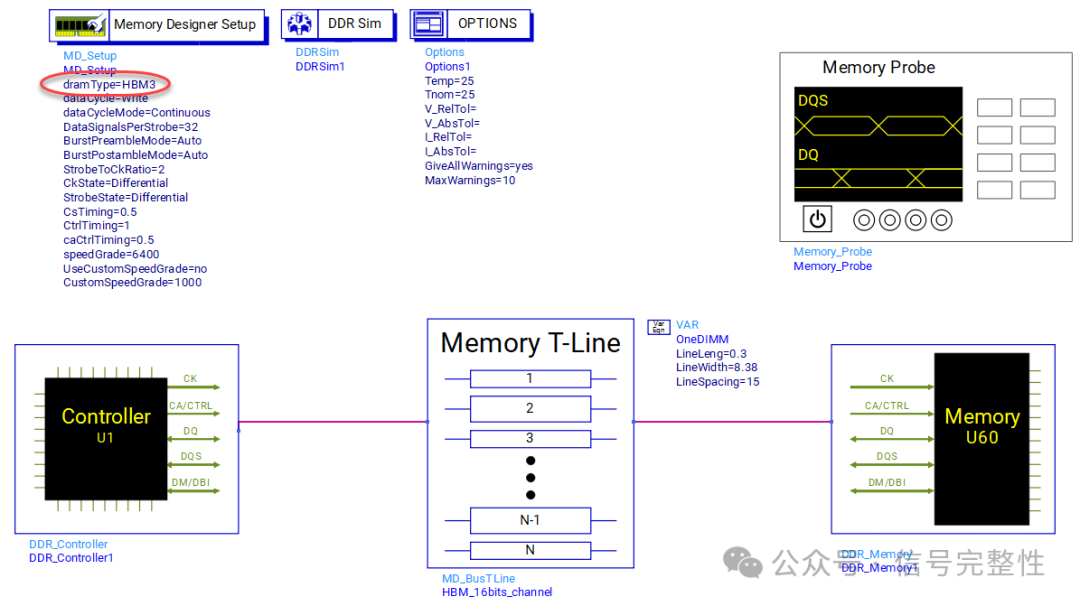
HBM信号完整性设计将在更高的数据速率和更高堆叠层数下,面临更大的技术挑战,信号完整性仿真也是必不可少。HBM信号完整性仿真是一个多维度的复杂过程,从HBM的设计到应用,涵盖频域(封装和PCB)、时域(眼图)和电热协同分析。通过高质量的仿真模型和工具,以及精确的参数优化,可以显著提升HBM的性能和可靠性,确保其在高性能计算和AI领域的稳定运行。如下是在ADS中进行HBM3的仿真原理图:
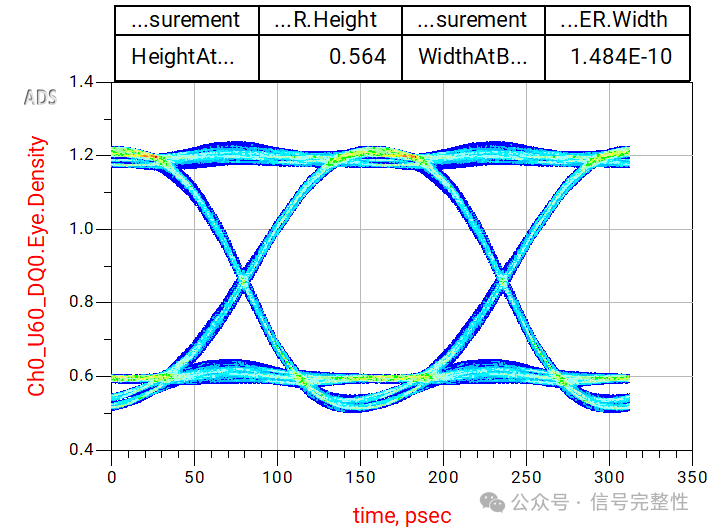
信号速率为6.4Gbps的仿真结果如下图所示:
 文章来源于信号完整性,作者蒋修国================================
文章来源于信号完整性,作者蒋修国================================一种大幅提升AI SoC芯片设计的方法
SoC 设计优化相关资料推荐











