
您可识别下方二维码收听昨晚的直播内容,解放您的双眼:

作者简介:

韩建飞
京东商城 基础平台部 资深架构师
京东弹性计算部门,负责 Docker 容器和 Linux 内核。2014年加入京东,重点在京东基础平台 Docker 容器二次定制开发和 Linux 内核 JD 版本优化维护,运营多个中大规模 IaaS 集群,包括(京东弹性云、公有云、混合云等产品)。
在 Linux 内核优化、Docker 二次开发,自动化部署、KVM、分布式系统等方面有丰富的实践。
服务过中兴通讯等IT公司,负责和参与中兴 IPTV,CDN,软件平台,中兴自研分布式存储系统等开发维护。
前言
为什么用多快好省这四个字?体现在哪些方面呢?
多 - 京东商城目前所有的业务均运行在弹性云1.0平台上,目前容器规模是15万+。
快 - 我们的运维团队人数并不多,大概两、三个人左右,京东现在有五六千个业务,这么多业务分布在这么多的容器上,维护的压力其实是很大的。
但是我们有完善的运营维护机制,如果出现问题,及时响应速度非常快,出了问题我们马上处理马上进行分析和回溯。
好 - 我们的容器在2014年的时候开始上线,到目前为止经历了三年时间,目前为止没有出现过大的影响业务的故障,也没有一个 COE,目前运行相当的稳定。
省 - 其实是从运维的角度来讲的,因为原来传统的物理机运维要上线的话得找运维工程师操作,有了弹性云v1.0这个之后,我们现在的运维上线流程变得非常简单,提交一个申请,后台处理就上线了,节省大家的时间也节省了人力物力。
相对来说,传统的运维就是要上线的话得运维工程师帮着上线,如果说某个业务上线的时候出现了问题,所有后面的上线任务都得排队,拿着小板凳在后面等,处理好了前面的问题,后面的业务才可以继续上线,这样就很耽误事儿。
本文主要写这几个方面:目前京东弹性运维的版本弹性云1.0线上运营情况、弹性云1.0遇到的挑战分享、弹性云1.0的主要架构、弹性云1.0的一些经验分享、容器的稳定性和性能的提升和现在正在进行的弹性云2.0的启航工作。
1. 弹性云V1.0线上运营情况
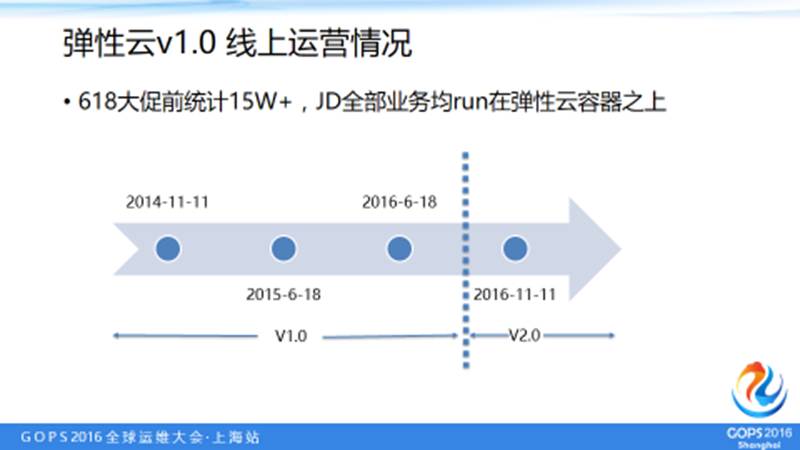
这个是京东弹性云推行的一个主要时间戳:
大概在2014年双十一前面开始构思京东自己的私有计算平台,其实当时的选择也有很多,可以用容器、虚拟机以及现在也比较多的 Caas 平台,但最终我们确定了用容器来做业务。
经历过2014年、2015年每次大促业务都翻番的状况后,从去年底我们开始规划弹性云2.0,增加了很多新的特性,主要的架构也进行了变动,这是我们大概时间戳的情况。
2. 我们的挑战

挑战1:选择
为什么当时考虑使用容器?
大部分人都知道,想上一个新的系统,若非从上到下的政策强推,业务方一定会各种质疑:
新的系统是否稳定?
性能和原来的物理机相比究竟怎样?
是否用得习惯?
是否有很大的改变?
……
所以我们主要考虑这三个方面:
第一,兼容性,新的系统需要兼容老的运行环境。
京东老的运行环境是在物理机上,所以我们当时考虑弹性云时,需要适应业务对于物理机比较熟悉的情况。
第二,物理性能,采用虚拟机相关技术,相对于物理机总有一定性能的损失,比如说直接使用虚拟机或者在虚拟机基础上搭建的 Caas 平台。但在当时正好容器的概念刚刚兴起,我们就想尝试一下用容器。
第三,安全性,我们知道容器的隔离安全性并不像虚拟机这么好,他还是使用的 cgroup 相关的隔离的属性。操作系统的很多的特性还是公用的,比如说内核,一些参数的设置等等。
但是这些属性其实在私有云环境下都是可以避免的,私有集群主要为内部客户提供服务,相对稳定,性能损失较少。安全性其实相对比较好实现,因为私有云在内部,外面看不到,网络隔离、租户都可以不用,在当时的情况可以不用很好的考虑这个事情;而操作系统相关的隔离,可以通过业务约束来实现目的。所以我们当时选择了用容器。
挑战2:向前兼容
我们不可能把所有的业务一下子都部署到容器上,现在做的系统考虑了向前兼容和物理机的情况。虽然当时业务对于容器这个东西还是持比较怀疑的态度,但我们自己还是比较有信心的。
挑战3:第一个核心系统用哪个?(单品页)
一开始,在京东开始推广容器的时候配合我们的业务是京东的单品页业务。
单品页,就是京东商城每件物品销售时的详情页,是一个非常重要的业务方。
新系统上线一般是找一个不是重要的系统先上一段时间观察一下是否稳定,然后再过渡到核心业务甚至是全部业务。
但我们当时想上一个比较核心的品类,因为核心系统比其他系统承受的流量和压力都要大许多,如果核心系统部署在弹性云中都稳定了,那在业务推广的时候,其他的业务方更加能接受,推广的效果也会更明显。
现在我们在核心的系统上表现非常稳定,推到其它的系统上就比较好推。
现在看来当时推弹性云落地是一个比较明智的策略,先在核心系统上跑起来,再推其它的系统,逐步覆盖全部业务系统。
挑战4:容器的性能和稳定性
容器的性能和稳定性相当重要,与虚拟机不同的是,虚拟机是强隔离的。但是容器不一样,容器的许多东西都是整个宿主机共享的,这样有可能出现一些问题会导致这台机器所有的东西都会受到影响,这是我们当时比较着重考虑的一个非常主要的方面,就是容器的性能和稳定性。这方面,后来我们通过规范业务使用方法来规避。
挑战5:大规模
到目前为止京东所有的业务都跑在容器上,15万个容器,这是比较大的规模。
挑战6:运维成本
我们的弹性云运维只有三人,三个人维护了现在所有的容器。运维的人力虽然不是很多,但是我们能把目前整个弹性云集群维护的很完善。
3. 弹性云1.0架构
1.0架构做的时候是2014年,目前这套系统运行比较稳定,从去年年底开始规划弹性云2.0的时候已经重新架构和规划了。
这套架构是我们京东现在所有的容器的架构方式。从这个版本开始,我们在现有线上环境中基本上没有做过大版本的升级。只是合入和修改了一些bug。所以这个版本相对来说在京东上跑的非常稳定,到目前为止没有出现重大的故障。
3.1 架构展示

图中,JFS 主要是存储文件的,OVS 主要是网络,OVS 所有的转发都在核心交换机上,还有 DPDK,不是说所有的容器都有 DPDK,在网络流量消耗比较大的一些业务上,尤其是小包转发和处理上用了 DPDK,使用DPDK带来的性能提升还是相当可观的。这个就是我们整个的基本架构图。
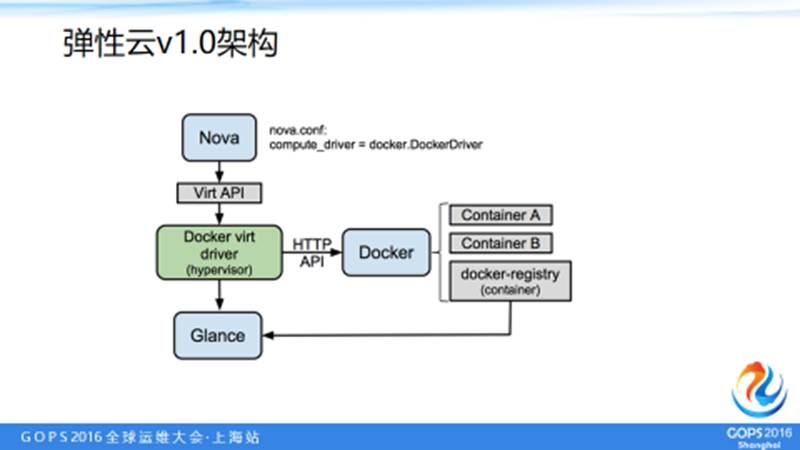
弹性云1.0的架构网络模型如上图,我们的网络做的是基于 VLAN 模型的,主要是因为在京东内部其实业务之间目前都是互相打通的,因为很多业务需要有依赖,比如说我这个服务依赖于这个节点,如果你强隔离之后反而会导致出现很多问题。
还有就是考虑简化为主的思想,所以京东的网络都是用 VLAN 模型,两个网卡,eth0 主要是作为控制节点以及一些控制的数据比如说网络传输。
容器之间的网络交换用了另外一个网口 eth1,在 OVS 做了一个很简单的事情,起一个 VETH 的虚拟网口将一端连在物理机的 OVS 网桥上,另外一端连在容器的口上,这样达到网络互通的目的。网络模型相对也比较直观,不那么复杂。
3.2 使用实例
这个是一个线上的我们为业务同事开发的平台,图片中字不是很清楚,大致介绍一下,是一个业务上线、迁移、销毁的平台。
上线主要是业务申请名称立项以及规格,对一个容器也就那么多项目,规格比如说 4C 8G或者是100G的硬盘,镜像选择,还有业务名称,然后放在资源池里面。下次有其他人过来申请,如果这台容器异常需要迁移过去,保证业务 ip 不变。
这样新的系统就上线了,因为京东许多业务都是无状态的,所以这样对于业务使用来说就不会受到影响。对于物理机和容器都是使用这一套流程对接原有上线系统,业务方操作的时候无缝切换,提高用户的亲和性。
这是一个给运维使用的系统,主要是物理资源的管理,可以看到很多指标:集群现在有多少台容器、多少个资源、使用了多少、还有多少个空闲的资源,在这个平台上都可以一目了然的看到。
另外还有异常消息追踪功能,比如说我创建一个主机失败了,我能追朔到失败的原因。
还有日常巡检功能,每天把所有的物理机以及容器相关的资源使用异常的(比如说负载很高,某些系统参数的配置不正确等)通过巡检系统发出来,用邮件发出去,可以看到故障地方有什么问题,可以提前有针对性的改进,巡检的选项也支持自己定义,简单方便。
4. 全力大战6.18

讲到弹性云2.0,很多人都会有一个疑问:会不会自动弹?
京东做的时候这块目前都还不是完全自动弹,我们当时认为完全自动弹的成本比较高,这种弹性目前还是人为不可控的。
618备战之前,大致一个月前就开始分资源,商城需要多少个资源池,无线需要多少个资源,这些都是提前规划的,根据压测的情况,需要多少资源,我们进行资源规划。
这是每年618之前都会做的一件事情,为了保证稳定渡过618,压测时对618和双十一都是正常业务量的二十倍,保证二十倍流量稳定通过。
关于纵向扩展和横向拓展的问题:京东目前弹性云1.0在目前更多的是使用纵向扩展不是横向扩展,因为我们所有的资源都是规划好的,那么在弹性的时候,业务压力非常大怎么办?
因为容器许多的配置都是可调并且实时生效的,所以在大促期间,如果核心系统业务量非常大的情况下,我们就进行纵向扩展,将部分的 CPU 或者内存等资源向核心系统中更多的调整和分配一些。
比如,台物理机上跑了十个容器,发现某个核心的系统资源使用率非常高,这个时候怎么办?
我们可以快速的将这台物理机上的比较空闲的容器资源弹到资源使用率比较繁忙的核心系统或者相对重要的一些系统的资源上去。
比如说原来是4C的,换成6C、8C的,这是一个非常迅速的过程,不过这个过程目前是人工完成的。
我们弹性伸缩的过程是非常快的,由监控系统发出告警,或者反馈,如果需要弹,整个时间控制在三十秒之内,就能完成弹性工作。
在物理机上资源的分配和回收,我们目前没有全自动化的方式来完成,依靠通过人工干预加上完备的操纵维护工具来实现。
京东现在的线上业务有五六千个,每种特点都不一样,我们会针对一个业务在双十一之前进行业务压测,调整系统的参数,改一些相关的指标做一些优化以及容器分配调度策略的优化。
另外我们发现,容器的使用上存储的性能是一个瓶颈,一台宿主机上部署多至几十个容器,但是磁盘的性能就这么大。比如针对业务进行分类,或者说计算密集型的,内存密集型的,io密集型的,业务部署的时候要进行综合考虑。
因为现在的服务器内存资源都很充足,那么在这种情况下,我们也可以针对特定业务,需要高磁盘io,但文件不是非常重要的情况下,可以把内存当存储用,提升应用的性能。
5. 容器性能提升

在稳定性方面,从2014年用到现在,小问题肯定有,但是目前相对来说还是比较稳定。
很多人原来是用物理机的,在使用上多少还是有一些差别的,这种情况下只能我们和业务方去解释差别的原因,同时来带动业务的云化升级。
5.1 硬件环境
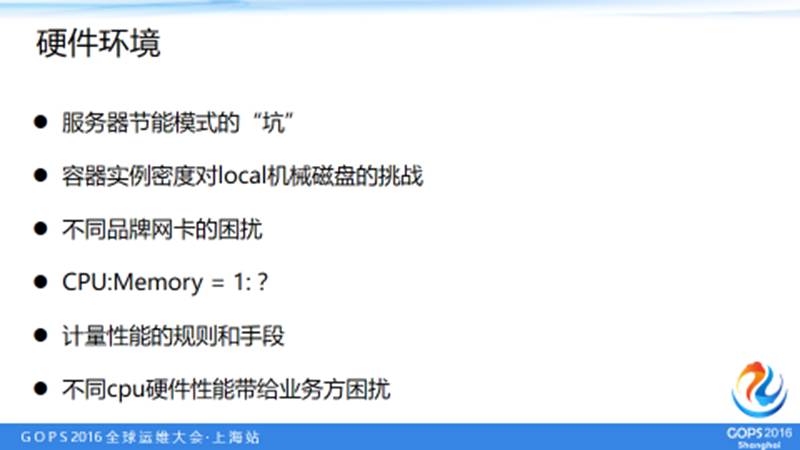
讲一个服务器的坑:当时某品牌的服务器,我们买了配置一模一样的一台服务器,运行起来后,发现一个 CPU 占用25%,一个是50%,很奇怪,因为所有的容器的环境,操作系统的环境,应用业务的环境都是一样的。
后来排查到这个是硬件服务器 bios 的一个 BUG,调到节能模式都是 max performance,功率不一样,就碰到这样的一个问题。
还有就是容器实例密度对 local 机械磁盘的挑战,另外就是不同品牌网卡的困扰,因为不同品牌的网卡,处理能力其实还是有区别的,比如说处理的中断的个数不一样。
还有包括 CPU 和 Memory 的比例、计量性能的规则和手段等,不同的 CPU 硬件给业务方带来了很大困扰。一个集群那么多机械硬件不可能都一样,但这是业务方看不到的,但你的 CPU 性能稍微差点,那个 CPU 性能稍微好点,一下子就看出来了,所以也会有很多困扰。
5.2 万兆NIC
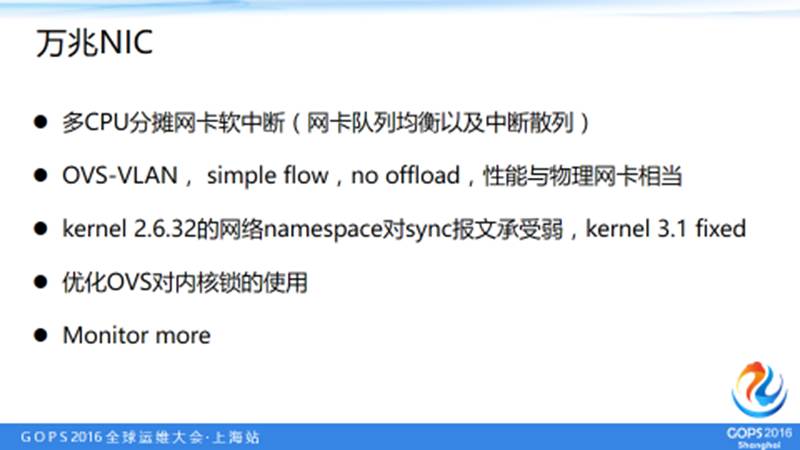
网卡中断,多 CPU 分摊网卡软中断。最终调整在网络性能的小包的吞吐量与大包的吞吐量基本上和物理网卡的吞吐量是相当的。
5.3 Cgroup:CPU

在容器的情况下,容器下的进程的调度方式都是 cfs 的模式,我们尝试修改成 FIFO 或者 RR 模式,但都没有成功。
另外业务的流量与 cpu 也不完全是呈现线性关系的,关键要看短板或者瓶颈在什么地方。
单纯 cpu 计算资源的 load 在目前我们仅使用 cpuset 的模型下,不会对其他的容器产生干扰。
cpu set 模式和 cpu share 逃逸,它带来的业务之间的干扰相对比较大,考虑到很多业务希望像原来的物理机的思维来运行这个容器,我们仅仅使用了 cpu set。
5.4 Cgroup:Memory

Memory 也有不少的问题,我们在计算内存的时候,Cache 是可以被回收的,实际计算内存使用率时,没有加上 Cache 使用的量,虽然可以统计出来这个容器用了多少个 Cache,但是 Cache 的回收策略等等是整个物理机共用的。
当时发现一个问题,小文件的吞吐量,以及每秒钟写和释放的频率非常非常快,导致了物理机的 Slab 占用的非常多,到了操作系统的极限回收门限开始回收的时候,由于要遍历大量 Slab 节点,回收非常慢,导致物理机上和容器上进程申请内存的操作都受到了影响。
当你内存申请由于 Slab 的回收而卡住的时候,整个物理机的内容会全部卡住,会影响其他容器。所以我们当时通过配置适当的回收阈值来规避解决这个问题。
5.5 Cgroup:资源及隔离
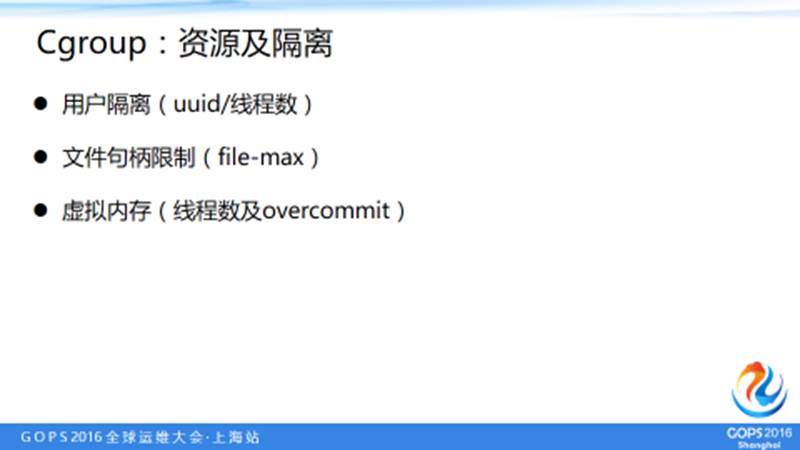
做用户隔离时,我们遇到过一个问题:因为很多业务方的应用进程的线程数起的非常多,甚至达到几万个线程。导致进程使用的堆栈开销非常大,这样的话虚拟内存就会占的非常高。当时的目的是为了控制线程数,希望目标是对每个容器的用户的线程数控制住。
后来测试发现 cgroup 在我们使用的 centos6.6 版本中并不隔离用户,好坑呀。不过新的版本好像已经解决了用户隔离的问题。
还有比如说 /proc 下的 file-max 等等。
5.6 监控
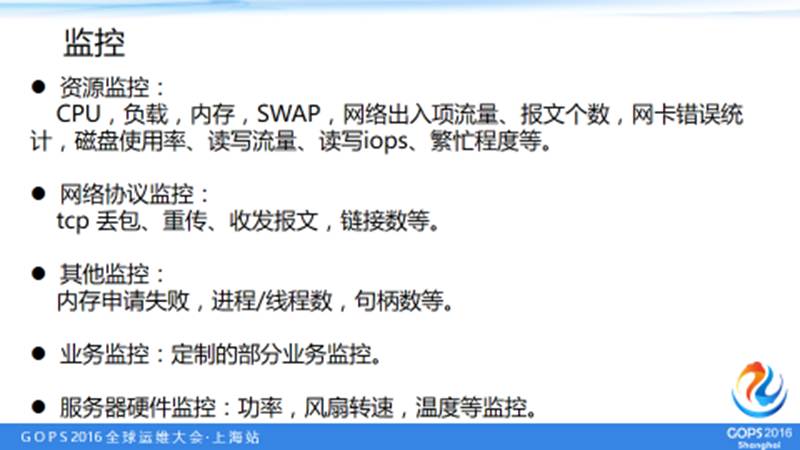
我们会监控很多东西,包括硬件和操作系统,容器和平台等等各种资源的使用。现在监控 CPU的负载、内存、SWAP,磁盘使用率,读写流量、读写iops繁忙程度等等。这些都是常用的监控。
5.7 大集群
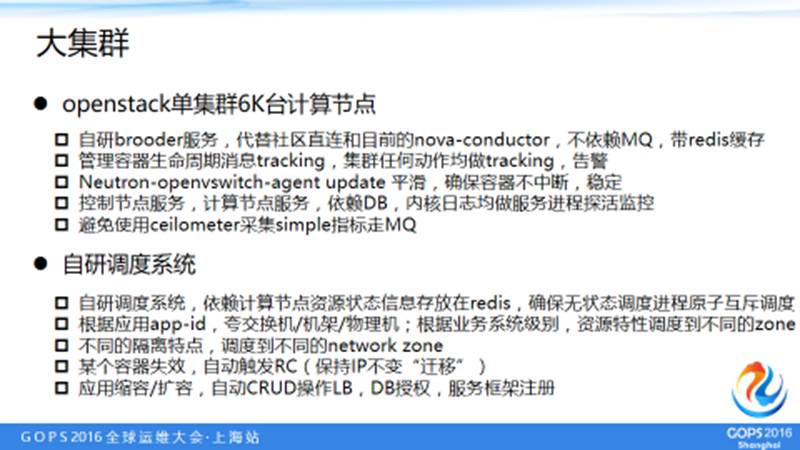
6. 未来
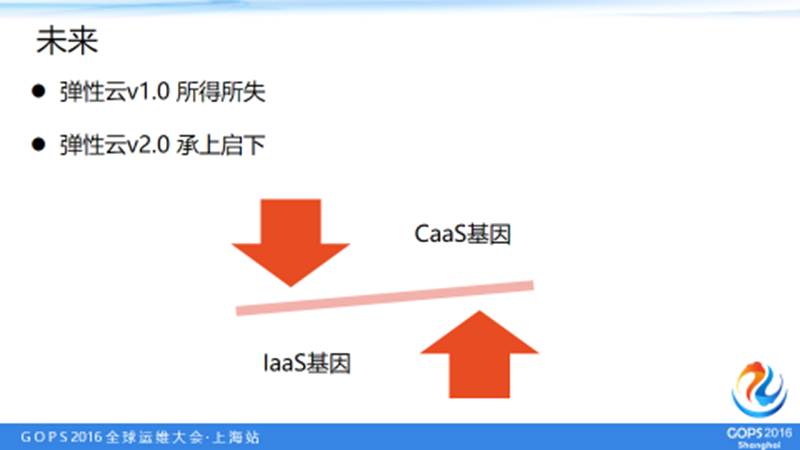
弹性云2.0未来会把服务化更加往上提一下,我们已经规划了一部分线上机器在使用弹性云2.0。
近期好文:
《携程:我们是如何利用容器实现快速弹性伸缩的?》
《支付平台架构师谈大规模高并发服务化系统设计经验》
《重塑中小企业运维价值》
《中小企业如何优雅的管理多机房服务器账号》
《别让黑客毁掉运维》
《链家网的第三种运维》
GOPS · 深圳站,只是一场与众不同的大会

来GOPS
让平凡的运维高潮迭起
会议地点:南山区圣淘沙酒店(翡翠店)
会议时间:2017年4月21日-22日
您可点击“阅读原文”,享受折扣优惠购票






