什么是声纹呢?
正所谓“闻声知人”,可见我们通过听觉来判断说话人的身份,古已有之。

说到声纹,大家肯定会想到指纹。与指纹的唯一性类似,每个人在说话过程中所蕴含的个性特征(如发音习惯)几乎是独一无二的,就算被模仿,也改变不了说话者最本质的特性(尤其在成年之后,可以在相当长的时间里保持相对稳定不变)。
声纹可以理解为是一种行为特征,由于每个人在讲话时使用的发声部位如舌头、牙齿、口腔、声带、肺、鼻腔等在尺寸和形态方面有所差异,以及年龄、性格、语言习惯等多种原因,在发音时千姿百态,因而导致这些部位发出的声音必然有着各自的特点。因此任何两个人的声纹图谱都不尽相同。
声纹识别系统的发展
声纹识别系统的开发进展主要包括在声纹确认领域的开发进展和声纹辨认领域的开发进展。
在声纹确认领域,1998年,声纹识别技术被欧洲电信联盟用在电信与金融结合的领域中。2004年,美国Beep Card公司发明了一种可以识别卡主人声纹信息的信用卡,用于确认信用卡使用者的身份。2006年,美国Voice Vault开发的声纹识别系统被用在荷兰的一家银行中,用于身份验证。2011年,中国建设银行与国内声纹识别技术最有名的得意公司合作,开发出了一款声纹电话银行系统,2013年,中国天聪公司与厦门公安局合作,搭建“报警声纹采集系统”。近些年,声纹识别技术主要用在网上交易中远程身份验证、手机用户验证解锁。

在声纹辨认领域的发展与声纹确认领域相比慢了很多,它主要被用在公安、司法以及军事国防中,因其涉及领域的敏感性,很少有系统研究进展被披露出来。

声纹的相关理论研究
声纹识别技术理论的发展主要包括在特征提取方面的理论发展与在模型建立方面的理论发展。
在特征提取方面,最早被用于声纹识别技术的是语谱图特征,科学家们通过肉眼观察完成语谱图特征的匹配,这种方法耗时耗力,且准确性不高。

摘自2010年国际万维网会议论文
International Conference on World Wide Web. 2010

语谱图
1969年Luck首次研究出语音的LPCC 即Linear Predictive Cepstral Coefficient(线性预测倒谱系数)特征,并将该特征用于声纹识别技术,提高了识别的准确度,取得了很好的效果。后来的学者提出了将基频特征作为LPCC特征的补充用于声纹识别,将系统识别准确率提高到一个不错的水平,掀起了对语音信号倒谱特征的研究热潮。在不久之后,PLP (Perceptual Linear Prediction)特征、LSPC(Line SpectrumPair)谱系数特征、MFCC(Mel Frequency Cepstrum Coefficient)特征都被研究出来,并对声纹识别技术的发展注入了更多的活力。
在模型建立方面,最早被用于声纹识别技术的是模板匹配算法,它开启了用模式匹配的方式开展声纹识别技术研究的先河;在它之后,DTW (Dynamic Time Warping,动态时间规划)、HMM(Hidden Markov Model,隐马尔科夫模型)、VQ( Vector Quantization,矢量量化)等也被相继研究出来,都取得了不错的效果。
20世纪90年代后期,Reynods提出用GMM作为声纹识别技术的模型,一经提出,GMM(C Generalized Method Of Moments,高斯混合模型)就因其识别准确率高、操作简单、鲁棒性强而被业界广泛应用,时至今日,该技术仍然活跃在声纹识别技术领域中。
2000年,Reynod提出用GMM-UBM模型(Generalized Method Of Moments一Universal Background Model,高斯混合模型和通用背景模型)弥补GMM模型对样本需求大的不足,为声纹识别技术真正走向商用做出了很大的贡献;进入到21世纪后,JFA(Joint Factor Analysis,联合因子分析)和i-vector模型被用到声纹识别技术中,克服了GMM-UBM模型中高斯分量必须相互独立的局限性。近年来,深度学习开始被用于声纹识别技术中,并取得了不错的效果。
LPC(线性预测)算法
纵向看,声纹识别系统有两个主要部分构成,一个部分是特征提取,另一个部分是模式识别。
LPC(线性预测)是非常有用的语音信号特征提取方法中的一种,其实质是:时域语音采样点之间存在关联性,某一语音信号当前的值可以使用以前的很多个语音信号采样值的加权线性拼合进行模拟,这个加权系数就是线性预测。
先计算时域语音的样点值和线性预测取样样点值的差,后取其二次方和,再用其最小值确定仅有的一个预测系数向量。
令时域语音数据的采样值序列为S(n) , n = 1, 2, 3, ... m,这里的S(n)代表时域语音采样的当前值,即在第n时刻的采样值的大小。依据以前q个取样值的加权之和来估算当前的取样值S(n)称作是q阶线性预测。预测值为:
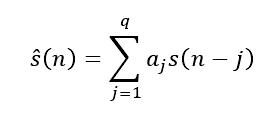
其中加权系数aj表示预测系数。语音取样值和自身的线性预测值之间的差值被称作是预测误差,用e(n)表示为:
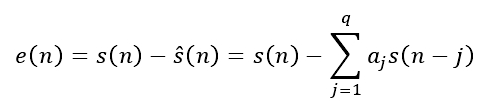
其中,预测误差e(n)能被看成是S(n)经过下面传输函数的输出:
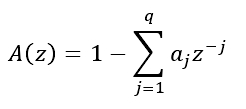
A(Z)即LPC的误差滤波器,设计它就是求解预测系数aj,使预测系数e(n)在某个准则下最小,此过程称为LPC分析。
线性预测的实质为得到一个预测系数向量a1, a2, ... aq,就是语音信号生成模型的系统函数H (z)的参数,满足预测误差e(n)在特定情况下最小。
这里的特定情况通常指均方误差 取最小值,表示先取误差的平方再取平均值。
取最小值,表示先取误差的平方再取平均值。
线性预测系数可以反映说话者简化后的发音特征,即声道特征。其流程图如下:

最后祝愿声纹技术在AI的土壤里蓬勃发展,希望可以在特长的领域里发挥独特的作用。








