
AI 科技评论按:「Deep Learning」这本书是机器学习领域的重磅书籍,三位作者分别是机器学习界名人、GAN的提出者、谷歌大脑研究科学家 Ian Goodfellow,神经网络领域创始三位创始人之一的蒙特利尔大学教授 Yoshua Bengio(也是 Ian Goodfellow的老师)、同在蒙特利尔大学的神经网络与数据挖掘教授 Aaron Courville。只看作者阵容就知道这本书肯定能够从深度学习的基础知识和原理一直讲到最新的方法,而且在技术的应用方面也有许多具体介绍。这本书面向的对象也不仅是学习相关专业的高校学生,还能够为研究人员和业界的技术人员提供稳妥的指导意见、提供解决问题的新鲜思路。
面对着这样一本内容精彩的好书,不管你有没有入手开始阅读,AI科技评论都希望借此给大家提供一个共同讨论、共同提高的机会。所以我们请来了曾在百度和阿里工作过的资深算法工程师王奇文与大家一起分享他的读书感受。
分享人:王奇文,资深算法工程师,曾在百度和阿里工作,先后做过推荐系统、分布式、数据挖掘、用户建模、聊天机器人。“算法路上,砥砺前行”。
「Deep learning」读书分享(三)
第三章 概率和信息论

接着第二章之后分享的是「深度学习」这本书的第三章概率和信息论。

这节课会讲到一些基本概念,常用的分布,频率学派和贝叶斯学派的差别,还有贝叶斯规则,概率图,最后是信息论。这里第四条可能很多人可能头一回见到,学了那么多概率,连这个都不知道,那你的概率真的白学了,真这样,不开玩笑。不过,老实说我也是前几年才知道这个学派的差别,因为浙大三版教材上就没提到这些,好像就提到一点,频率学派就是古典概率,没有什么其他的,这也是现行教材的缺陷。

概率的概念就是描述一个事件发生的可能性,比如说今天下雨吗?我们平时的回答里面可能有一些口语化表达,比如可能、八成、好像会、天气预报说会。这是一种可能性或者一种可信度,怎么用数学方法去衡量它呢?就是通过概率。
为什么每一个事件有一些可能性?有时候可能发生、有时候可能不发生。它是由多种原因产生的,因为任何事情都存在一定的不确定性和随机性,它的来源第一个叫系统本身,也就是这个事件本身的随机性;第二个,即使你了解了系统的一些基本特性,在观测的时候也不一定都是准的,因为观测还会有随机误差,比如测量时设备因素;第三,比如你观测的变量上有一些事件是服从正态分布的,这个正态分布真的就是对的吗?也不一定,所以存在一个不完全建模的问题。这是不确定性和随机性的三种因素、三种原因。
概率就是对不确定性的事件进行表示和推理。书里面提到一点,就是往往简单而不确定的规则,比复杂而确定规则更实用,这个怎么理解呢?像第一句话,多数鸟儿会飞,这个好理解,但是其实第一条很不严谨,因为它有很多情况,有些鸟本身就不会飞(企鹅、鸵鸟),有些幼小、生病也不会飞;如果严谨一点,表述成下面“除了什么。。。什么。。。以外的鸟儿都会飞”,听着都累。这就是简单而不确定的规则比复杂而确定的规则更实用。
机器学习里面有一个类似的概念叫奥卡姆剃刀也是一样,简单的模型能满足差不多的效果就可以了,比那些复杂的模型、准确度高一些的要好得多。

事件有几种分类。必然事件,太阳从东边升起西边落下是必然的;不可能事件,1+1不可能不等于2(这个不要钻牛角尖,这方面的段子很多,千万别跟我说陈景润证明1+1不等于2,我跟你急);买彩票中了五百万,这个概率是非常小的,即小概率事件。小概率怎么度量呢?就是正态分布里面三倍标准差以外,跟那个μ±3δ相关。
这是事件发生可能性的度量,三种类别:必然事件,随机事件,不可能事件
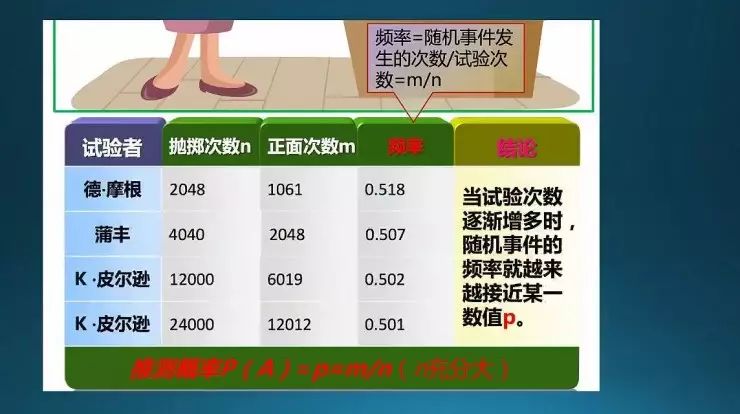
前人做了一些实验——抛硬币,观察出现正面的可能性。可以看到2048次还是0.51,然后越来越多的时候,趋近于事务本身:抛硬币时,正面反面应该是1/2的概率。就是说实验次数越多,它越趋近于事件本身发生的概率,这个也叫大数定律。(注:皮尔逊真傻,扔了3.6w次,哈哈,科学家好像都挺“傻”的)

随机变量有两种分类,按照它的取值空间分为离散和连续,不同的分类有不同的概率密度函数。连续时是PDF概率密度函数,离散时是概率质量函数,对应不同的求解方法。这个在机器学习里面也会经常区分,如果是离散的,那么就是分类问题;如果连续的就是回归问题,这是一一对应的。
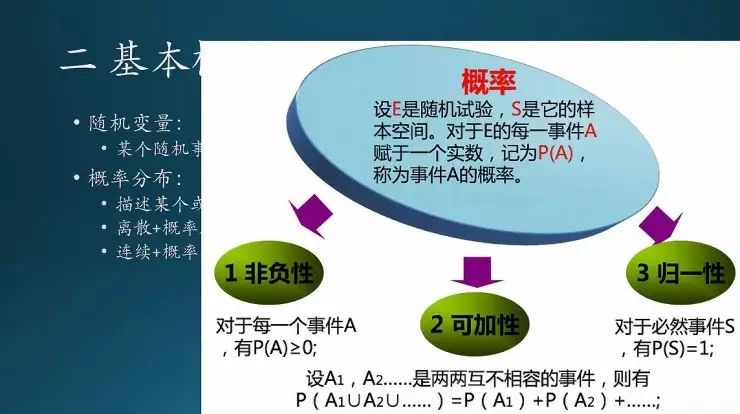
概率会满足一些性质,非负、可加、归一,归一就是和是1。

这是离散型的概率分布,X这个事件取得X1、X2等等情况的可能性。这是离散概率分布,如果是连续的话就变成积分的形式了。

这几个表达式我们见得多了,均值、方差、协方差。注意一点,方差前面的分母是N-1,因为这个地方用到的是期望,期望已经用掉了一个自由度,所以这个地方自由度要减一;这地方要注意,要不然的你算方差的时候这里是N就糗大了。
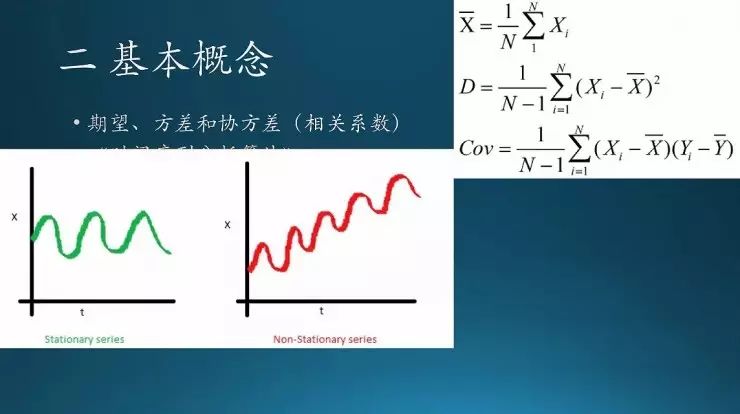
这个是时间序列,里面检验一个序列的平稳性,要知道它的期望是一个常数还是方差是一个常数。期望类似均值。图中绿色序列的期望是固定的,红色序列的期望是变化的。
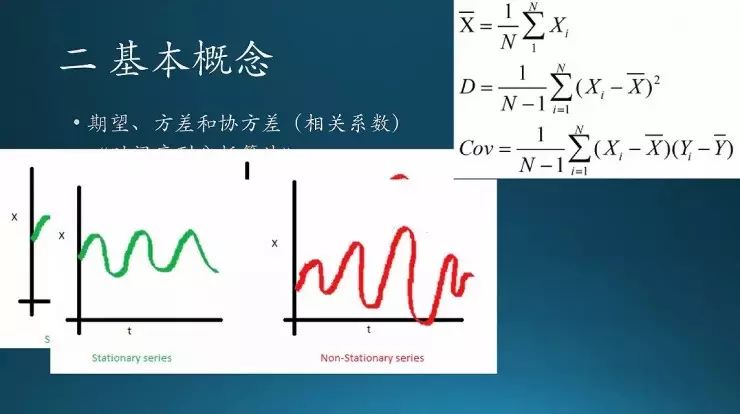
方差是每一次的波动幅度要一样,图中绿色序列的方差是固定的,红色序列的方差是变化的。
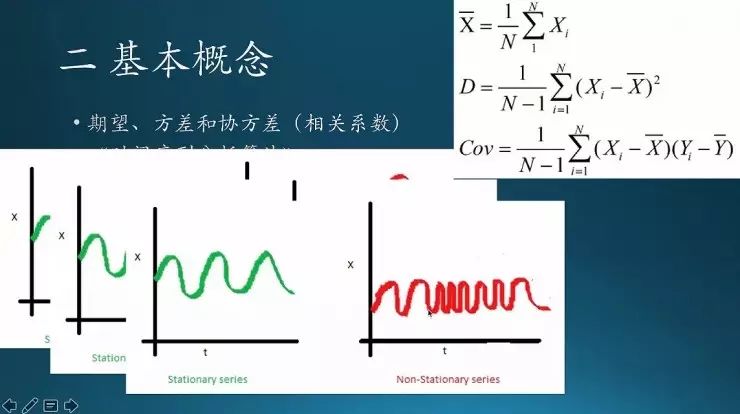
还有一个叫协方差,自己跟自己比的话,每一次变化的周期要一致。像这个红色序列前面周期比较长,后面周期变短,然后又长了,它的周期就一直在变化,这个也是不稳定的。
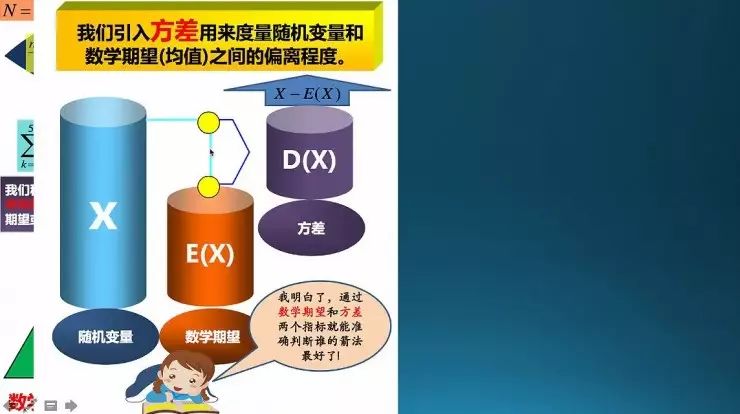
方差的形象理解,就是期望对每一个值之间的差别,取平方、求和取近似均值(除N-1)。
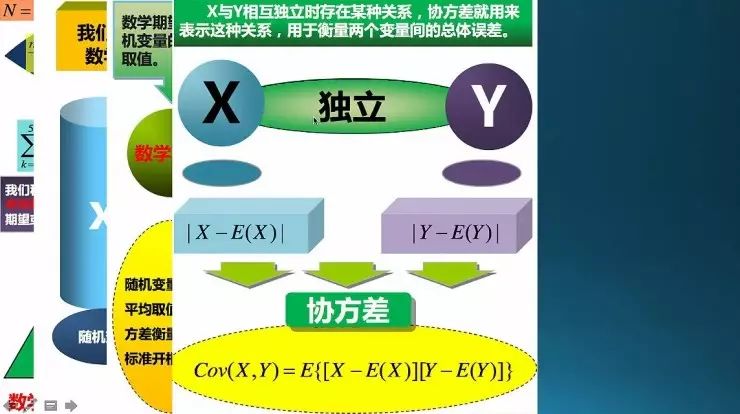
协方差是衡量两个变量,两个随机事件X和Y之间的关系;这个关系指的是线性关系,不是任意的关系,如果X和Y成非线性关系,这个协方差解决不了,这是要注意的地方。
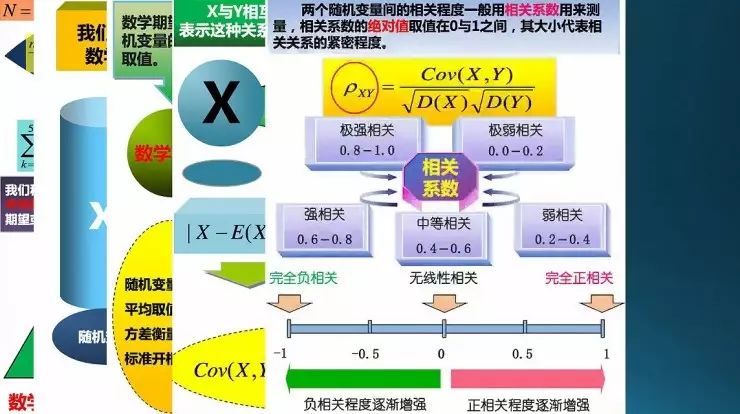
这个是相关系数,就是用的协方差,然后除以它的两个方差D(X)D(Y);如果相关系数在不同的取值范围,表示有不同的相关度。0就是完全没有线性关系,-1是完全负相关,1是完全正相关;这都是指线性关系。
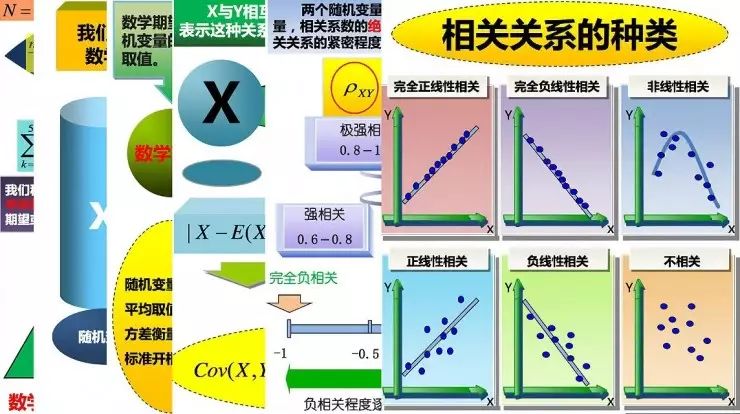
这是一个图形化的解释,线性就是这样,在二维空间里面的一条直线,有斜率;这种非线性的用协方差是度量不了的。

介绍几个概念。边缘概率是,如果联合分布涉及到x、y两个事件,那么固定x看它的平均分布,这叫边缘概率。条件概率是在一个事件发生的时候,另外一个事件的概率分布。
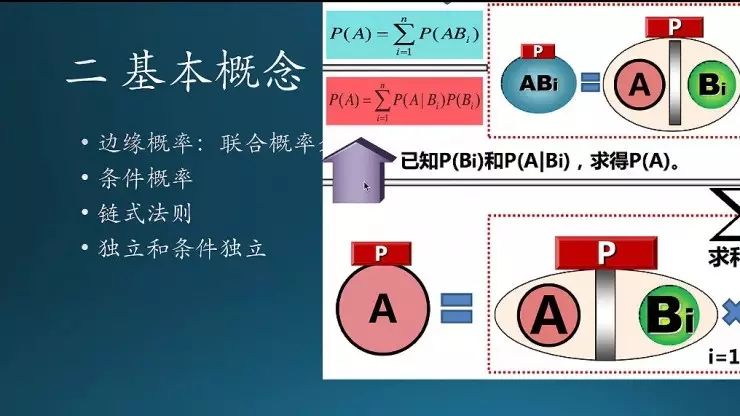
这个是全概率公式,是求B事件发生时候A的发生概率;B可能有多种取值,每种取值情况下都要算一下。

链式法则是,有可能有多种依赖。像这个联合分布里面,A、B、C三个事件,需要C发生且B发生,然后B和C同时发生的时候A发生,这就是链式法则。

这是概率里面的几个重要概率。条件概率和全概率刚才已经说了,贝叶斯是基于这两个基础上的。

这是「生活大爆炸」里面Sheldon在验算这个。

常用的概率分布,均匀、伯努利;范畴分布里面就不再是一个值,而是多个值,实验一次有多种结果,相当于扔的是色子,而前面扔的是硬币,那么硬笔只有两种取值;还有高斯分布,也叫正态分布。
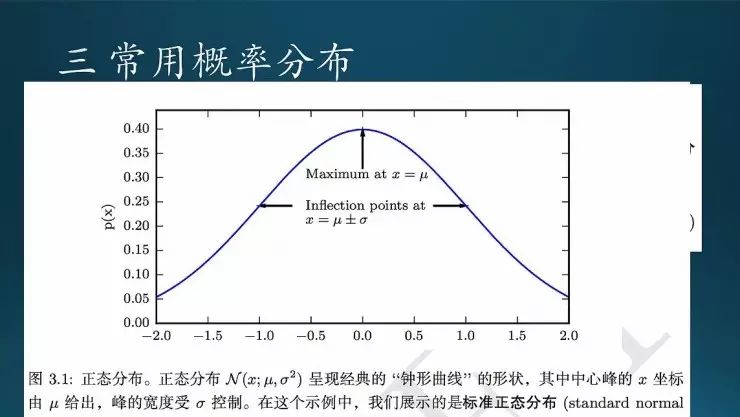
这正态分布的钟形曲线。对于标准正态分布,均值是0,标准差为1;这个图里覆盖的是正负两个标准差的范围,这不是我们常见的画法。一般画图的时候会画到正负三个标准差,这个范围内曲线下的面积是总的99.7%。
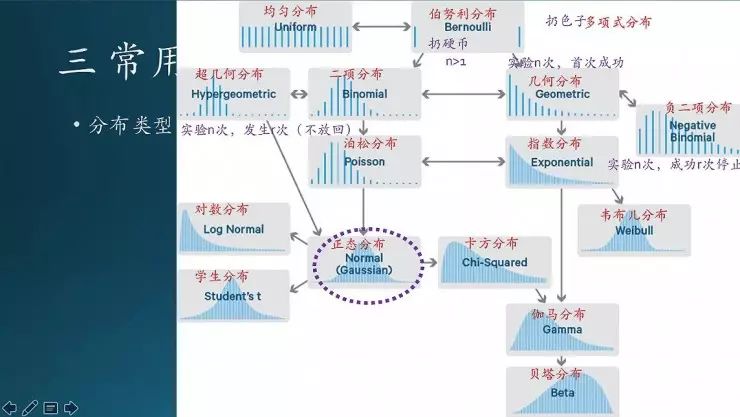
这是我单独整理一张图,几种概率分布之间的关系;它们之间的变化是有规律的。
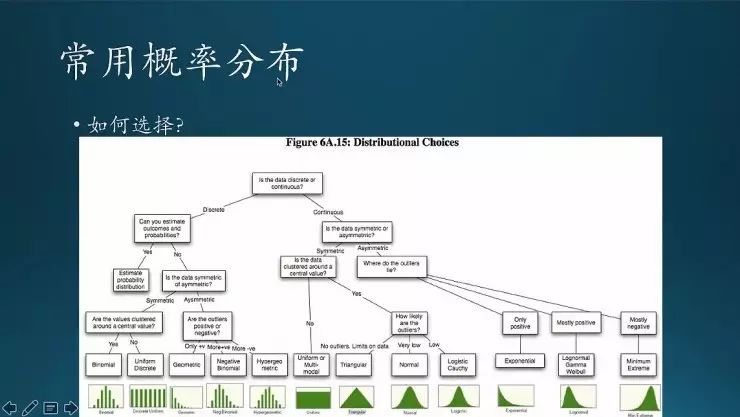
这张图是碰到什么情况下该用哪种分布。先不细说了,大家等到以后用了再说。

中心极限定律就是,多次随机变量的和,把它看成一个新的随机变量的话,它也是近似服从正态分布的,就这个意思。
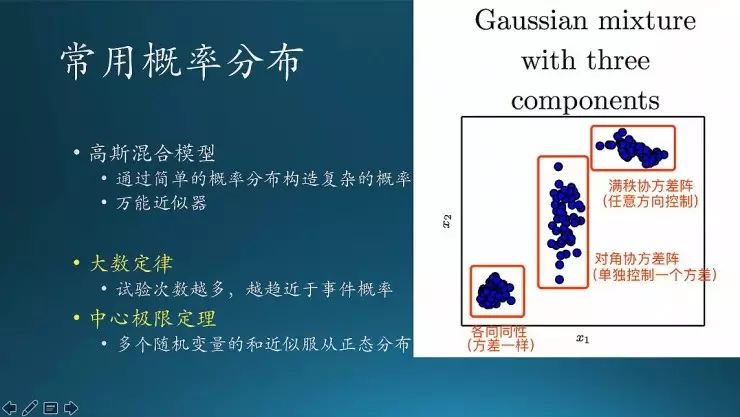
书里有个高斯分布分布,就是说刚才提到的分布都比较简单,我们能不能把它们整合起来,设计我想要的分布。这就用到高斯混合模型,这个图里面他构造了三种概率分布:
第一种的表述是“各向同性”,其中x1、x2两个变量的分布的方差,必须一样。那么从整个形成的几何形状看来,这些数据点就像一个球形或者是圆形。每一个方向的方差是一样的,是规则的形状。如果不满足就变成二和三的情形。
第二组是用一个对角阵,就是x1和x2在方阵的对角线上,其他位置是零,控制y这个维度上面的方差,把它放大了;相当于把第一种的变化做了一下拉伸。
第三种情况类似的,把X轴也做一下拉伸;当然在Y轴方向也有拉伸,这个是说x1、x2两个变量的方向可以做任意的控制,这就是高斯混合模型的作用,可以按照你想要的分布去设计。

这里提几个大人物,一个是数学王子高斯,他和阿基米德、牛顿并列为世界三大数学家。德国的货币叫马克,十马克上面印的头像就是高斯,头像左边就是正态分布;硬币上也有。好像只有德国把科学家印在纸币上面,其他的国家基本都是政治人物,这也体现日耳曼这个民族的可怕。(值得学习)
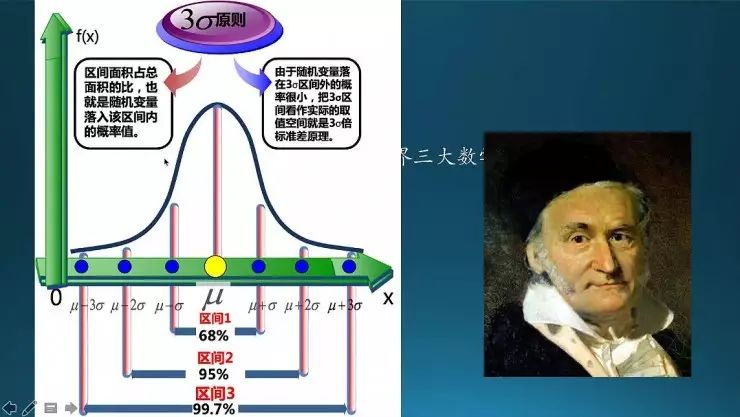
这是标准正态分布。一倍标准差、两倍、三倍的位置对应的面积不同,分别覆盖了68%、95%、99.7%。三倍标准差以外的事件就当作小概率事件,这也是它的定义方式。
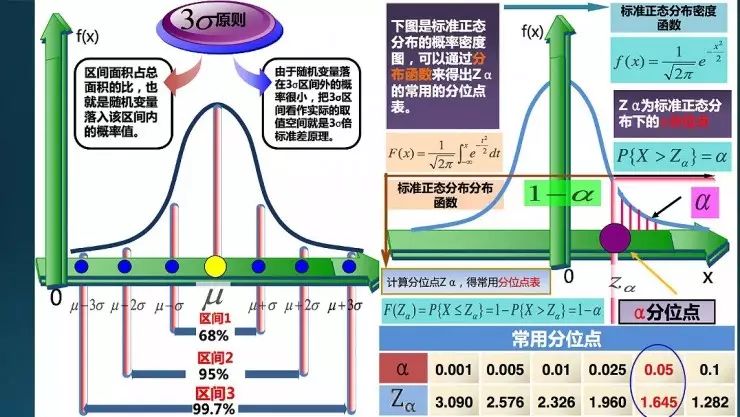
右图是一些相关用法,比如假设检验里面会验证α,也叫分位数,比如就0.05以上的概率是什么,验证一下对点估计或者区间估计的可信度。
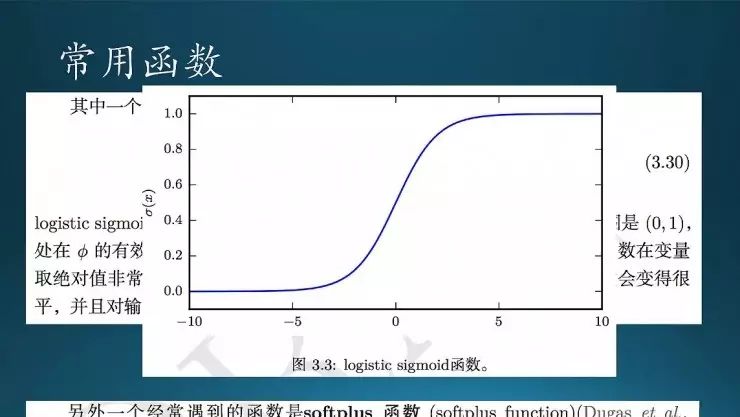
常用函数,这是一个sigmoid,它有饱和特性。
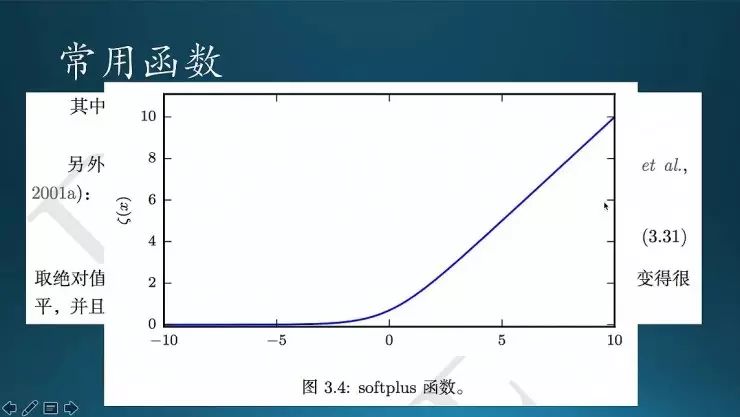
还有一个softplus,它是softmax的一种弱化;softmax从右往左下降会直接到0,在0的位置有一个突变,然后继续走;0这个点的左导数和右导数是不一样的,左导数是0,右导数是1,所以0这个点上的导数是不存在的。怎么办呢?为了数学上面好看,而且求导方便,那就把它变成softplus,在0这个点做变换之后就整个平滑起来,每个点的都是可导的。实际上在书里面也提到一点,平时其实深度网络DNN里面会经常用到ReLU,ReLU里就是softmax。softmax是ReLU的一种推广。ReLU里0点也是不可导的,就有一些规则的方法,就是如果到了这个点的话,他会给要么是0,要么是1,视具体情况而论。

这是一些概率函数的基本性质。sigmoid求导非常方便,还有其他一些特性。softplus也有一些很好的性质,(x)-(-x)起来就等于x,挺简单。

频率学派和贝叶斯学派。先讲讲贝叶斯这个人,他刚开始只是一个牧师,就是一个神职人员,滑稽的是,他做数学研究是为了研究神的存在;这个跟牛顿有点像,不过牛顿前期是不怎么研究,到老了研究上帝,最后没什么成果。贝叶斯是一个彻头彻尾的学术屌丝,在1742年就加入了皇家学会;当时也是有牛人给推荐了,他没有发表过任何论文,不知道怎么的就进去了;后来也挺凄惨,到1761年死了也没什么消息。1763年,他的遗作被人发现「论机会学说中一个问题的求解」,贝叶斯理论就从此诞生。
诞生时,还是波澜不惊,没有什么影响。直到20世纪,也就是过了几百年(对,等黄花菜都凉了,花儿都谢了),贝叶斯理论就开始越来越有用了,成为现在概率里面的第二大门派,一般提到概率就会提到频率学派和贝叶斯学派。这个人物跟梵高一样,生前一文不值,死后价值连城。贝爷(别想多了,不是荒野求生)非常非常的低调。
还有一个更加悲剧的数学天才——迦罗瓦,他是群论的创始人,法国人,也是非常厉害的一个天才。十几岁就提出五次多项式方程组的解不存在,论文先后给别人看,希望大神引荐、宣传一下,结果被柯西、傅里叶、泊松等人各种理由错失,有的遗失、有的拒绝,反正那些大师都不看好。然后到21岁的时候,年少气盛,一不开心就跟情敌决斗,这个情敌是个警探,居然用枪决斗,然后光荣的挂了。
当然,决斗前夜他知道自己会挂(明知要死,还有去送死,这是种什么精神?),所以连夜把自己的书稿整理一下,交代后事,这才有群论的诞生。后来人对他评判是“笨死的天才”,他的英年作死直接导致整个数学发展推迟了几十年。

上面图中是贝叶斯,不一定是他本人,因为这个人太低调,连张头像可能都找不到,没有人能够记清楚了,所以这个不一定是。下面的就是迦罗瓦,中枪倒下ing。

这是贝叶斯规则,就是条件概率。x和y是两个随机变量,y发生的情况下x会发生的概率是 x单独发生的概率乘x发生的情况下y发生的概率,除以y单独发生概率。一般拿这个做一些判别分类。机器学习里面分两大类生成式和判别式,判别式的一个典型就是贝斯规则;生成式的方法跟判别式方法区别就是,生成式尽可能用模型去拟合它的联合分布,而判别式拟合的是一种条件分布。
贝叶斯学派和频率学派最大的不同、根上的不同,就是在于模型 y=wx+b 其中的w和b两个参数,频率学派认为参数是固定的,只要通过不停的采样、不停的观测训练,就能够估算参数w和b,因为它们是固定不变的;而贝叶斯学派相反,他们认为这些参数是变量,它们是服从一定的分布的,这是它最根本的差别。在这个基础上演变的最大似然估计、或者MAP等等的都不一样。这完全是两个不同的流派。
由条件概率引申出来的贝叶斯规则。像这个a、b、c的联合分布可以表示成这样,然后它可以对应一个图,概率图。像这样。
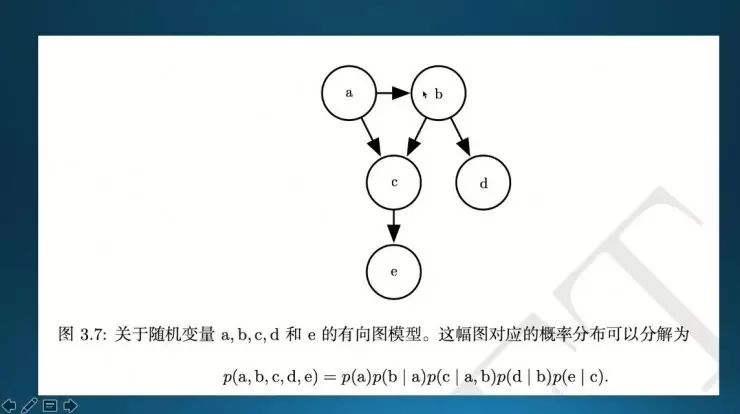
a发生、b发生是有一定的依赖关系的。一般如果a、b、c完全是独立的就好说了,那p(a,b,c)就等于p(a)、p(b)、p(c)的乘积。这个图跟TensorFlow里面的图是一回事。

下面介绍一下信息论。信息论是香农这个人提出来的,在1948年他发表了一篇论文叫“通信的数学原理”,对信息通信行业的影响非常大,相当于计算机行业的冯诺依曼这个级别。不过他的功劳一直被低估(吴军《数学之美》)。
信息论主要解决什么问题呢?第一,概率是事件发生时的可能性,怎么度量信息量的大小?第二是对于某个随机事件,比如说今天下雨这句话,到底有多少什么信息量?如果是在南方的话,可能经常下雨,那信息量不大;如果在北方或者在北极,这个信息量就大了去了。还有今天是晴天还是可能下冰雹,实际上这是随机事件的概率分布,这个分布有多少信息量就用熵来衡量。上面就是自信息,有条件分布,对应的是条件熵;还有互信息等等。
总之,信息论是建立在概率论的基础上,概率论里面基本上每一种概率都能对应到信息论里面的解释。

这是香农和三种书里面提到的三种特性:
非常可能发生的事件,它的信息量比较少,因为它确定性比较高;
而不可能发生的,或者是很少发生的,它的信息量就比较大;
独立事件具有增量的信息,刚才说的下雨就是一个例子;另一个例子是太阳从东边升起和从西边升起,这两个事件是完全独立的,两个事件的信息量可以累加起来。

这是信息论的几个概念,自信息、互信息、条件熵 。上面的公式是自信息的标准,直接就取一个对数而已,加上负号。熵就是把多种情况累加起来再取均值。
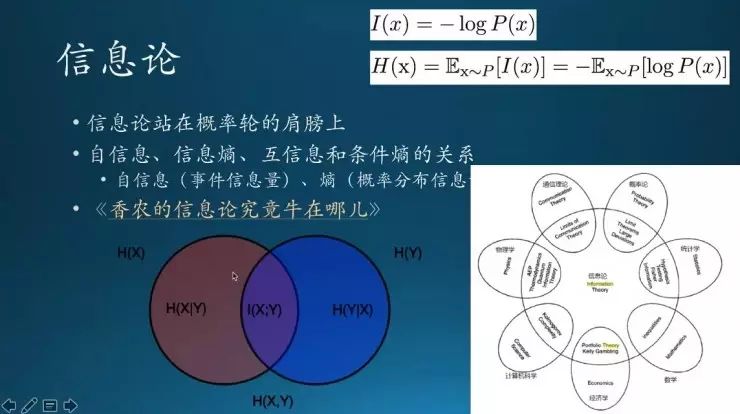
信息论现在是跟各个行业、各个领域都是密切相关的,像统计学、经济学、数学,影响非常大。
看左边的图是不同的熵之间的关系。左边整个圈是x事件的范围,中间交叉的部分是互信息。不同熵之间的关系用韦恩图来表示。
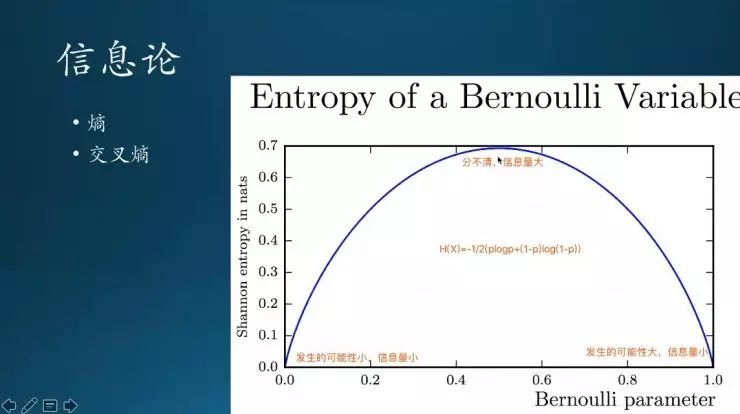
这里有一个交叉熵,也是重点提到的概念。这是衡量事件发生的概率,像左侧靠近零,说明这个事件发生的可能性很小,那么它对应的信息量较少;然后到中间0.5的地方,比如说扔硬币有两种结果,两种结果0.5基本上靠猜,完全随机了;对于这样分不清到底结果是什么样的,对应的信息量最大的;类似的到另外一个极端,就是这个事件确定是可以发生的,可能性很大的,那信息量也小。

这里还有一个KL散度,基本上是衡量两个概率分布的差异。这个公式也很复杂,你们自己去琢磨,必须要看,看一遍然后才有直观的理解。现在讲也讲不清楚。(注:信息论也可以形象起来,参考:colah's blog,Visual Information Theory)
机器学习里面还有一个交叉熵,cross-entropy,跟熵是密切相关的,它的差别就是少了一项。

这是KL散度,它是不对称的,就是说概率p和概率q的顺序调一下是不同的概念,两个顺序不同要用于不同的场景。它的目标是要构造一个概率分布 q,去近似拟合、去模拟另外一个概率分布p。这个p分布是由两个正态分布组合起来的,两个叠加起来。怎么用q拟合它呢,如果用左边的散度去度量,算分布之间的误差,这个误差对应的就是KL散度,然后根据KL散度去有方向地去调整。这是它的过程,类似于机器学习里面的过程。
如果用左边的KL散度,p在前q在后,那我们会得到这样一个结果;绿色的是拟合的概率。它的效果是保证在高概率的地方,拟合的概率要高,而不考虑低概率的部分,所以结果就会做一个平滑。概率的总和还是1,要保证归一性嘛。右边反过来,q在前p在后,那么低概率要优先保证,高概率就忽略了,那么这个拟合的概率分布就尽量往一个峰靠,只能保证一个峰。这就解释了KL散度不对称性的应用,可以按照不同的应用场景取不同的方向。

刚才PPT里面讲的大致的内容,图都是来自于「大嘴巴漫谈数据挖掘」这本书,朱向军的,这本书全部用图的方式去解释,非常好;还有「数学之美」和一些概念。
好,我这边讲完了。
AI 科技评论整理。感谢王奇文嘉宾的分享以及帮忙补充校对本文。
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————










