为了方便各位同学交流学习,解决讨论问题,我们建立了一些微信群,作为互助交流的平台。
2.告知:姓名-课题组-研究方向,由编辑审核后邀请至对应交流群(生长,物性,器件);
欢迎投稿欢迎课题组投递中文宣传稿,免费宣传成果,发布招聘广告,具体联系人:13162018291(微信同号)

【研究背景】
人工智能(AI)的广泛应用依赖于强大的计算支持,传统上这由集中式计算环境如高端工作站或云端提供。然而,这种方法存在诸多弊端:数据传输导致的高延迟影响了实时性;大量数据的网络传输浪费了带宽,增加了运营成本,并可能引发网络拥堵;更重要的是,数据在传输过程中面临被未授权访问的风险,威胁到隐私和安全。
边缘计算作为一种解决方案,通过将计算任务移至数据产生的网络边缘,有效减少了数据传输距离,降低了延迟和带宽需求,同时增强了数据安全性。但在边缘设备上进行AI训练面临挑战,因为这些设备通常计算资源有限、存储容量小。忆阻器(memristor)因其在模拟域内的并行计算能力和高存储密度,为构建紧凑、节能的AI边缘计算系统提供了新途径。不过,忆阻器阵列在实际应用中存在可靠性问题,如低产量、均匀性差和耐久性不足,限制了其在边缘计算中的应用。为克服这些挑战,研究者们致力于开发新型忆阻器材料和结构,以提高其性能和可靠性。
近日,韩国的研究团队在
Nature electronic
上发文报道了一种基于无选择器(selector-less)忆阻器阵列的模拟计算平台,该平台使用了具有渐变氧分布的界面型二氧化钛(TiOx)忆阻器。这些忆阻器展现出了高可靠性、高线性、无需形成(forming-free)和自整流等优异特性,使其成为构建高效AI边缘计算系统的理想选择。
【
研究方法
】
研究者选择了具有渐变氧分布的界面型二氧化钛(TiOx)忆阻器。这些忆阻器展现出高可靠性、高线性、无需形成(forming-free)和自整流特性。通过优化氧浓度分布,提高了线性氧浓度,实现了实时操作和设备上训练,从而在大型阵列中实现了低变化、高耐久性和高设备产量。材料分析显示,忆阻器设备通过氧离子的迁移实现电阻切换,整个开关层的迁移减轻了传统忆阻器的随机问题,导致高度可靠的开关行为。
2.硬件平台构建
构建的模拟计算平台包括一个无选择器(32×32)交叉阵列、外围电路和数字控制器。该平台能够在无需补偿操作或预训练的情况下,通过自校准在模拟域中运行AI算法。32×32忆阻器交叉阵列是硬件平台的核心,外围电路包括脉冲发生器、列多路复用器和读出电路,集成在定制的印刷电路板(PCB)上。现场可编程门阵列(FPGA)评估板生成控制信号,驱动电路运行。
【研究内容】
1.忆阻器阵列的特性分析
研究中使用的32×32忆阻器阵列展现出卓越的电气特性,包括低设备间变化(<6%)、低循环间变化(<2.8%)、高耐久性(>107脉冲)和100%的产量。这些特性确保了忆阻器在大规模阵列中的稳定性和可靠性。忆阻器实现了对多种生物突触可塑性的模拟,如短期增强/抑制、成对脉冲促进/抑制、尖峰电压依赖可塑性和尖峰率依赖可塑性,这使得忆阻器不仅适用于存储信息,还能进行复杂的神经形态计算。
2.模拟计算单元的操作机制
模拟计算单元通过应用相同幅度的脉冲并行执行乘累加(MAC)操作,自动执行量化,无需后续操作,除了读出操作。这种操作方式支持模拟数据的高密度计算,与传统数字系统相比,大大减少了所需的设备数量。单元中的忆阻器通过差分对表示正负模拟权重,通过减去它们各自的电导(G±)来实现。MAC操作的结果通过减去正负输出(OUT±)从底部电极(BE)线对中获得。这种设计不仅简化了计算过程,还提高了计算效率。
3.实时视频处理
为了验证计算单元的边缘计算能力,研究者通过直接从相机接收视频流来演示实时视频处理。该系统能够在不依赖外部硬件帮助的情况下,实时执行计算,提取关键信息并消除冗余,从而减少边缘计算系统的带宽需求和运营成本。通过实时视频前景和背景分离任务,展示了系统的实时AI边缘计算能力,实现了30.49dB的平均峰值信噪比(PSNR)和0.81的结构相似性指数(SSIM),这些值与理想情况下的模拟结果相似。
【论文插图】
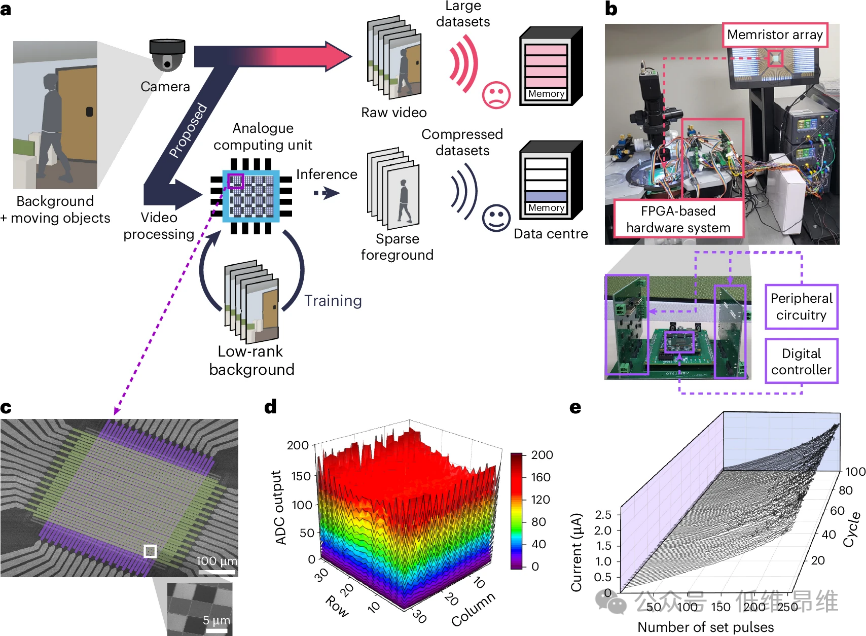
图1 |开发的用于实时视频处理的硬件平台和模拟忆阻器阵列的电气特性。a、通过具有模拟计算单元的边缘计算硬件平台进行实时视频分离的概念。视频处理通过将流式传输的大尺寸数据分为背景和运动对象(低阶背景和稀疏前景)来压缩它们,从而最大限度地减少向数据中心的数据传输。b、 开发单元的照片,带有制造的忆阻器阵列和基于FPGA的硬件系统,该系统由PCB和FPGA组成,用于阵列操作。插图,基于FPGA的硬件系统的照片。c、所制造的高可靠性无选择器32×32忆阻器交叉开关阵列的扫描电镜图像。插图,单个忆阻器器件的扫描电子显微镜图像(白色块)。绿色和紫色块分别是TE和BE线。d、ADC输出的3D表面图随着设定脉冲的数量而变化(3.2V,1µs)。在相同的行中,器件之间的差异小于6%(σ/μ)。在阵列中的所有忆阻器器件中,设置脉冲的数量以15(从0到255)的空间变化的线性增量变化,总共1024个。e、单个设备100个周期内线性和一致脉冲响应的3D瀑布图。每个电流由读取脉冲(1.6V,在设定脉冲串(3.2V,1µs),随着设定脉冲数量的增加。
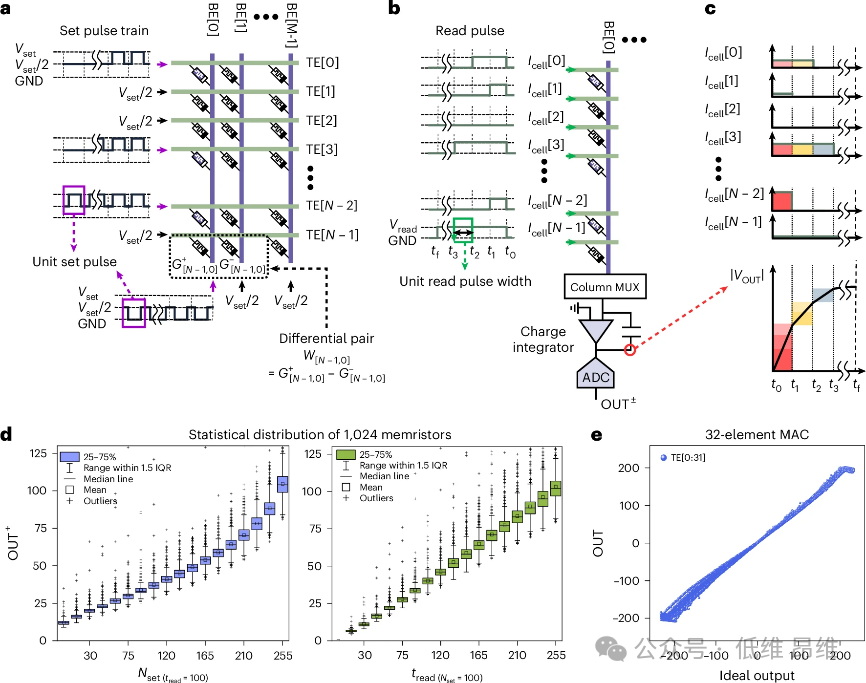
图2|模拟计算单元的架构和实验特性。a、所开发的N×M忆阻器交叉开关阵列单元的架构编程示意图。为了增强以差分对排列的忆阻器器件并通过减去G±来表示模拟权重(W),900ns)在对应于9位带符号整数值的0到255个脉冲的范围内调制。彩色器件是每个差分对内的强化忆阻器。b、阅读带有N×M忆阻器交叉开关阵列的开发单元的架构示意图。单个脉冲(1.6V)的调制宽度对应于0到255个时间单位(tn
−
tn
−
1)范围内的8位无符号整数的每个位。由电荷积分器和8位ADC组成的读出电路连接到BE线。8位无符号OUT±通过ADC从积分电荷转换而来。

图3 |使用开发单元实现的视频处理和实验数据。a、用于实时视频处理的模拟计算单元示意图。通过使用相同的计算单元对原始视频数据(Y,输入帧)应用两轮矩阵乘法来获得低秩分量(L,背景)。通过第一次矩阵乘法计算潜在变量(Z),并使用基于预训练W的模拟计算从32×16视频数据的输入和处理输出的代表帧Y.b中减去L,得到稀疏分量(S,前景)。模拟计算硬件中的非理想性导致了包括垂直渐变和水平线在内的结果。c、实时视频处理,使用未经训练的重量进行设备上训练(左),考虑到自动硬件缺陷的正确性,自动校准模拟计算硬件的非理想性。在设备上训练后进行实时推理(右),执行背景和前景分解,而无需进一步更新参数。d、每帧当前W与设备训练后的W之间的均方误差,以显示W的收敛性。五个黄色箭头表示在图c中选择的帧索引处的均方误差。
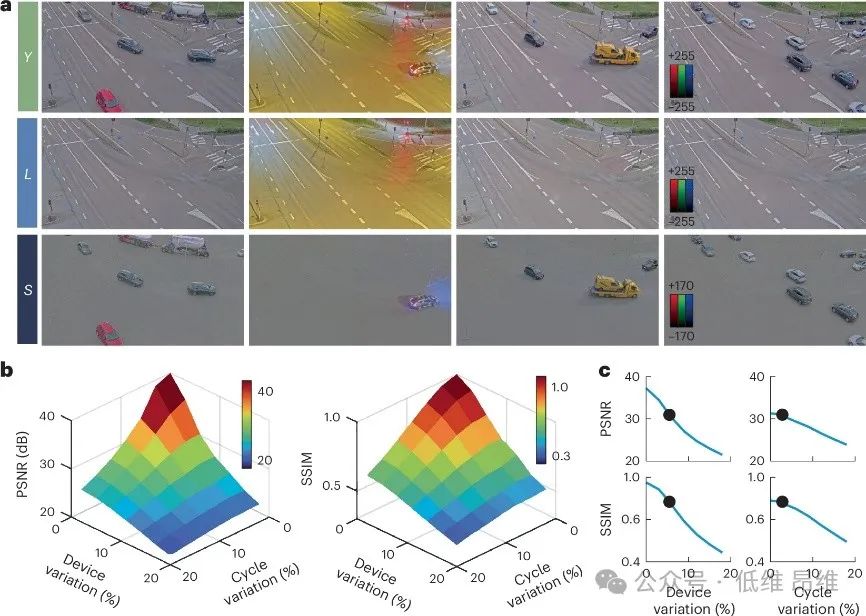
图4|不同设备变化条件下的大尺寸视频处理结果。a、1180×648像素RGB视频的视频处理结果,通过使用15个大型忆阻器阵列实现,每个阵列的尺寸为1180×1296.b,使用PSNR和SSIM评估不同周期变化和设备变化程度下的分解精度。c、分解精度,同时将设备变化保持在5.5%(左),循环变化保持在2.8%(右)。黑点表示在我们的计算单元上进行的实验测量得出的条件。
【结论与展望】
本研究成功展示了一种基于无选择器忆阻器阵列的模拟计算平台,该平台在AI边缘计算中表现出色。忆阻器阵列的高可靠性和优异的电气特性,结合简单的模拟架构和设备上训练能力,使该平台能够高效执行实时AI任务。通过实时视频处理任务,验证了平台的高性能和适应性,为未来开发更先进的边缘计算设备提供了重要的理论和实践基础。这些成果不仅推动了忆阻器在AI领域的应用,也为解决边缘计算中的挑战提供了新的思路和方法。
【论文信息】
Jeong, H., Han, S., Park, SO. et al. Self-supervised video processing with self-calibration on an analogue computing platform based on a selector-less memristor array. Nat Electron (2025). https://doi.org/10.1038/s41928-024-01318-6
上
海
昂
维
科
技
有
限
公
司
现
提
供
二
维
材
料
单
晶
和
薄
膜
等
耗
材







