想象一下,你走在大街上,迎面见到一个人。
这个人你不熟悉,但是以前见过她。你一下就能认出她的样子,自己也意识到「我见过这个人」。不过,如果要回想起她的名字(如果你曾经知道的话),可能就有点困难了。
这里涉及到两种类型的记忆检索。认出曾经见过的人,这是识别(recognition),回想这个人的名字则是回忆(recall)。
[1]
识别容易回忆难
不同的神经活动模式,构成不同的记忆。激活记忆有两种方式:感觉刺激,从长时记忆中提取。
如果一种感觉之前出现过,并且当前的环境接近产生最初感觉的那个环境,就能触发一个相似的神经活动模式。比如,如果你曾经见过蝙蝠侠和他胸前那个标志性的蝙蝠图案🦇,它对应的神经活动模式就被创建出来。日后再次见到蝙蝠侠的行装,甚至只是看到那个蝙蝠图案,就会激活同样的神经活动模式,回忆起蝙蝠侠来。这就是
识别
的过程。识别意味着新的感觉或多或少重新激活了神经活动模式,这样就不必再到长时记忆中搜索,因此效率更高。
与识别不同,回忆是从记忆中提取曾经存储过的项目,这时候没有类似的感觉输入,要靠长时记忆重新激活神经模式。
大部分回忆需要依靠线索来提取项目
,但是线索可能会激活错误的模式,或者只激活了正确模式的其中一部分,这都会导致回忆失败。
打个比方,你跟朋友去探险,发现了一口深井。下面有没有值得挖掘的东西呢?你们想办法照亮深井,然后用高倍探测镜朝井里望去:下面有几个大箱子!虽然还不知道是什么,但是箱子看起来很结实很精致,像是宝箱的样子。不过,如果要搞清楚箱子里面都装了什么东西,得打开宝箱(或是用什么检测仪扫描一下);如果是值钱的东西,还得想办法把它们从井里提上来,这就困难多了。
知道井里有没有东西,是识别;要把井里的宝箱「提取」出来,那就是回忆了。如果提取宝箱的绳子不够长或者不够结实,宝箱可能就取不上来。
如果说识别是一道 yes or no 的判断题:某种东西要么以前看/听过,要么没看/听过;那么回忆就是要从内存中检索相关细节,然后填写具体内容的填空题。是做判断题容易呢,还是做填空题容易?
下面是中国其中一个省份的地图,你觉得熟悉吗?
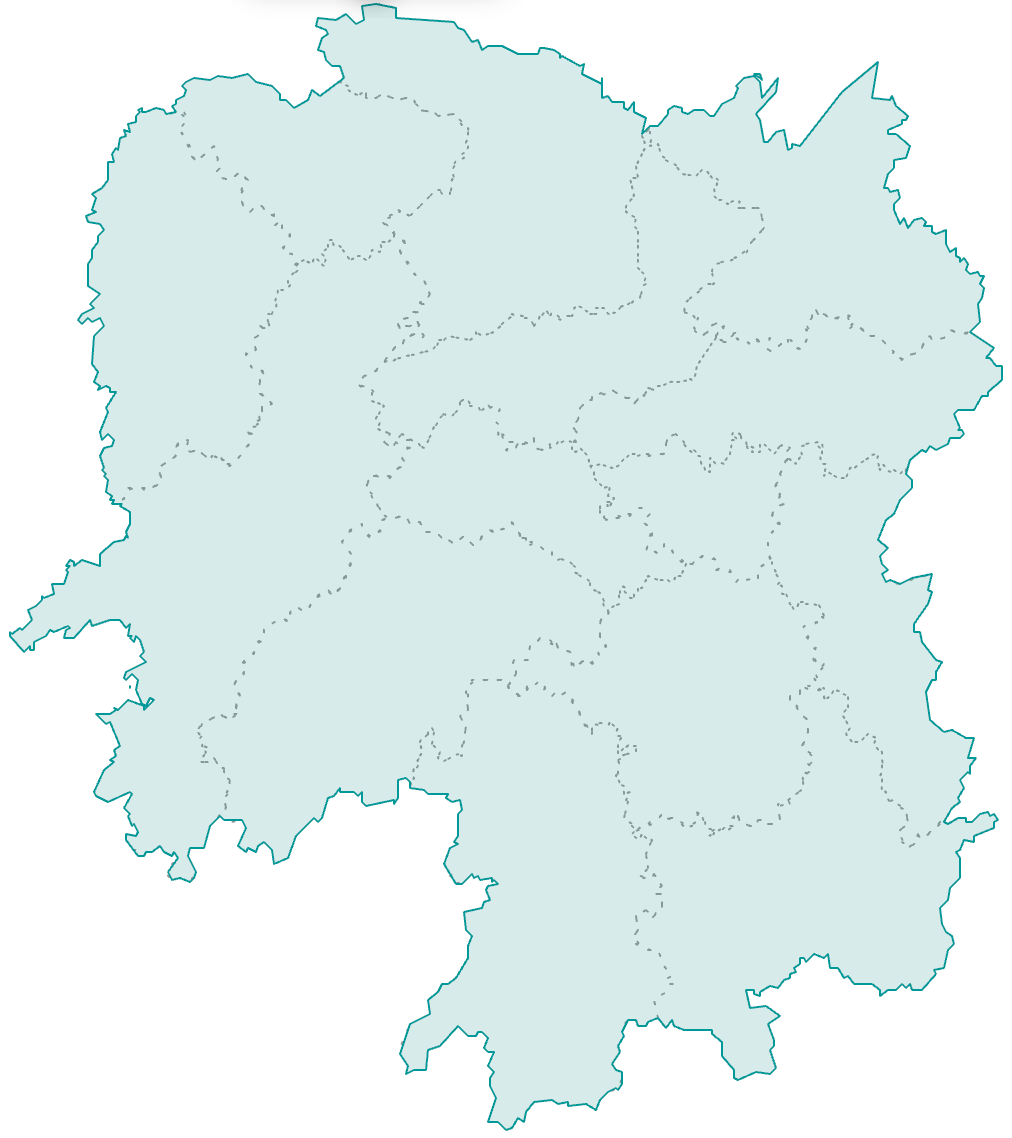
这个形状大概率你是见过的,识别出来比较容易。但是你可能一下子记不起来是哪个省份。毕竟这是一项回忆任务,需要从记忆中检索各省份的轮廓(以前未必存储过),并且跟这个形状关联起来。
如果把它放回到全国地图中,是不是更容易回忆起来呢?
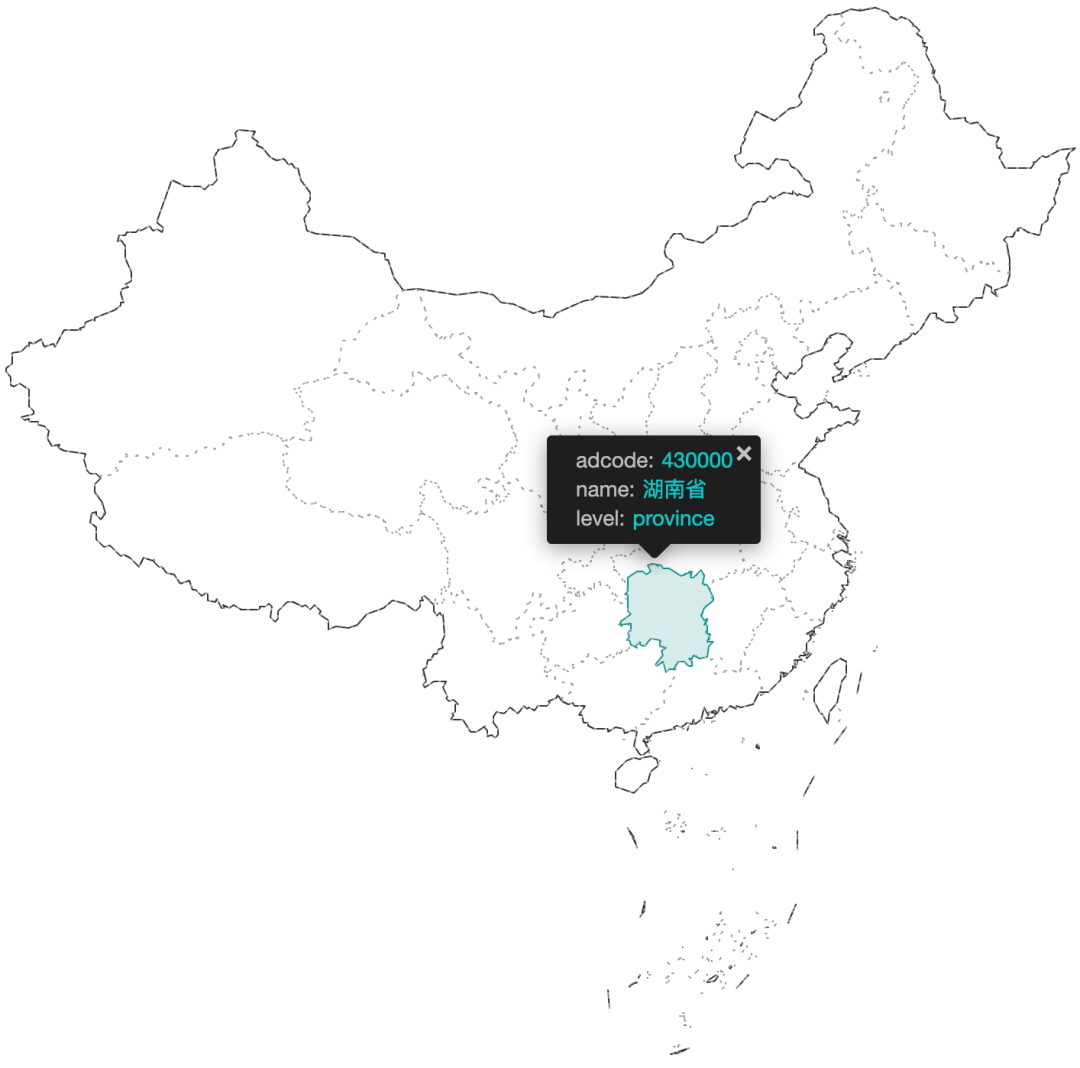
地图数据来源:http://datav.aliyun.com/tools/atlas/
经过上百万年的进化,大脑已经非常善于识别物体。而根据线索找回记忆,对生存来说就没有那么生死攸关,所以大脑一点儿也不善于回忆。于是人们发明了各种记忆术和工具来帮助自己记忆:结绳记数,故事,比喻,顺口溜,卡片,待办事项,计时器……
识别容易而回忆困难。识别时可以利用各种线索,这些线索会激活分布在记忆中的相关信息,提高了答案的激活程度。另外,识别图像(例如图标和缩略图)能加速信息的处理。而在回忆时,可以用于记忆检索的线索较少。
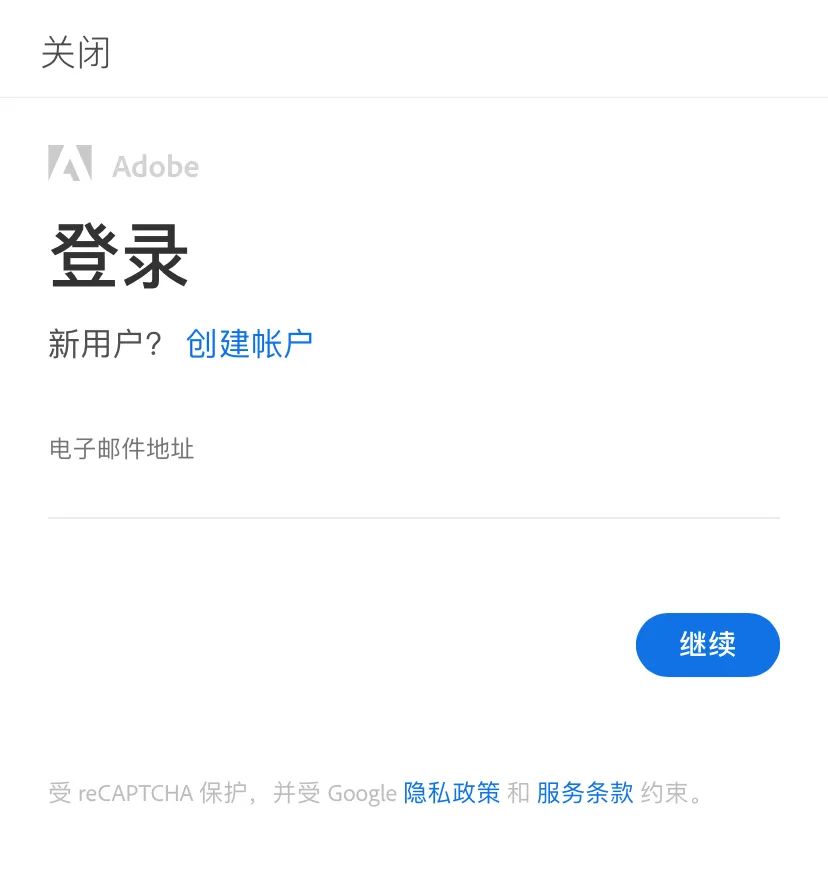
登录时必须记住用户名/电子邮件和密码,是典型的回忆型任务。用户在不同网站可能使用不同的帐号密码,要记住这些,是个艰巨的任务。所以现在有各种保存帐号密码的应用,人们再一次选择了「外包」回忆,甚至连识别都不需要了,自动登录会帮助我们完成一切(前提是你愿意承担一些风险)。
在数字界面设计中,有一条重要的设计原则:
优先让用户识别,尽量避免回忆
。
识别无处不在。亚马逊等电子商务网站会显示最近访问过的商品列表,帮助用户识别出还未完成的购买。在人们可能会消费的地方,永远不必担心会忘记些什么,产品和算法会尽其所能提醒。
有时候,我会在浏览器上打开很多页面,多到每一个标签页只剩下网页缩略图标(favicon),但是依然能快速找到想看的网页,因为我只需要识别这些缩略图标,就知道它对应什么网页。

如果我打开了很多网页,其中不知道哪一个突然开始播放声音,这时候我不得不马上中断一切事情,手忙脚乱地重新打开一个又一个网页,搞清楚到底是哪里在发出声音——我肯定记不住,回忆在这里根本不起作用。Chrome 浏览器贴心地解决了这个问题:用一个喇叭图标标识出正在播放声音的网页。这样我只需要
识别
出哪个网页缩略图标变成了📢,就可以快速找到那个标签页了。
回忆+识别策略
在日常生活中,我们经常结合识别和回忆来检索信息。一般会从一条易于回忆的线索开始,缩小选择范围,然后逐个比较结果并识别出合适的选择。比如,当我想学习交互设计知识时,经常访问一个网站:interaction-design.org。怎么找到它并打开链接的呢?
你可能马上想到的是保存网址到收藏夹然后打开。它当然在我的浏览器收藏夹里面,但是我很少那样做。因为收藏夹里面有很多分类,我连它保存在哪个分类下面都不太记得了——从收藏夹选择链接是「识别」,但是首先得「回忆」起它在哪个分类里面。这样太麻烦了,我那吝啬的大脑发出抱怨。
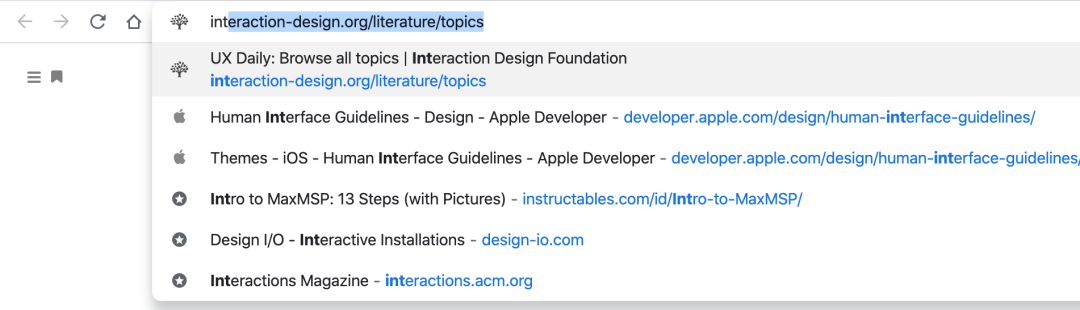
那就在浏览器地址栏直接输入网址吧。诶?这不是一个如假包换的「回忆」任务吗?为什么要选择这种方法呢?确实,我一直不太清楚这个网址到底是 interactiondesign 还是 interaction-design 还是 interaction-designs,也不记得后缀是 .org 还是 .net 还是 .com。但是感谢浏览器的历史记录,我并不需要记住这些——只需要在浏览器输入前三个字母 int,就可以从记录中选择这个链接打开,这是最省力的方式:
-
在浏览器中,识别并定位到地址输入框很容易,毕竟输入框只有 1 个;如果要从收藏夹中打开,我得回忆它可能在哪里
-
虽然不记得准确的网址,但是我记得它是交互设计主题的网站,网址一定以 interaction 开头
-
输入 int 三个字母,浏览历史就会显示完整的网址,只需要识别哪个是我想访问的
-
另外,我也不是靠识别 Interaction-design.org 这一长串字母来确定选择,而是识别网站前面那一棵小树图标,这个 favicon 我已经见过很多次了。还记得吗?识别图形比文字更快
这就是识别容易回忆难。我们总是能找到很多办法,用识别来替代回忆:地址栏的访问历史,把链接放在收藏夹最外层,或者设为浏览器默认打开页,设置打开快捷键,或者从某个网站(比如设计导航)的链接跳转过去……

还记得当年的 hao123.com 吗?它看起来确实没有什么设计感,但它是如假包换的好设计——它承载了多少网民(尤其是使用经验较少的人)的记忆负荷啊!在这里,只需要识别,不需要回忆。
保持一致性对识别来说非常重要。如果菜单项目会根据最近的选择而变化,就会带来问题,因为用户希望总是在一个地方找到它。想象一下,hao123 的链接顺序每天换一次,那些把它当作导航的用户,马上就会觉得自己迷失了方向,再也找不到去某些网站的路。
搜索引擎结果的一致性也很重要。人们不太可能记得在搜索结果列表中看过哪些内容,但是通常能识别出之前见过的结果列表。如果用户多次搜索同一个关键词,发现结果列表已经改变,就得从头开始查看每一条搜索结果。
在你的经验里,还有哪些用识别代替回忆的例子呢?
参考资料
[1]
Cabeza, R., Kapur, S., Craik, F. I. M., McIntosh, A. R., Houle, S., & Tulving, E. (1997). Functional Neuroanatomy of Recall and Recognition: A PET Study of Episodic Memory.:
Journal_of_Cognitive_Neuroscience,9(2),254–265.




