 「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
PaperWeekly 将于本周针对
机器翻译(NMT)
和
推荐系统
方向分别增设专题阅读小组, 在组内发起
「每周一起读」
活动。我们将每周选定一篇优质文章,并为大家提供可撰写读书笔记和在线协同讨论的阅读工具。
如果你也希望和我们一起培养良好的阅读习惯,在积极活跃的讨论氛围中增长姿势,就请留意下方的招募信息吧:)
A Deep Reinforced Model for Abstractive Summarization
Humh
问题:产生摘要有重复、不连贯;训练目标存在问题。
创新点: encoder 中 intra-temporal attention。 为了使我们的模型输出更连贯,我们允许解码器在生成新单词时回顾部分输入文档,这种技术称为时间注意(temporal attention)模型。与完全依赖自己的隐藏状态不同,解码器可以通过注意函数(attention function)整合不同部分的输入语境信息。调整注意函数,以确保模型在生成输出文本时使用不同部分的输入,从而增加摘要的信息覆盖度。 decoder 中 sequential intra-attention model。 另外,为了确保我们的模型不产生重复信息,我们还允许它回顾解码器之前的隐藏状态。用类似的方式,我们定义内部解码注意函数(intra-decoder attention function),它可以回顾解码器 RNN 之前的隐藏状态。 一种新的训练算法 。 结合极大似然代价函数和策略梯度强化学习来降低 exposure bias。
Ttssxuan
we hy-pothesize that it can assist our policy learning al-gorithm to generate more natural summaries.
请教一下,在其中 LOSS 的 rl 部分,前文有提到使用的是 reinforce learning,提供了一个 base hat y,不明白他的 reward 函数是如何定义的,如何判断 reward 高低呢?是依据是一段中提到的 ROUGE 标准中的 n-gram overlap between generate summary and a reference sequence 吗?那 reward 是不是直接使用 n-gram 去衡量生成的摘要?
Humh
:可以看下参考文献:Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. 2016. Self-critical sequence training for image captioning. arXiv preprint arXiv:1612.00563
kan_deng
:Reward 函数,文中说了,是比较 y^ 与 ground truth y* 之间的差距,然后把差距代入某个评测函数,来得到的。看本页前文我划的重点语句。
jysun
edtt′=hdtTWdattnhdt
个人感觉这一步 intra-attention 和 r-net 中的 self-matching 想法很相似,都是想要“往回看”,用当前时刻 decoder 状态和之前状态算 attention score,诉求应该是避开被多次 attend 的位置,捕捉更多信息吧?
kan_deng
:貌似目的不是为了捕捉更多信息,而是解决前文所说的问题: 在长文的摘要中,经常出现两个问题,1. unnatural summarisation, 2. repeated phrases.
xwzhong
:from 2.2: our decoder can still generate re-peated phrases base on its own hidden states, es-pecially when generating long sequences.
知识图谱
▼
R-NET: MACHINE READING COMPREHENSION WITH SELF-MATCHING NETWORKS
kaharjan
This paper proposed a gated attention-based network and self-matching mechanism. In the reading comprehension and question answering, there is phenomenon that only parts of passage are relevant to the question. The gated attention-based network effectively model this phenomenon. However, it has problem that it has very limited knowledge of context. Self-matching mechanism tackles this problem by directly matching the question-aware passage representation against itself. The experiment results outperform the stat-of-art methods.
huangchao
minimize the sum of the negative log probabilities of the ground truth startand end position by the predicted distributions
这里的优化目标没有明确写出来,请问该怎么理解?网络中的输出层是一个 pointer network,这个网络用来预测答案在 passage 中的起始位置,所以网络的输出应该是起始位置分别在 passage 中每个词处的概率,目标是要最小化这些概率的负对数的和?
rqyang
:如果明确写出来应该是这样:
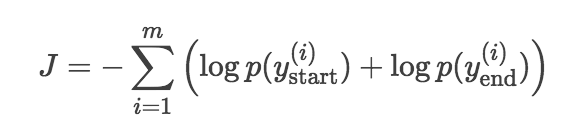
hanqichen
We use zero vectors torepresent all out-of-vocab words
想请教一下各位:在这里未登录词被初始化为零向量,在训练的时候是否会更新这部分词向量?另外除了初始化零向量之外,还有没有更好的对未登录词的处理方式?
huangchao
:前面一句有说是词向量在训练过程中是固定的,所以应该是不被更新档,未登录词应该也一样。虽然未登录词的词向量被初始化为了零向量,但是本文中对一个词的向量表示包括了 word-level embedding 和 character-level embedding 两个部分,在 character-level embedding 那一块应该是不全为 0 的,所以最终对一个词的向量表示也应该不是零向量,不同的未登录词的向量表示应该也是不一样的。文中在 3.1 节也提到了使用 character-level embedding 对处理未登录词的情况是比较有用的。
rqyang
:在 Dynamic Coattention Networks For Question Answering(DCN)那篇论文中,论文 4.1 节也采用了把未登录词的词向量设为 0 的做法,可是它没有 character level embedding 的补充,就很难理解如果遇见新实体该怎么办了。
GAN
▼
Adversarial Multi-task Learning for Text Classification
Ttssxuan
本论文使用 MTL 进行文本分类,具体实现是,使用 private-share 模式进行训练,private 抓取 task specified features,share 抓取 common features,但是存在一些情况会导致 private 和 share 不能完全区分,作者引入 gan 和 orthogonality constraints,gan 专注于抓取 task specified discriminator 不能区别的 common features,为了保证 common features 不同时出现在 private 和 share 中,使用 orthogonality contraints 去掉无用的 common features。
Mordekaiser
作者为解决目前多任务学习中存在的问题,设计了一个 shared-private learning framework. 其主要关键点就是引入了对抗训练以及正交约束,这样可以阻止 shared and private latent features from interfering with each other.
tommey
Multi-task learning is an effective approach toimprove the performance of a single task withthe help of other related tasks.
我感觉这里的 multi-task,应该说是 diverse-task。我理解中的 multi-task 应该像自然语言处理里面的 word segment, lemma, POS 等等。像本文中都是做 text classification,只是在不同的情况下。
karma
:赞同, 至少得做不同的 NLP 任务才能证明这种方法对提取 shared feature 有效。
KurtPan_USTC_KG
:"In the classification context, MTL aims to improve the performance of multiple classification tasks by learning them jointly. One situation where MTL may be particularly helpful is if the tasks share significant commonalitiesand are generally slightly under sampled." 我理解的 multi-task 正如本 paper 定義。您所說的 across-NLP-tasks-shared-feature 有沒有相關工作呢?
tommey
:
我感觉这不是个需要讨论的问题,因为本 paper 中的观点和您的观点,我并没有否定,只是说了一些其他的看法,个人感觉没有什么不妥当的。如果您觉得有不妥当,那我表示抱歉。 至于我举自然语言中多个任务的例子,只是佐证我自己的理解而已,并不是说有谁做了这样的工作,希望将来有吧。
QA
▼
Attention-over-Attention Neural Networks for Reading Comprehension
jueliangguke
感觉本文的 AoA 模型构思上是挺大胆的,看评论有人提到 BiDAF 那个模型。其实 BiDAF 还是在 compare-aggregate 框架下的,只不过因为 aggregate 过程只对 context 做,在 compare 过程中有所变化。attention 还是在 lstm 输出层上进行加权。本文的模型用 C2Q 的 attention 去对 Q2C 的 attention 加权,非常简洁直观地得到 context 上的相关性分布,计算量比 BiDAF 要小很多应该,而且没有用 character-level 的 embedding,按照 BiDAF 的 ablation 结果,AoA 在 CNN 数据集上和 BiDAF 应该差不多,所以真的不错。另外有两个思考,一是没有看到本文对 AoA 中间结果的一些展示,自己最开始看到这个模型,总觉得 attention 已经是近似的概率了,再用 attention 去对 attention 操作真的会有效吗,在小数据集上估计危险。二是 AoA 是否可以稍加改动,在 SQuAD 上跑一下看看结果?
Bruce
总结一下模型的做法吧,其实图 1 已经很清晰了。 首先数据的三元组是(D, Q, X)是(文档,问题,带填的词) 把 D 和 Q 做 embedding,两者做点积得到匹配评分矩阵(pair-wise matching score)M,而 M(i, j)M(i,j) 则表示 D 中第 i 个词和 Q 中第 j 个词之间的余弦相似度。 把 M 每行过 Softmax 求均值,得到列数长度的向量,称为 query-attention,相同地,每列过 Softmax ,和 query-attentino 做点积,得到最后的决策评分 s 最后从 D 中抽那个词当做答案,就是从 s 里去看这个词在 s 中的评分之和是多少。
huyingxi
Unlikethe previous works, our neural network model requires less pre-defined hyper-parameters anduses an elegant architecture for modeling.
很棒的想法,query_to_document attention 与 document_to_query attention 的结合,充分利用了 QA 的相关信息,计算量也不大。之前看过几篇貌似解决类似问题的斯坦福的论文(2016),都采用了一种模型:DMN(dynamic memory network),当时没怎么看明白,请问有人对这个模型了解吗?
jueliangguke
:这个模型(DMN)就是把所有 NLP 任务都转化为一个 QA 任务,记得有论断说,解决了 QA 所有 NLP 任务就都解决了,所以也都是合理的。个人感觉模型类似于 N2N memory network。episodic 就是 hop。不过对 memory 用了 RNN 来建模。比较感兴趣的是这个模型可应用范围比较广。
Chatbot
▼
Sequential Match Network: A New Architecture for Multi-turn Response Selection in Retrieval-based Chatbots
cuixiankun
论文提出了一个基于检索的多轮闲聊架构,闲聊模型一般分为生成模型和检索模型,目前关于检索模型的闲聊还停留在单轮对话中,本文提出了基于检索的多轮对话闲聊。 多轮对话不仅要考虑当前的问题,也要考虑前几轮的对话情景。
多轮对话的难点主要有两点:1.如何明确上下文的关键信息(关键词,关键短语或关键句)。 2.在上下文中如何模拟多轮对话间的关系。
现有检索模型的缺陷:在上下文中容易丢失重要信息,因为它们首先将整个上下文表示为向量,然后将该上下文向量与响应 sentence 向量进行匹配。 为了避免信息丢失,SMN 在开始时将候选回复 sentence 与上下文中的每条语句进行匹配,并将匹配的每对中重要信息编码入匹配向量(注:这是 CNN 阶段,解决上上述难点1);然后按照话语的时间顺序,对匹配向量进行堆积,以对其关系进行建模(注:即构建 GRU2,解决上述难点 2)。 最后的匹配阶段就是计算这些堆积的匹配向量。
具体流程说: 1、首先通过 tf-idf 抽取出前 n-1 轮的关键词,通过关键词检索出候选 responses 2、将每条 response 和 utterance 的每条 sentence 做匹配:通过模型 GRU1 分别构造 word2word 和 sentence2sentence 的向量矩阵。这两个矩阵会在 word 级别和 segment 级别获取重要的匹配信息。 3、获取到的两个矩阵通过连续的 convolution 和 pooling 操作得到一个 matching vector。通过这种方式,可以将上下文进行多个粒度级别的 supervision 识别并获取重要信息,再通过最小损失 matching 计算。 4、获取到的 matching vector 再通过 GRU2 计算得到 context 和 response 的分数。
xwzhong
paper的摘要提到,基于检索的方式多轮会话中,所得到的回复忽略了与之前会话内容之间的“关系”以及各自的“重要性”。“关系”体现在,给出正确的回复时,之前的会话彼此之间的关系;而重要性则提现在,正确的回复与之前对话之间的关系。作者提出的解决思路如下:
1. “重要性”-a.以词来衡量;回复和每一个utterance的词转化为embedding后,计算两两词之间的相似度,得到矩阵A。b.以句来衡量。回复(utterance亦同)使用GRU encode,每个step的hidden state与每个utterance所有hidden state计算一个相似度。得到矩阵B。
2. 对1中得到的2-D矩阵(A、B)使用CNN降维,得到n个m维的向量(n为之前的会话轮数)
3. “关系”。使用GRU(n个m维的input)来描述赋予“重要性”后的会话关系。 comment: 在描述“关系”中,作者使用了三种不同的方法进行比较,这种比较方式可取。
MH233
3.3 Utterance-Response Matching
这里计算句子之间的相似度,先计算了两句话每个 word 之间的相似度(类似于 cosine similarity 的概念),再计算句子之间的相似度,这里采取的策略应该是叫 Bilinear 吧?还有一种叫做 Tensor 的相似度计算方法(https://arxiv.org/abs/1511.08277 ),一直解释不清楚两个指标的物理含义。 另,在得到相似度矩阵之后,使用了 CNN 结构进行特征提取,这样和直接进行 k-max pooling 相比有什么不同和优势?
wumark
:是的,这个是 bilinear 的相似度计算。bilinear 的物理含义你可以理解为,x 和 y 不在一个空间,我们首先需要两个空间的变换矩阵 W,让 x 变到 y 的空间,之后再在同一个空间做 dot。tensor 我认为是 bilinear 的一个扩展,bilinear 只会给 x,y 计算出一个实数值,而 tensor 可以给 x,y 计算出一个相似度向量。tensor 需要更多的参数,更大的计算量,往往 tensor 会比 bilinear 取得更好一些的效果。在这个任务下,CNN 比单做 k-max pooling 是要好的,我做过这个实验。可能是因为 CNN 可以考虑到相邻词的信息吧。k-max pooling 在输入是 GRU 产出 hidden state 乘出来的相似度矩阵时候经常会有一些不太好的结果,例如 美丽 的,如果你求 k-max 很有可能美丽和的都取出来了,因为“的"完全承袭了美丽的 hidden state。不过我没有尝试过在 convolution 之后用 k-max pooling,我觉得可能会让效果更好。
1. 参与者需具备小组专题方向的
研究背景
,目前开放申请的阅读小组有
「机器翻译」、
「推荐系统」、
「QA」、
「知识图谱」、「多模态」、「GAN」和「Chatbot」
。
2.
点击本文底部的
「阅读原文」
提交内测申请
,我们将在 48 小时内完成审核并和您取得联系
。
关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击
「交流群」
,小助手将把你带入PaperWeekly的交流群里。






