
图:pixabay
原文来源:hackernoon
作者:AndreyNikishaev
「机器人圈」编译:嗯~阿童木呀、多啦A亮
 在计算机领域,即使是对业界专家来说,调试神经网络也是一项艰巨的任务。数百万个参数混杂在一起,即使是一个小小的变化却可以将你所有的努力付之一炬。如果没有调试和可视化,你的所有行动都只不过是将一个硬币弹出,却没有入罐,更糟糕的是它会浪费你的时间。在本文中我收集了一些方法,以帮助你能够尽快找到问题所在并将其加以解决。
在计算机领域,即使是对业界专家来说,调试神经网络也是一项艰巨的任务。数百万个参数混杂在一起,即使是一个小小的变化却可以将你所有的努力付之一炬。如果没有调试和可视化,你的所有行动都只不过是将一个硬币弹出,却没有入罐,更糟糕的是它会浪费你的时间。在本文中我收集了一些方法,以帮助你能够尽快找到问题所在并将其加以解决。
尝试用小型数据集对你的模型进行过度拟合
一般来说,神经网络应该在数百次迭代中使你的数据过度拟合。如果在这过程中你的损失没有降低,那你的问题就更严重了。
使用迭代逻辑来解决问题
尝试构建最简单的网络,以解决你的主要问题,然后逐步延伸到全局问题。例如,如果你正在创建风格迁移网络,请尝试首先训练你的脚本以便在一个图像上进行风格迁移。如果它表现良好的话,接下来你要做的就是创建可以将风格迁移到任何图像的模型。
使用适度失真数据集
例如,如果你想训练网络以对数据进行分类,那么你的训练数据应该在每个类中都具有相同数量的输入。而在其他情况下,就有可能会出现类中过度拟合的问题。神经网络并不是对于所有的失真都是不变的,而你需要基于此专门对它们进行训练。因此,输入失真会提高网络的精确度。
网络容量VS数据集大小
你的数据集应该足以让网络学习。如果你具有小数据集和大网络,那么它将停止学习(在某些情况下,这将导致大量不同输入的结果相同)。如果你具有大数据集和小网络,那么你会看到损失跳跃的情况,导致网络容量不能存储如此多的信息。
使用平均中心化
这将从你的网络中移除噪音数据,提高训练效果,并且在某些情况下还有助于解决NaN(无穷与非数值)问题。但请记住,如果你有时间序列数据,那么你应该使用批处理中心化而不是全局。
首先尝试更为简单的模型
我看到很多种情况,比如有很多人在第一次尝试使用网络时便使用诸如ResNet-50,VGG19等这样的标准大型网络,但是到后来发现,其实他们的问题使用仅有几层的网络便可以解决。所以如果你没有标准的大问题,你可以首先从小型网络开始。你添加的东西越多,就越难以训练模型以解决你的问题,所以从小型网络开始也往往会节省很多时间。不过你还应该记住,大型网络会消耗大量内存、增添大量操作。
可视化是必须的
如果你现在使用的是Tensorflow,那么一定要开始使用Tensorboard。如果没有的话,请尝试为你的框架找到一些可视化工具,或者自己动手编写。因为这将有助于你在早期训练阶段就找到所存在的问题。你应该明确看到的事情包括以下几种:损失、权重直方图、变量和梯度。如果你处理的是计算机视觉(CV),那么你需要始终可视化过滤器以了解网络正在看到的内容。
权重初始化
如果你不正确地设置权重,那么你的网络很有可能因为零梯度或对所有神经元的类似更新而变得不可训练。此外,你还应该记住,权重是与学习率相结合的,因此大的学习率和大的权重可能导致NaN问题。
对于小型网络来说,使用一些高斯分布initializer就足够了。
对于深度网络来说,这些就没那么有效了,因为你的权重可能会多次相乘,从而导致产生一个非常小的数字,而这几乎可以消除反向传播过程中的梯度。而现在,得益于Ioffe和Szegedy,我们拥有了批量归一化(,从而减轻了许多不必要的麻烦。
标准问题使用标准网络
有很多预训练模型(1)(https://github.com/tensorflow/models)(2)(https://github.com/tensorflow/models/tree/master/slim#Pretrained),你可以马上使用。在某些情况下,你可以立即使用它们,也可以使用微调技术,节省训练时间。主要思想是,大多数网络容量对于不同的问题是一样的。例如,如果我们谈论的计算机视觉相比第一层网络将包括简单的过滤器,如线条、点、角度与所有图像相同,那么你不需要重新训练它。
使用学习率衰减
这几乎总是会给你一个极大的推动力。Tensorflow有很多不同的衰减调度器。
使用Grid Search 、Random Search 或 Config file调整超参数
不要手动检查所有参数,这是非常耗时且无效的。我通常对所有参数使用全局配置,运行检查结果后,我将明确在哪个方向再做进一步调查。如果这种方法对你没有帮助,那么你可以使用Random Search或 Grid Search。

1、梯度消失的问题
一些激活函数,例如Sigmoid和Tanh存在饱和的问题。在他们极限的导数接近零时,将损坏梯度和学习过程。所以查看不同的函数是很好的方法。现在标准的激活函数是ReLU。此外,这个问题也可能出现在非常深层次或复杂的网络中,例如,如果你有150层,并且所有的激活都会产生结果0.9,那么0.9^500 = 0.000000137。但是正如我上面所说的,批量归一化将有助于这个和残差层。
2、非零中心激活
例如Sigmoid、ReLU函数不以零为中心。这意味着在训练期间,所有的梯度都将是正数或负数,将导致学习过程中的问题。这也是为什么我们使用以零为中心输入数据的原因。
3、ReLU失效
标准的ReLU函数也不是完美的。对于负数ReLU给0的问题,这意味着它们不会被激活,因此你的神经元的一部分将会失效,再也不会被使用。这可能发生的原因是学习率大和权重初始化错误。如果参数调整不能帮助你,你尝试没有这些问题的Leaky ReLU、PReLU、ELU或Maxout。
4、梯度爆炸
除了每一步梯度变得越来越大,爆炸问题与消失问题是一样的。其中一个主要修复办法是使用梯度剪裁,基本决定了梯度的硬性限制。
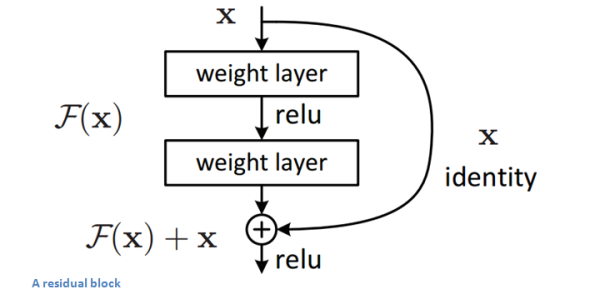
深层网络的精度退化
从一些点开始,真正深度的网络开始表现得像一部坏手机。因此,增加更多的层会降低网络精度。为了解决这个问题,我们使用通过所有图层输入的一部分输入的残差层——图像瓶颈残差层(bottleneck residual layer)。
回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
 点击下图加入
点击下图加入

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册




